









A team of researchers, Sanjay Krishnan, Zongheng Yang, Ken Goldberg, Joseph M. Hellerstein, and Ion Stoica, from RISELab, UC Berkeley, have shown that deep reinforcement learning is successful at optimizing SQL joins, a problem studied for decades in the database community.
Background
SQL query optimization has been studied in the database community for almost 40 years. Join Ordering problem is central to query optimization. Despite that problem, there is still a multitude of research projects that attempt to better understand join optimizers performance in terms of multi-join queries.
This research shows that reinforcement learning (deep RL) provides a new solution to deal with this problem. The traditional dynamic programs generally reuse the results that have been previously computed via memoization ( optimization technique used primarily to speed up computer programs) while Reinforcement Learning represents the information in the previously computed results with the help of a learned model.
“We apply an RL model with a particular structure, a regression problem that associates the downstream value (future cumulative cost) with a decision (a join of two relations for a given query). Training this model requires observing join orders and their costs sampled from a workload. By projecting the effects of a decision into the future, the model allows us to dramatically prune the search space without exhaustive enumeration,” reads the research paper.
The research was carried out mainly with two methods, namely, join ordering problem as a Markov Decision process and a deep reinforcement learning optimizer, DQ.
Join Ordering using Reinforcement Learning
Researchers formulated the join ordering problem as a Markov Decision Process (MDP), which formalizes a wide range of problems such as path planning and scheduling. Then a popular RL technique, Q-learning is applied to solve the join-ordering MDP, where:
- States, G: the remaining relations to be joined.
- Actions, c: a valid join out of the remaining relations.
- Next states, G’: naturally, this is the old “remaining relations” set with two relations removed and their resultant join added.
- Reward, J: estimated cost of the new join.
The Q-function can be defined as Q(G, c), which evaluates the long-term cost of each join .i.e. the cumulative cost for all subsequent joins after the current join decision.
Q(G, c) = J(c) + \min_{c’} Q(G’, c’).
After access to the Q-function, joins can be ordered in a greedy fashion, which involves starting with an initial query graph, finding the join with the lowest Q(G, c), updating the query graph and repeat. Once done with this, Bellman’s Principle of Optimality is used which tells us if an algorithm is provably optimal. Bellman’s “Principle of Optimality” is one of the most important results in computing.
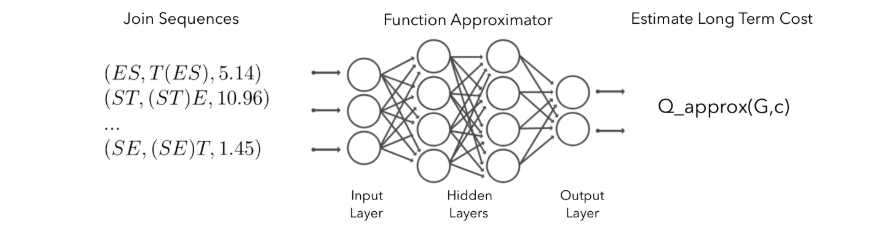
Figure 1: Using a neural network to approximate the Q-function.
The output layer, intuitively, means “If we make a join c on the current query graph G, how much does it minimize the cost of the long-term join plan?”
Now, as there is no access provided to the true Q-function, it is approximated with the help of a neural network (NN). When an NN is used to learn the Q-function, the technique is called Deep Q-network (DQN).
Now, a neural net is trained that takes in (G, c) and outputs an estimated Q(G,c).
DQ, the Deep Reinforcement Learning Optimizer
The deep RL-based optimizer uses only a moderate amount of training data to achieve plan costs within 2x of the optimal solution on all cost models. DQ uses a multi-layer perceptron (MLP) neural network which is used to represent the Q-function.
First, let’s start with collecting data to learn the Q function. Here the past execution data is observed. DQ accepts a list of (G, c, G’, J) from any underlying optimizer.
The second step is the featurization of states and actions. Now a neural net is used to represent Q(G, c), it is necessary to feed states G and actions c into the network as fixed-length feature vectors.
This featurization process is simple where 1-hot vectors are used for encoding the set of all attributes that exist in the query graph.
The third step is Neural network training & planning. Here, DQ makes use of a simple 2-layer fully connected network, by default. Training is done using a standard stochastic gradient descent.
Once the Neural Network is trained, DQ accepts an SQL query which is in plain text. It then parses the SQL query into an abstract syntax tree form, featurizes the tree, and invokes the neural network when a candidate join is scored. Lastly, DQ can be periodically re-tuned with the feedback from real execution.
Evaluating DQ
For this, the researchers used a recently published Join Order Benchmark (JOB). The database comprises 21 tables from IMDB with 33 query templates and a total of 113 queries. Sizes of joins in the queries range from 5 to 15 relations.
The training data is collected by DQ from exhaustive enumeration for cases when the number of relations to join is no larger than 10 as well as from greedy algorithm for additional relations.
DQ is then compared against several heuristic optimizers (QuickPick; KBZ) as well as classical dynamic programs (left-deep; right-deep; zig-zag). Then the plans that are produced by each optimizer gets scored and compared to the optimal plans achieved via exhaustive enumeration.
After this, to show that a learning-based optimizer can adapt to different environments, three designed cost models are used.
Results
Across all the cost models, the researchers found that DQ is competitive with the optimal solution without any prior knowledge of the index structure. Furthermore, DQ produces good plans at a much faster speed as opposed to classical dynamic programs.
Also, in the large-join regime, DQ achieves drastic speedups. The largest joins DQ performs 10,000x better as compared to exhaustive enumeration, over 1,000x faster as compared to zig-zag, and more than 10x faster than left/right-deep enumeration.
“We believe this is a profound performance argument for such a learned optimizer: it would have an even more unfair advantage when applied to larger queries or executed on specialized accelerators (e.g., GPUs, TPUs)” says by Zongheng Yang in the RISELab Blog.
For more details, check out the official research paper.
Read Next
How Facebook data scientists use Bayesian optimization for tuning their online systems