









One of the things that I really love about the tech industry is how often different terms – buzzwords especially – can cause confusion. It isn’t hard to see this in the wild. Quora is replete with confused people asking about the difference between a ‘developer’ and an ‘engineer’ and how ‘infrastructure’ is different from ‘architecture’. One of the biggest points of confusion is the difference between data science and machine learning. Both terms refer to different but related domains – given their popularity it isn’t hard to see how some people might be a little perplexed.
This might seem like a purely semantic problem, but in the context of people’s careers, as they make decisions about the resources they use and the courses they pay for, the distinction becomes much more important. Indeed, it can be perplexing for developers thinking about their career – with machine learning engineer starting to appear across job boards, it’s not always clear where that role begins and ‘data scientist’ begins.
Tl;dr: To put it simply – and if you can’t be bothered to read further – data science is a discipline or job role that’s all about answering business questions through data. Machine learning, meanwhile, is a technique that can be used to analyze or organize data. So, data scientists might well use machine learning to find something out, but it would only be one aspect of their job.
But what are the implications of this distinction between machine learning and data science? What can the relationship between the two terms tell us about how technology trends evolve? And how can it help us better understand them both?
Read next: 9 data science myths debunked
What’s causing confusion about the difference between machine learning and data science?
The data science v machine learning confusion comes from the fact that both terms have a significant grip on the collective imagination of the tech and business world.
Back in 2012 the Harvard Business Review declared data scientist to be the ‘sexiest job of the 21st century’. This was before the machine learning and artificial intelligence boom, but it’s the point we need to go back to understand how data has shaped the tech industry as we know it today.
Data science v machine learning on Google Trends
Take a look at this Google trends graph:
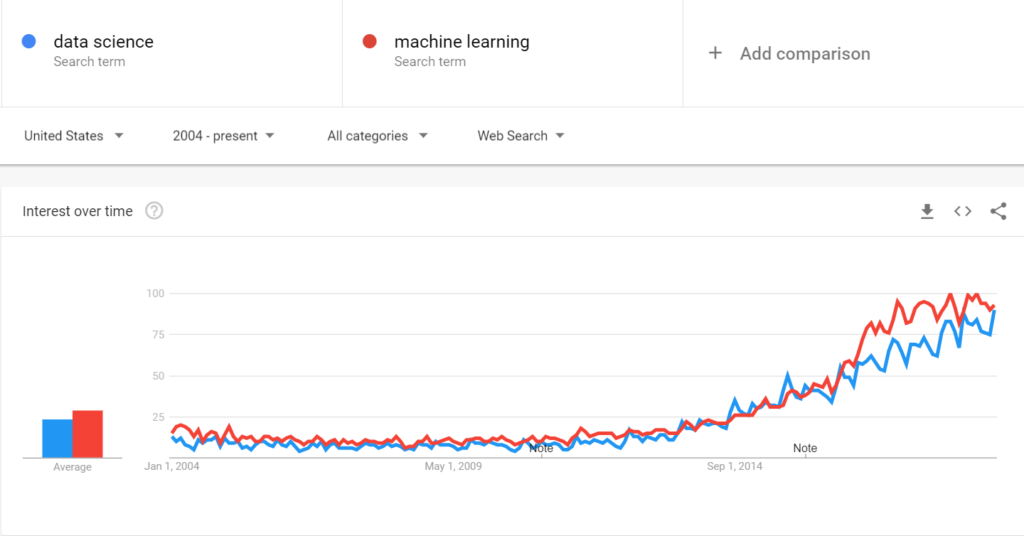
Both terms broadly received a similar level of interest. ‘Machine learning’ was slightly higher throughout the noughties and a larger gap has emerged more recently.
However, despite that, it’s worth looking at the period around 2014 when ‘data science’ managed to eclipse machine learning. Today, that feels remarkable given how machine learning is a term that’s extended out into popular consciousness. It suggests that the HBR article was incredibly timely, identifying the emergence of the field.
But more importantly, it’s worth noting that this spike for ‘data science’ comes at the time that both terms surge in popularity. So, although machine learning eventually wins out, ‘data science’ was becoming particularly important at a time when these twin trends were starting to grow.
This is interesting, and it’s contrary to what I’d expect.
Typically, I’d imagine the more technical term to take precedence over a more conceptual field: a technical trend emerges, for a more abstract concept to gain traction afterwards. But here the concept – the discipline – spikes just at the point before machine learning can properly take off. This suggests that the evolution and growth of machine learning begins with the foundations of data science.
This is important. It highlights that the obsession with data science – which might well have seemed somewhat self-indulgent – was, in fact, an integral step for business to properly make sense of what the ‘big data revolution’ (a phrase that sounds eighty years old) meant in practice.
Insofar as ‘data science’ is a term that really just refers to a role that’s performed, it’s growth was ultimately evidence of a space being carved out inside modern businesses that gave a domain expert the freedom to explore and invent in the service of business objectives.
If that was the baseline, then the continued rise of machine learning feels inevitable. From being contained in computer science departments in academia, and then spreading into business thanks to the emergence of the data scientist job role, we then started to see a whole suite of tools and use cases that were about much more than analytics and insight.
Machine learning became a practical tool that had practical applications everywhere. From cybersecurity to mobile applications, from marketing to accounting, machine learning couldn’t be contained within the data science discipline. This wasn’t just a conceptual point – practically speaking, a data scientist simply couldn’t provide support to all the different ways in which business functions wanted to use machine learning.
So, the confusion around the relationship between machine learning and data science stems from the fact that the two trends go hand in hand – or at least they used to. To properly understand how they’re different, let’s look at what a data scientist actually does.
Read next: Data science for non-techies: How I got started (Part 1)
What is data science, exactly?
I know you’re not supposed to use Wikipedia as a reference, but the opening sentence in the entry for ‘data science’ is instructive: “Data science is a multi-disciplinary field that uses scientific methods, processes, algorithms and systems to extract knowledge and insights from structured and unstructured data.”
The word that deserves your attention is multi-disciplinary as this underlines what makes data science unique and why it stands outside of the more specific taxonomy of machine learning terms. Essentially, it’s a human activity as much as a technical one – it’s about arranging, organizing, interpreting, and communicating data.
To a certain extent it shares a common thread of DNA with statistics. But although Nate Silver said that ‘data scientist’ was “a sexed up term for statistician”, I think there are some important distinctions. To do data science well you need to be deeply engaged with how your work integrates with the wider business strategy and processes. The term ‘statistics’ – like ‘machine learning’ – doesn’t quite do this.
Indeed, to a certain extent this has made data science a challenging field to work in. It isn’t hard to find evidence that data scientists are trying to leave their jobs, frustrated with how their roles are being used and how they integrate into existing organisational structures.
How do data scientists use machine learning?
As a data scientist, your job is to answer questions. These are questions like:
- What might happen if we change the price of a product in this way?
- What do our customers think of our products?
- How often do customers purchase products?
- How are customers using our products?
- How can we understand the existing market? How might we tackle it?
- Where could we improve efficiencies in our processes?
That’s just a small set. The types of questions data scientists will be tackling will vary depending on the industry, their company – everything. Every data science job is unique.
But whatever questions data scientists are asking, it’s likely that at some point they’ll be using machine learning. Whether it’s to analyze customer sentiment (grouping and sorting) or predicting outcomes, a data scientist will have a number of algorithms up their proverbial sleeves ready to tackle whatever the business throws at them.
Machine learning beyond data science
The machine learning revolution might have started in data science, but it has rapidly expanded far beyond that strict discipline. Indeed, one of the reasons that some people are confused about the relationship between the two concepts is because machine learning is today touching just about everything, like water spilling out of its neat data science container.
Machine learning is for everyone
Machine learning is being used in everything from mobile apps to cybersecurity. And although data scientists might sometimes play a part in these domains, we’re also seeing subject specific developers and engineers taking more responsibility for how machine learning is used.
One of the reasons for this is, as I mentioned earlier, the fact that a data scientist – or even a couple of them – can’t do all the things that a business might want them to when it comes to machine learning. But another is the fact that machine learning is getting easier. You no longer need to be an expert to employ machine learning algorithms – instead, you need to have the confidence and foundational knowledge to use existing machine learning tools and products.
This ‘productization’ of machine learning is arguably what’s having the biggest impact on how we understand the topic. It’s even shrinking data science, making it a more specific role. That might sound like data science is less important today than it was in 2014, but it can only be a good thing for data scientists – it means they are being asked to spread themselves so thinly.
So, if you’ve been googling ‘data science v machine learning’, you now know the answer. The two terms are distinct but they both come out of the ‘big data revolution’ which we’re still living through.
Both trends and terms are likely to evolve in the future, but they’re certainly not going to disappear – as the data at our disposal grow, making effective use of it is only going to become more important.




