









Researchers have been constantly putting their efforts into improving conversational AI to make them better understand human languages and their nuances. One such advancement in the conversational AI field is the introduction of Transformer-based models such as OpenAI’s GPT-2 and Google’s BERT. In a quest to make the training and deployment of these vastly large language models efficient, NVIDIA researchers recently conducted a study, the details of which they shared yesterday.
Three scaling breakthroughs for NLP: fastest BERT-Large training (under one hour), fastest BERT inference (2.2ms on T4), and largest Transformer (GPT-2 8.3B). Code is open source. https://t.co/MUq7XzPQFe
— Bryan Catanzaro (@ctnzr) August 13, 2019
NVIDIA’s Tensor core GPU took less than an hour to train the BERT model
BERT, short for, Bidirectional Encoder Representations from Transformers, was introduced by a team of researchers at Google Language AI. It is capable of performing a wide variety of state-of-the-art NLP tasks including Q&A, sentiment analysis, and sentence classification. What makes BERT different from other language models is that it applies the bidirectional training of Transformer to language modelling. Transformer is an attention mechanism that learns contextual relations between words in a text. It is designed to pre-train deep bidirectional representations from the unlabeled text by using both left and right context in all layers.
NVIDIA researchers chose BERT-LARGE, a version of BERT created with 340 million parameters for the study. NVIDIA’s DGX SuperPOD was able to train the model in a record-breaking time of 53 minutes. The Super POD was made up of 92 DGX-2H nodes and 1472 GPUs, which were running PyTorch with Automatic Mixed Precision.
The following table shows the time taken to train BERT-Large for various numbers of GPUs:
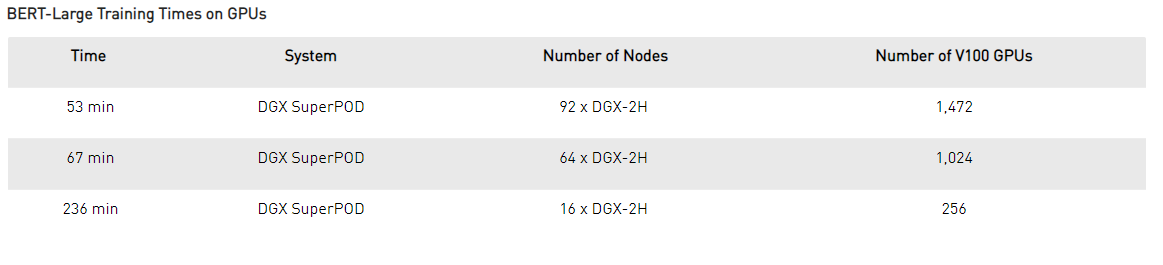
Source: NVIDIA
Looking at these results, the team concluded, “The combination of GPUs with plenty of computing power and high-bandwidth access to lots of DRAM, and fast interconnect technologies, makes the NVIDIA data center platform optimal for dramatically accelerating complex networks like BERT.”
In a conversation with reporters and analysts, Bryan Catarazano, Vice President of Applied Deep Learning Research at NVIDIA said, “Without this kind of technology, it can take weeks to train one of these large language models.” NVIDIA further said that it has achieved the fastest BERT inference time of 2.2 milliseconds by running it on a Tesla T4 GPU and TensorRT 5.1 optimized for datacenter inference.
NVIDIA launches Project Megatron, under which it will research training transformer language models at scale
Beginning this year, OpenAI introduced the 1.5 billion parameter GPT-2 language model that generates nearly coherent and meaningful texts. The NVIDIA Research team has built a scaled-up version of this model, called GPT-2 8B. As its name suggests, it is made up of 8.3 billion parameters, which makes it 24X the size of BERT-Large.
To train this huge model the team used PyTorch with 8-way model parallelism and 64-way data parallelism on 512 GPUs. This experiment was part of a bigger project called Project Megatron, under which the team is trying to create a platform that facilitates the training of such “enormous billion-plus Transformer-based networks.”
Here’s a graph showing the compute performance and scaling efficiency achieved:
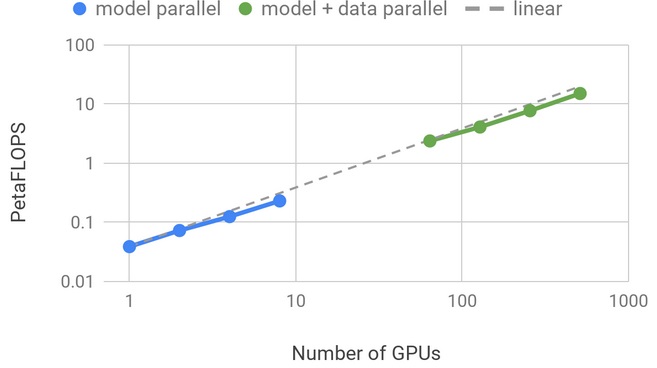
Source: NVIDIA
With the increase in the number of parameters, there was also a noticeable improvement in accuracy as compared to smaller models. The model was able to achieve a wikitext perplexity of 17.41, which surpasses previous results on the wikitext test dataset by Transformer-XL. However, it does start to overfit after about six epochs of training that can be mitigated by using even larger scale problems and datasets.
NVIDIA has open-sourced the code for reproducing the single-node training performance in its BERT GitHub repository. The NLP code on Project Megatron is also openly available in Megatron Language Model GitHub repository.
To know more in detail, check out the official announcement by NVIDIA. Also, check out the following YouTube video: