









On Tuesday, Adam Gaier, a student researcher and David Ha, Staff Research Scientist at the Google research team published a paper on Weight Agnostic Neural Networks (WANN) that can perform tasks even without learning the weight parameters.
In “Weight Agnostic Neural Networks”, researchers present their first step towards searching networks with the neural net architectures that can already perform tasks, even when they use a random shared weight. The team writes, “Our motivation in this work is to question to what extent neural network architectures alone, without learning any weight parameters, can encode solutions for a given task. By exploring such neural network architectures, we present agents that can already perform well in their environment without the need to learn weight parameters.”
The team looked at analogies of nature vs. nurture. They gave an example of certain precocial species in biology—who possess anti-predator behaviors from the moment of birth and can perform complex motor and sensory tasks without learning, Hence, researchers constructed network architectures that can perform well without training. The team has also open-sourced the code to reproduce WANN experiments in the broader research community.
Researchers explored range of WANNs using topology search algorithm
The team started with a population of minimal neural network architecture candidates, which have very few connections, and used a well-established topology search algorithm to evolve the architecture by adding single connections and single nodes one by one. Unlike traditional neural architecture search methods, where all of the weight parameters of new architectures need to be trained using a learning algorithm, the team took a simpler approach. To all candidate architectures the team first assigned a single shared weight value at each iteration, and then optimized to perform well over a wide range of shared weight values.
In addition to exploring a range of weight agnostic neural networks, researchers also looked for network architectures that were only as complex as they need to be. They accomplished this by optimizing for both the performance of the networks and their complexity simultaneously, using techniques drawn from multi-objective optimization.
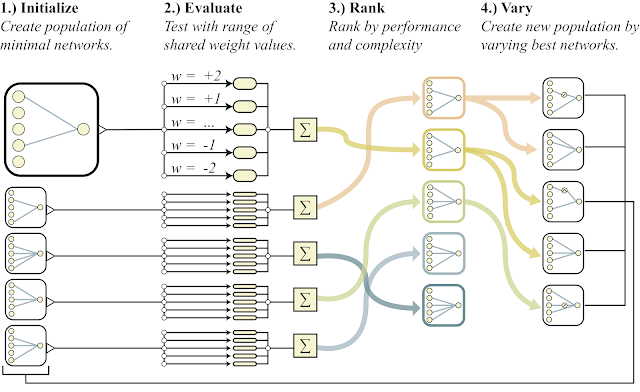
Source: Google AI blog. Overview of Weight Agnostic Neural Network Search and corresponding operators for searching the space of network topologies.
Training the WANN architectures
Researchers believe that unlike traditional networks, WANNS can be easily trained by finding the best single shared weight parameter that maximizes its performance. They proved this with an example of a swing-up cartpole task using constant weights:
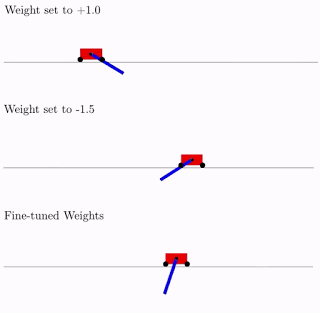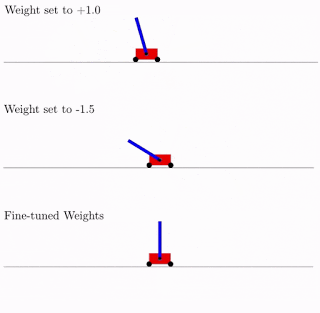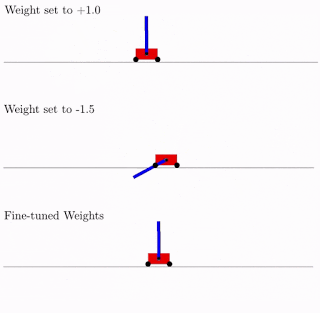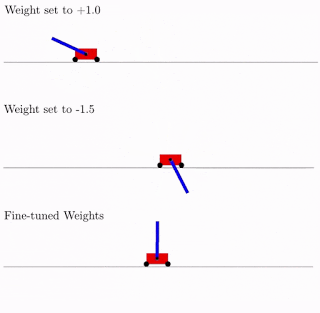
Source: Google AI blog. A WANN performing a Cartpole Swing-up task at various different weight parameters and fine tune weights
As per the above figure, WANNs can perform tasks using a range of shared weight parameters. However, the performance is not comparable to a network that learns weights for each individual connection, normally done in network training. To improve performance, researchers used the WANN architecture, and the best shared weight to fine-tune the weights of each individual connection using a reinforcement learning algorithm, like how a normal neural network is trained.
Created an ensemble of multiple distinct models of WANN architecture
The researchers also believe that by using copies of the same WANN architecture, where each copy of the WANN is assigned a distinct weight value, they created an ensemble of multiple distinct models for the same task. And according to them this ensemble generally achieves better performance than a single model. They illustrated this with an example of an MNIST classifier:
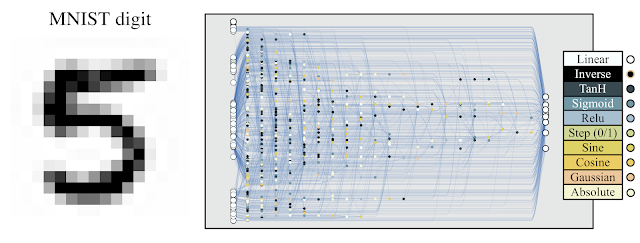
Source: Google AI blog
The team conclude that a conventional network with random initialization will achieve ~10% accuracy on MNIST. While this particular network architecture that uses random weights when applied to MNIST achieves an accuracy of > 80%. However, when an ensemble of WANNs is used the accuracy increases to > 90%.
The researchers hope that this work will serve as a stepping stone to discover novel fundamental neural network components such as convolutional networks in deep learning.
To know more about this research, check out the official Google AI blog.
What’s new in machine learning this week?
DeepMind introduces OpenSpiel, a reinforcement learning-based framework for video games
Google open sources an on-device, real-time hand gesture recognition algorithm built with MediaPipe