









Google researchers announced a new TensorFlow framework, called Lingvo, last week. Lingvo offers a complete solution for collaborative deep learning research, with a particular focus towards sequence modeling tasks such as machine translation, speech recognition, and speech synthesis.
The TensorFlow team also announced yesterday that it is open sourcing Lingvo. “To show our support of the research community and encourage reproducible research effort, we have open-sourced the framework and are starting to release the models used in our papers”, states the TensorFlow team.
In support of the research community and to encourage reproducible research efforts, we have open-sourced Lingvo, a general deep learning @TensorFlow framework with a focus on language-related tasks. https://t.co/DAHDjBcshB
— Google AI (@GoogleAI) February 25, 2019
Lingvo has been designed for collaboration and has a code with a consistent interface and style that is easy to read and understand. It also consists of a flexible modular layering system that promotes code reuse. Since it involves many people using the same codebase, it is easier to employ other ideas within your models. Also, you can adapt to the existing models to new datasets with ease.
Other than that, Lingvo makes it easier to reproduce and compare the results in research. This is because Lingvo adopts a system where all the hyperparameters of a model get configured within their own dedicated sub-directory that is separate from the model logic. All the models within Lingvo are built from the same common layers which allow them to be compared with each other easily. Also, all of these models have the same overall structure from input processing to loss computation, and all the layers consist of the same interface.
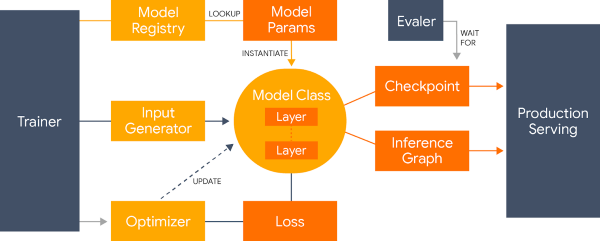
Overview of the LINGVO framework
Moreover, all the hyperparameters within Lingvo get explicitly declared and their values get logged at runtime. This makes it easier to read and understand the models. Lingvo can also easily train the on production scale datasets. There’s also additional support provided for synchronous and asynchronous distributed training. In Lingvo, inference-specific graphs are built from the same shared code used for training. Also, quantization support has been built in directly into the framework.
Lingvo initially started out for natural language processing (NLP) tasks but has become very flexible and is also applicable to models used for tasks such as image segmentation and point cloud classification. It also supports distillation, GANs, and multi-task models. Additionally, the framework does not compromise on the speed and comes with an optimized input pipeline and fast distributed training.
For more information, check out the official LINGVO research paper.
Read Next
Google engineers work towards large scale federated learning
Google AI researchers introduce PlaNet, an AI agent that can learn about the world using only images