









A group of researchers from Google AI and Carnegie Mellon University announced the details regarding their newly proposed architecture, called, Transformer-XL (extra long), yesterday. It’s aimed at improving natural language understanding beyond a fixed-length context with higher self-attention. Fixed-length context is a long text sequence truncated into fixed-length segments of a few hundred characters.
Researchers have used two methods to quantitatively study the effective lengths of Transformer-XL and the baselines, namely, segment-level recurrence mechanism and a relative positional encoding scheme. Let’s have a look at these key techniques in detail.
Segment-level recurrence
Recurrence mechanism helps address the limitations of using a fixed-length context. During the training process, the hidden state sequences computed in the previous segment are fixed and cached. These are then reused as an extended context once the model starts processing the next new segment.
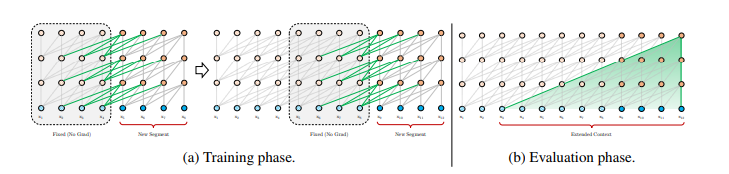
This connection then further increases the largest possible dependency length by N times (N being the depth of the network) as contextual information can flow across segment boundaries. The recurrence mechanism also resolves the context fragmentation issue. Moreover, with the help of recurrence mechanism applied to every two consecutive segments of a corpus, a segment-level recurrence is created in the hidden states. This, in turn, helps with effective context being utilized beyond the two segments.
Apart from being able to achieve extra long context and resolving the fragmentation issue, recurrence mechanism also helps with significantly faster evaluation.
Relative Positional Encodings
Although the segment-level recurrence technique is effective, there is a technical challenge that involves reusing the hidden states. The challenge is to keep the positional information coherent while reusing the states. Applying segment-level recurrence does not work in this case does not work as the positional encodings are not coherent when reusing the previous segments.
This is where the relative positional encoding scheme comes into the picture to make the recurrence mechanism possible. The relative positional encodings make use of fixed embeddings with learnable transformations instead of learnable embeddings. This makes it more generalizable to longer sequences at test time. The core idea behind the technique is to only encode the relative positional information in the hidden states.
“Our formulation uses fixed embeddings with learnable transformations instead of learnable embeddings and thus is more generalizable to longer sequences at test time”, state the researchers. With both the approaches combined, Transformer-XL has a much longer effective context and is able to process the elements in a new segment without any recomputation.
Results
Transformer-XL obtains new results on a variety of major language modeling (LM) benchmarks. It is the first self-attention model that is able to achieve better results than RNNs on both character-level and word-level language modeling. It is able to model longer-term dependency than RNNs and Transformer.
Transformer-XL has the following three benefits:
- Transformer-XL dependency is about 80% longer than RNNs and 450% longer than vanilla Transformers.
- Transformer-XL is up to 1,800+ times faster than a vanilla Transformer during evaluation of language modeling tasks as no re-computation is needed.
- Transformer-XL has better performance in perplexity on long sequences due to long-term dependency modeling, and on short sequences by resolving the context fragmentation problem.
For more information, check out the official Transformer XL research paper.
Read Next
Researchers introduce a machine learning model where the learning cannot be proved
Researchers design ‘AnonPrint’ for safer QR-code mobile payment: ACSC 2018 Conference