









It was two days back when the Blizzard team announced an update about the demo of the progress made by Google’s DeepMind AI at StarCraft II, a real-time strategy video game. The demo was presented yesterday over a live stream where it showed, AlphaStar, DeepMind’s StarCraft II AI program, beating the top two professional StarCraft II players, TLO and MaNa.
The demo presented a series of five separate test matches that were held earlier on 19 December, against Team Liquid’s Grzegorz “MaNa” Komincz, and Dario “TLO” Wünsch. AlphaStar beat the two professional players, managing to score 10-0 in total (5-0 against each). After the 10 straight wins, AlphaStar finally got beaten by MaNa in a live match streamed by Blizzard and DeepMind.
To people saying Mana didn't play well, trust me it's very difficult playing against an opponent like alphastar that plays completely different than a human and that you have no previous experience with. Alphastar is extremely impressive and imo unprecedented in gaming AI.
— Dario (@LiquidTLO) January 24, 2019
GG @DeepMindAI thank you for letting me be the face of @StarCraft for a moment!
— Grzegorz Komincz (@Liquid_MaNa) January 24, 2019
How does AlphaStar learn?
AlphaStar learns by imitating the basic micro and macro-strategies used by players on the StarCraft ladder. A neural network was trained initially using supervised learning from anonymised human games released by Blizzard. This initial AI agent managed to defeat the “Elite” level AI in 95% of games.
Once the agents get trained from human game replays, they’re then trained against other competitors in the “AlphaStar league”. This is where a multi-agent reinforcement learning process starts. New competitors are added to the league (branched from existing competitors). Each of these agents then learns from games against other competitors. This ensures that each competitor performs well against the strongest strategies, and does not forget how to defeat earlier ones.
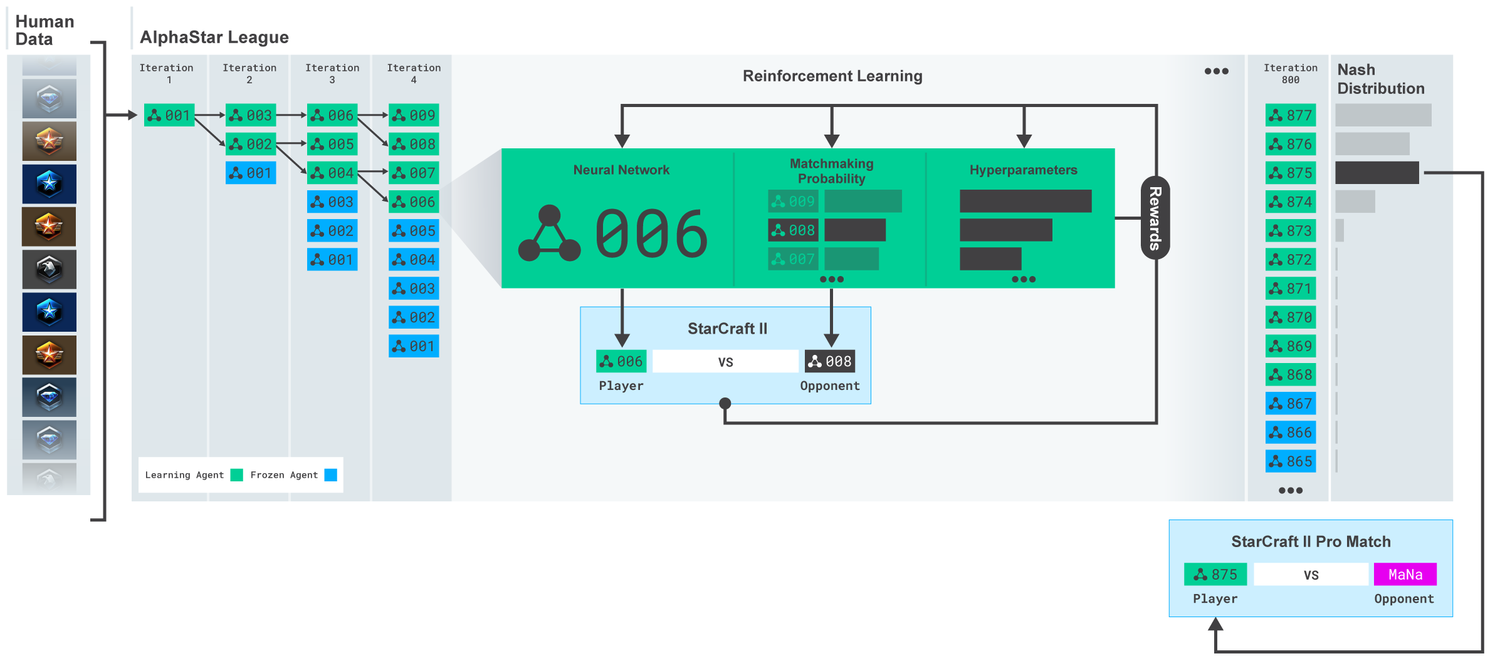
As the league continues to progress, new counter-strategies emerge, that can defeat the earlier strategies. Also, each agent has its own learning objective which gets adapted during the training. One agent might have an objective to beat one specific competitor, while another one might want to beat a whole distribution of competitors. So, the neural network weights of each agent get updated using reinforcement learning, from its games against competitors. This helps optimise their personal learning objective.
How does AlphaStar play the game?
TLO and MaNa, professional StarCraft players, can issue hundreds of actions per minute (APM) on average. AlphaStar had an average APM of around 280 in its games against TLO and MaNa, which is significantly lower than the professional players. This is because AlphaStar starts its learning using replays and thereby mimics the way humans play the game. Moreover, AlphaStar also showed the delay between observation and action of 350ms on average.
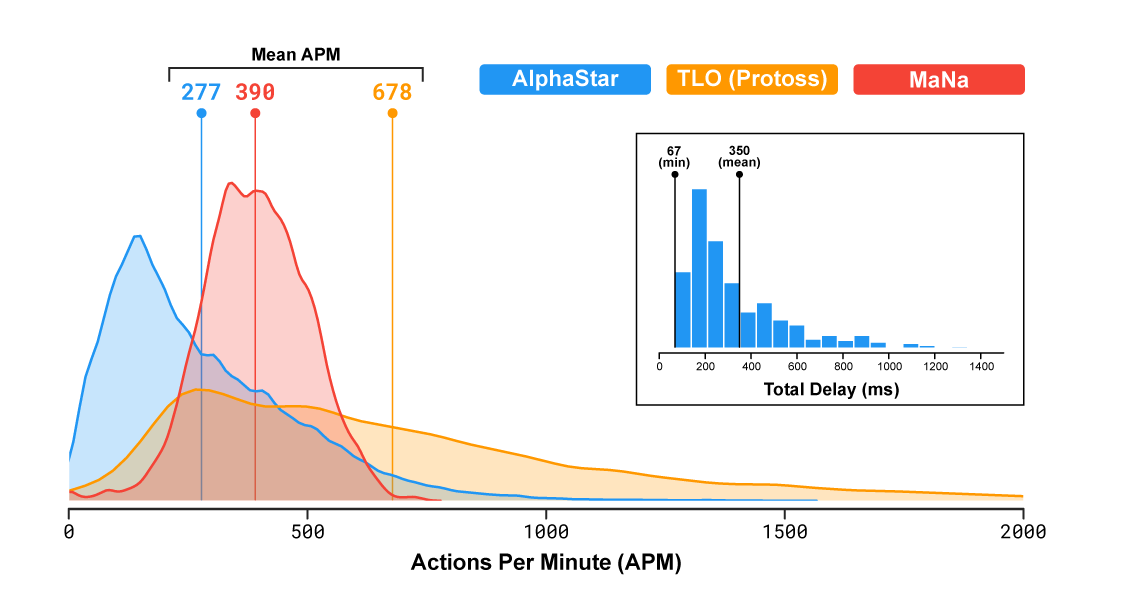
AlphaStar might have had a slight advantage over the human players as it interacted with the StarCraft game engine directly via its raw interface. What this means is that it could observe the attributes of its own as well as its opponent’s visible units on the map directly, basically getting a zoomed out view of the game. Human players, however, have to split their time and attention to decide where to focus the camera on the map.
But, the analysis results of the game showed that the AI agents “switched context” about 30 times per minute, akin to MaNa or TLO. This proves that AlphaStar’s success against MaNa and TLO is due to its superior macro and micro-strategic decision-making. It isn’t the superior click-rate, faster reaction times, or the raw interface, that made the AI win.
MaNa managed to beat AlphaStar in one match
DeepMind also developed a second version of AlphaStar, which played like human players, meaning that it had to choose when and where to move the camera. Two new agents were trained, one that used the raw interface and the other that learned to control the camera, against the AlphaStar league.
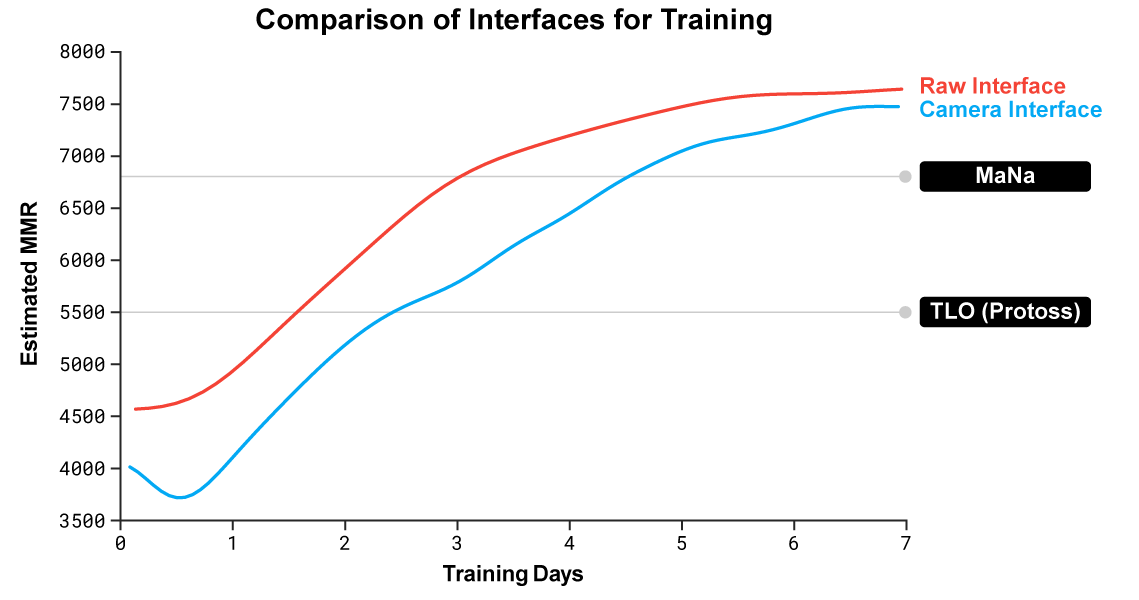
“The version of AlphaStar using the camera interface was almost as strong as the raw interface, exceeding 7000 MMR on our internal leaderboard”, states the DeepMind team. But, the team didn’t get the chance to test the AI against a human pro prior to the live stream.
In a live exhibition match, MaNa managed to defeat the new version of AlphaStar using the camera interface, which was trained for only 7 days. “We hope to evaluate a fully trained instance of the camera interface in the near future”, says the team.
DeepMind team states AlphaStar’s performance was initially tested against TLO, where it won the match. “I was surprised by how strong the agent was..(it) takes well-known strategies..I hadn’t thought of before, which means there may still be new ways of playing the game that we haven’t fully explored yet,” said TLO.
The agents were then trained for an extra one week, after which they played against MaNa. AlphaStar again won the game. “I was impressed to see AlphaStar pull off advanced moves and different strategies across almost every game, using a very human style of gameplay I wouldn’t have expected..this has put the game in a whole new light for me. We’re all excited to see what comes next,” said MaNa.
Public reaction to the news is very positive, with people congratulating the DeepMind team for AlphaStar’s win:
Congratulations @DeepMindAI . I am amazed. 3 years ago I bet that by 2021, AI would still not compete with pros at SC2. Today I lost that bet pretty badly… Maybe it's time to do a Bayesian update on my beliefs… #AlphaStar
— Sebastien Bubeck (@SebastienBubeck) January 24, 2019
Congrats to @OriolVinyalsML, David Silver and the many others at @DeepMindAI for putting together #AlphaStar. And to @LiquidTLO and @Liquid_MaNa for some great play. GG! 🕹️
— Kaixhin (@KaiLashArul) January 24, 2019
Congrats to AlphaStar team. I'm glad we got to see an example of the exploitability of the AlphaStar strategy in the exhibition game. My gut feeling is that it wasn't fundamentally (just) about camera vs global view. I would love to see how p(win) changed during the game.
— Ferenc Huszár🇪🇺 (@fhuszar) January 24, 2019
Can we please have a 24/7 stream of #AlphaStar laddering?
More importantly, can we rename AlphaStar to Feardragon?
— Tabin Ahmad (@panicsw1tched) January 24, 2019
AlphaStar learned humans replays, we will now learn of AlphaStar's replays.
This is crazy but frightening in the same time.
— Denversc2 (@Denver_sc2) January 24, 2019
To learn about the strategies developed by AlphaStar, check out the complete set of replays of AlphaStar’s matches against TLO and MaNa on DeepMind’s website.
Read Next
Best game engines for Artificial Intelligence game development
Deepmind’s AlphaZero shows unprecedented growth in AI, masters 3 different games


")