









Google AI research team announced that it’s open sourcing GPipe, a distributed machine learning library for efficiently training Large-scale Deep Neural Network Models, under the Lingvo Framework, yesterday.
GPipe makes use of synchronous stochastic gradient descent and pipeline parallelism for training. It divides the network layers across accelerators and pipelines execution to achieve high hardware utilization. GPipe also allows researchers to easily deploy accelerators to train larger models and to scale the performance without tuning hyperparameters.
Google AI researchers had also published a paper titled “GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism” last year in December. In the paper, researchers demonstrated the use of pipeline parallelism to scale up deep neural networks to overcome the memory limitation on current accelerators. Let’s have a look at major highlights of GPipe.
GPipe helps with maximizing the memory and efficiency
GPipe helps with maximizing the memory allocation for model parameters. Researchers conducted experiments on Cloud TPUv2s. Each of these Cloud TPUv2s consists of 8 accelerator cores and 64 GB memory (8 GB per accelerator). Generally, without GPipe, a single accelerator is able to train up to 82 million model parameters because of the memory limitations, however, GPipe was able to bring down the immediate activation memory from 6.26 GB to 3.46GB on a single accelerator.
Researchers also measured the effects of GPipe on the model throughput of AmoebaNet-D to test its efficiency. Researchers found out that there was almost a linear speedup in training. GPipe also enabled 8 billion parameter Transformer language models on 1024-token sentences using speedup of 11x.
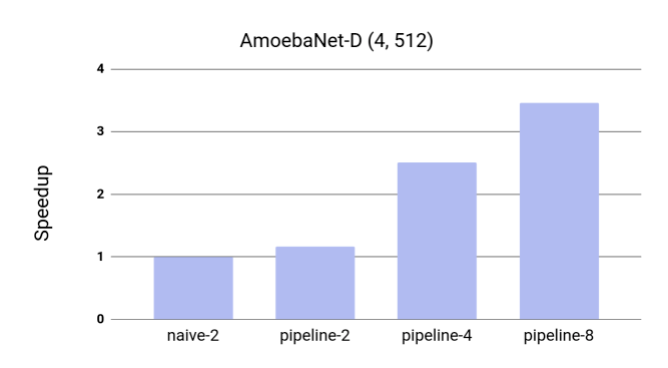
Speedup of AmoebaNet-D using GPipe
Putting the accuracy of GPipe to test
Researchers used GPipe to verify the hypothesis that scaling up existing neural networks can help achieve better model quality. For this experiment, an AmoebaNet-B with 557 million model parameters and input image size of 480 x 480 was trained on the ImageNet ILSVRC-2012 dataset. Researchers observed that the model was able to reach 84.3% top-1 / 97% top-5 single-crop validation accuracy without the use of any external data.
Researchers also ran the transfer learning experiments on the CIFAR10 and CIFAR100 datasets, where they observed that the giant models improved the best published CIFAR-10 accuracy to 99% and CIFAR-100 accuracy to 91.3%.
“We are happy to provide GPipe to the broader research community and hope it is a useful infrastructure for efficient training of large-scale DNNs”, say the researchers.
For more information, check out the official GPipe Blog post.
Read Next
Google AI researchers introduce PlaNet, an AI agent that can learn about the world using only images