99 great recipes for mastering MySQL configuration and administration
Set up MySQL to perform administrative tasks such as efficiently managing data and database schema, improving the performance of MySQL servers, and managing user credentials
Deal with typical performance bottlenecks and lock-contention problems
Restrict access sensibly and regain access to your database in case of loss of administrative user credentials
Part of Packt's Cookbook series: Each recipe is a carefully organized sequence of instructions to complete the task as efficiently as possible
Inserting new data and updating data if it already exists
Manipulating data in a database is part of everyday work and the basic SQL means of INSERT, UPDATE, and DELETE make this a pretty straightforward, almost trivial task—but is this always true?
When considering data manipulation, most of the time we think of a situation where we know the content of the database. With this information, it is usually pretty easy to find a way of changing the data the way you intend to. But what if you have to change data in circumstances where you do not know the actual database content beforehand?
You might answer: "Well, then look at your data before changing it!" Unfortunately, you do not always have this option. Think of distributed installations of any software that includes a database. If you have to design an update option for this software (and the respective databases), you might easily come to a situation where you simply do not know about the actual database content.
One example of a problem arising in these cases is the question of whether to insert or to update data: "Does the data in question already (partially) exist?" Let us assume a database table config that stores configuration settings. It holds key-value pairs, with name being the name (and thus the key) of the setting and value its value. This table exists in different database installations, one for every branch office of your company. Your task is to create an update package to set a uniform upper limit of 25% for the price discount that is allowed in your sales software. If no such limit has been defined yet, there is no respective entry in the config table, and you have to insert a new record. If the limit, however, has been set before (for example by the local manager), the entry does already exist, in which case you have to update it to hold the new value.
While the update of a potentially existing entry does not pose a problem, an INSERT statement that violates uniqueness constraints will simply cause an error. This is, however, typically not acceptable in an automated update procedure. The following recipe will show you how to solve this problem with only one SQL command.
Getting ready
Besides a running MySQL server, a SQL client, and an account with appropriate user rights (INSERT, UPDATE), we need a table to update. In the earlier example, we assumed a table named sample.config with two character columns name and value. The name column is defined as the primary key:
CREATE TABLE sample.config ( name VARCHAR(64) PRIMARY KEY, value VARCHAR(64));
How to do it...
Connect to your database using your SQL client
Execute the following command:
mysql> INSERT INTO sample.config VALUES ("maxPriceDiscount", "25%") ON DUPLICATE KEY UPDATE value='25%';
Query OK, 1 row affected (0.05 sec)
How it works...
This command is easily explained because it simply does what it says: it inserts a new row in the table using the given values, as long as this does not cause a duplicate entry in either the primary key or another unique index. If a duplicate record exists, the existing row is updated according to the clauses defined after ON DUPLICATE KEY UPDATE.
While it is sometimes tedious to enter some of the data and columns two times (once for the INSERT and a second time for the UPDATE), this statement allows for a lot of flexibility when it comes to the manipulation of potentially existing data.
Please note that when executing the above statement, the result differs slightly with respect to the number of affected rows, depending on the actual data present in the database: When the record does not exist yet, it is inserted, which results in one affected row. But if the record is updated rather than inserted, it reports two affected rows instead, even if only one row gets updated.
There's more...
The INSERT INTO … ON DUPLICATE UPDATE construct does not work when there is no UNIQUE or PRIMARY KEY defined on the target table. If you have to provide the same semantics without having appropriate key definitions in place, it is recommended to use the techniques discussed in the next recipe.
Inserting data based on existing database content
In the previous recipe Inserting new data and updating data if it already exists, we discussed a method to either insert or update records depending on whether the records already exist in the database. A similar problem arises when you need to insert data to your database, but the data to insert depends on the data in your database.
As an example, consider a situation in which you need to insert a record with a certain message into a table logMsgs, but the message itself should be different depending on the current system language that is stored in a configuration table (config).
Unlock access to the largest independent learning library in Tech for FREE!
Get unlimited access to 7500+ expert-authored eBooks and video courses covering every tech area you can think of.
Renews at $19.99/month. Cancel anytime
It is fairly easy to achieve a similar behavior for an UPDATE statement because this supports a WHERE clause that can be used to only perform an update if a certain precondition is met:
UPDATE logMsgs SET message= CONCAT('Last update: ', NOW()) WHERE EXISTS (SELECT value FROM config WHERE name='lang' AND value = 'en'); UPDATE logMsgs SET message= CONCAT('Letztes Update: ', NOW()) WHERE EXISTS (SELECT value FROM config WHERE name='lang' AND value = 'de'); UPDATE logMsgs SET message= CONCAT('Actualisation derniere: ', NOW()) WHERE EXISTS (SELECT value FROM config WHERE name='lang' AND value = 'fr');
Unfortunately, this approach is not applicable to INSERT commands, as these do not support a WHERE clause. Despite this missing option, the following recipe describes a method to make INSERT statements execute only if an appropriate precondition in the database is met.
Getting ready
As before, we assume a database, a SQL client (mysql), and a MySQL user with sufficient privileges (INSERT and SELECT in this case). Additionally, we need a table to insert data into (here: logMsgs) and a configuration table config (please refer to the previous recipe for details).
How to do it...
Connect to your database using your SQL client.
Execute the following SQL commands:
mysql> INSERT INTO sample.logMsgs(message) -> SELECT CONCAT('Last update: ', NOW()) -> FROM sample.config WHERE name='lang' AND value='en'; Query OK, 0 rows affected (0.00 sec) Records: 0 Duplicates: 0 Warnings: 0
How it works...
Our goal is to have an INSERT statement take into account the present language stored in the database. The trick to do so is to use a SELECT statement as input for the INSERT. The SELECT command provides a WHERE clause, so you can use a condition that only matches for the respective language. One restriction of this solution is that you can only insert one record at a time, so the size of scripts might grow considerably if you have to insert lots of data and/or have to cover many alternatives.
There's more...
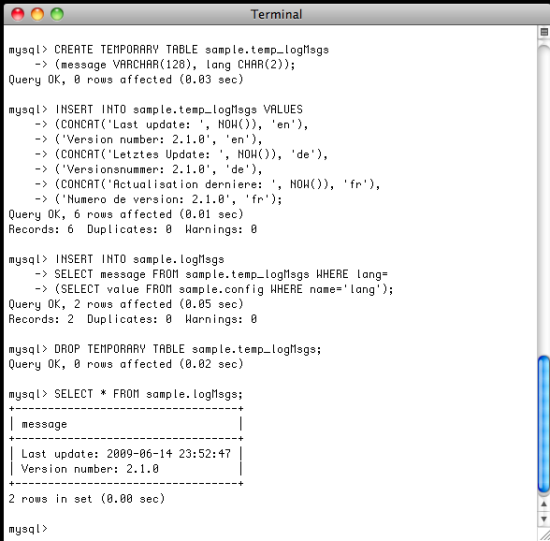
If you have more than just a few values to insert, it is more convenient to have the data in one place rather than distributed over several individual INSERT statements. In this case, it might make sense to consolidate the data by putting it inside a temporary table; the final INSERT statement uses this temporary table to select the appropriate data rows for insertion into the target table. The downside of this approach is that the user needs the CREATE TEMPORARY TABLES privilege, but it typically compensates with much cleaner scripts:
After creating the temporary table with the first statement, we insert data into the table with the following INSERT statement. The next statement inserts the appropriate data into the target table sample.logMsgs by selecting the appropriate data from the temporary data that matches the language entry from the config table. The temporary table is then removed again. The final SELECT statement is solely for checking the results of the operation.
Deleting all data from large tables
Almost everyone who works with databases experiences the constant growth of the data stored in their database and it is typically well beyond the initial estimates. Because of that you often end up with rather large data sets. Another common observation is that in most databases, there are some tables that have a special tendency to grow especially big.
If a table's size reaches a virtual threshold (which is hard to define, as it depends heavily on the access patterns and the data structures), it gets harder and harder to maintain and performance degradation might occur. From a certain point on, it is even difficult to get rid of data in the table again, as the sheer number of records makes deletion a pretty expensive task. This particularly holds true for storage engines with Multi-Version Concurrency Control (MVCC): if you order the database to delete data from the table, it must not be deleted right away because you might still roll back the deletion. So even while the deletion was initiated, a concurrent query on the table still has to be able to see all the records (depending on the transaction isolation level). To achieve this, the storage engine will only mark the records as deleted, but the actual deletion takes place after the operation is committed and all other transactions that access this table are closed as well.
If you have to deal with large data sets, the most difficult task is to operate on the production system while other processes concurrently work on the data. In these circumstances, you have to keep the duration of your maintenance operations as low as possible in order to minimize the impact on the running system. As the deletion of data from a large table (typically starting at several millions of rows) might take quite some time, the following recipe shows a way of minimizing the duration of this operation in order to reduce side effects (like locking effects or performance degradation).
Getting ready
Besides a user account with appropriate privileges (DELETE), you need a sufficiently large table to delete data from.
For this recipe, we will use the employees database, which is an example database available from MySQL: http://dev.mysql.com/doc/employee/en/employee.html This database provides some tables with sensible data and some pretty large tables, the largest having more than 2.8 million records.
We assume that the Employees database was installed with an InnoDB storage engine enabled. To delete all rows of the largest table employees.salaries in a quick way, please read on.

 United States
United States
 Great Britain
Great Britain
 India
India
 Germany
Germany
 France
France
 Canada
Canada
 Russia
Russia
 Spain
Spain
 Brazil
Brazil
 Australia
Australia
 Singapore
Singapore
 Canary Islands
Canary Islands
 Hungary
Hungary
 Ukraine
Ukraine
 Luxembourg
Luxembourg
 Estonia
Estonia
 Lithuania
Lithuania
 South Korea
South Korea
 Turkey
Turkey
 Switzerland
Switzerland
 Colombia
Colombia
 Taiwan
Taiwan
 Chile
Chile
 Norway
Norway
 Ecuador
Ecuador
 Indonesia
Indonesia
 New Zealand
New Zealand
 Cyprus
Cyprus
 Denmark
Denmark
 Finland
Finland
 Poland
Poland
 Malta
Malta
 Czechia
Czechia
 Austria
Austria
 Sweden
Sweden
 Italy
Italy
 Egypt
Egypt
 Belgium
Belgium
 Portugal
Portugal
 Slovenia
Slovenia
 Ireland
Ireland
 Romania
Romania
 Greece
Greece
 Argentina
Argentina
 Netherlands
Netherlands
 Bulgaria
Bulgaria
 Latvia
Latvia
 South Africa
South Africa
 Malaysia
Malaysia
 Japan
Japan
 Slovakia
Slovakia
 Philippines
Philippines
 Mexico
Mexico
 Thailand
Thailand