









It’s no surprise that cybersecurity has become a major priority for global businesses of all sizes, often employing a dedicated IT team to focus on thwarting attacks. Huge budgets are spent on acquiring and integrating security solutions, but one of the most effective tools might be hiding in plain sight. Encouraging your own engineers and developers to purposely break systems through a process known as chaos engineering can drive a huge return on investment by identifying unknown weaknesses in your digital architecture. As modern networks become more complex with a vastly larger threat surface, stopping break-ins before they happen takes on even greater importance.
Evolution of Cyberattacks
Hackers typically have a background in software engineering and actually run their criminal enterprises in cycles that are similar to what happens in the development world. That means these criminals focus on iterations and agile changes to keep themselves one step ahead of security tools.
Most hackers are focused on financial gains and look to steal data from enterprise or government systems for the purpose of selling it on the Dark Web. However, there is a demographic of cybercriminals focused on simply causing the most damage to certain organizations that they have targeted.
In both scenarios, the hacker will first need to find a way to enter the perimeter of the network, either physically or digitally. Many cybercrimes now start with what’s known as social engineering, where a hacker convinces an internal employee to divulge information that allows unauthorized access to take place.
Principles of Chaos Engineering
So how can you predict cyberattacks and stop hackers before they infiltrate your systems? That’s where chaos engineering can help. The term first gained popularity a decade ago when Netflix created a tool called Chaos Monkey that would randomly take a node of their network offline to force teams to react accordingly. This proved effective because Netflix learned how to better keep their streaming service online and reduce dependencies between cloud servers.
The Chaos Monkey tool can be seen as an example of a much broader practice: Chaos Engineering. The central insight of this form of testing is that, regardless of how all-encompassing your test suite is, as soon as your code is running on enough machines, errors are going to occur. In large, complex systems, it is essentially impossible to predict where these points of failure are going to occur. Rather than viewing this as a problem, chaos engineering sees it as an opportunity. Since failure is unavoidable, why not deliberately introduce it, and then attempt to solve randomly generated errors, in order to ensure your systems and processes can deal with the failure?
For example, Netflix runs on AWS, but in response to frequent regional failures have changed their systems to become region agnostic. They have tested that this works using chaos engineering: they regularly take down important services in separate regions via a “chaos monkey” which randomly selects servers to take down, and challenges engineers to work around these failures.
Though Netflix popularized the concept, chaos engineering, and testing is now used by many other companies, including Microsoft. The rise of cloud computing has meant that a high proportion of the systems running today have a similar level of complexity to Netflix’s server architecture. The cloud computing model has added a high level of complexity to online systems and the practice of chaos engineering will help to manage that over time, especially when it comes to cybersecurity. It’s impossible to predict how and when a hacker will execute an attack, but chaos tests can help you be more proactive in patching your internal vulnerabilities.
At first, your developers may be reluctant to jump into chaos activities since they will think their normal process works. However, there’s a good chance that, over time, they will grow to love chaos testing. You might have to do some convincing in the beginning, though, because this new approach likely goes against everything they’ve been taught about securing a network.
Designing a Chaos Test
Chaos tests need to be run in a controlled manner in order to be effective, and in many ways, the process lines up with the scientific method: in order to run a successful chaos test, you first need to identify a well-formed and refutable hypothesis. A test can then be designed that will prove (or more likely falsify) your hypothesis.
For example, you might want to know how your network will react if one DNS server drops offline during a distributed denial of service (DDoS) attack by a hacker. This tactic of masking one’s IP address and overloading a website’s server can be executed through a VPN. Your hypothesis, in this case, is that you will be able to re-route traffic around the affected server.
From there, you can begin designing and scheduling the experiment. If you are new to chaos engineering, you will want to restrict the test to a testing or staging environment to minimize the impact on live systems. Then make sure you have one person responsible for documenting the outcomes as the experiment begins.
If you identify an issue during the first run of the chaos test, then you can pause that effort and focus on coming up with a solution plan. If not, expand the radius of the experiment until it produces worthwhile results. Running through this type of fire drill can be positive for various groups within a software organization, as it will provide practice for real incidents.
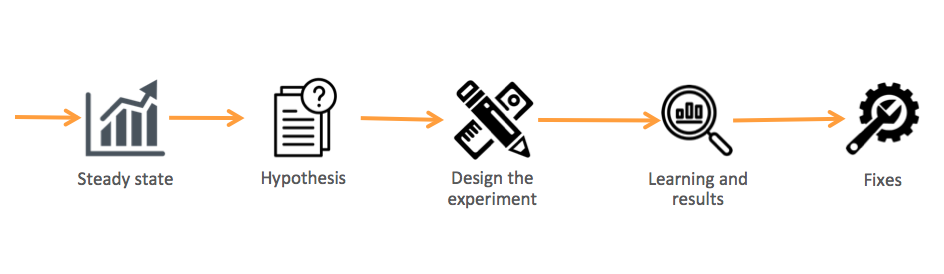
Source: Medium
How Chaos Engineering Fits Into Quality Assurance
A lot of companies hear about chaos engineering and jump into it full-speed. But then over time they lose their enthusiasm for the practice or get distracted with other projects. So how should chaos tests be run and how do you ensure that they remain consistent and valuable?
First, define the role of chaos engineering within your larger quality assurance efforts. In fact, your QA team may want to be the leaders of all chaos tests that are run. One important clarification is to distinguish between penetration tests and chaos tests. They both have the same goal of proactively finding system issues, but a penetration test is a specific event with a finite focus while chaos testing must be more open-ended.
When teaching your teams about chaos engineering, it’s vital to frame it as a practice and not a one-time activity. Return on investment will be hard to find if you do not systematically follow-up after chaos tests are run. The aim should be for continuous improvement to ensure your systems are prepared for any type of cyberattack.
Final Thoughts
These days, security vendors offer a wide range of tools designed to help companies protect their people, data, and infrastructure. Solutions like firewalls and virus scanners are certainly deployed to great success as part of most cybersecurity strategies, but they should never be treated as foolproof. Hackers are notorious at finding ways to get past these types of tools and exploit companies who are not prepared at a deeper level.
The most mature organizations go one step further and find ways to proactively locate their own weaknesses before an outsider can expose them. Chaos engineering is a great way to accomplish this, as it encourages developers to look for gaps and bugs that they might not stumble upon normally. No matter how much planning goes into a system’s architecture, unforeseen issues still come up, and hackers are a very dangerous variable in that equation.
Author Bio

Sam Bocetta is a freelance journalist specializing in U.S. diplomacy and national security, with emphasis on technology trends in cyberwarfare, cyberdefense, and cryptography.


 from Kali Linux")