









In this post, we have used Recurrent Neural Networks to capture and model human motion data and generate motions by prediction of the next immediate data point at each time-step. Our RNN is armed with recently proposed Gated Recurrent Units, which have shown promising results in some sequence modeling problems such as Machine Translation and Speech Synthesis. We demonstrate that this model is able to capture long-term dependencies in data and generate realistic motions.
Sequence modeling has been a challenging problem in Machine Learning that requires models, which are able to capture temporal dependencies. One of the early models for sequence modeling was Hidden Markov Model (HMM). HMMs are able to capture data distribution using multinomial latent variables. In this model, each data point at time t is conditioned on the hidden state at time t. And hidden state at time t is conditioned on hidden state at time t − 1. In HMMs both P(x_t|s_t) and P(s_t|s_{t−1}) are same for all time-steps. A similar idea of parameter sharing is used in Recurrent Neural Network (RNN). RNNs are an extension of feedforward neural networks, which their weights are shared for every time-step in data (Figure 1). Consequently, we can apply RNNs to sequential input data. Theoretically, RNNs are capable of capturing sequences with arbitrary complexity. However, there are some difficulties during training RNNs on sequences with long-term dependencies. Among lots of solutions for RNNs’ training problems over the past few decades, we use Gated Recurrent Units. Gated Recurrent Unit performs much better than conventional tanh units. In the rest of this blog, we are going to introduce the model, train it on the MIT motion database, and show that it is capable of capturing complexities of human body motions. Then we demonstrate that we are able to generate sequences of motions by predicting the next immediate data point given all previous data points.
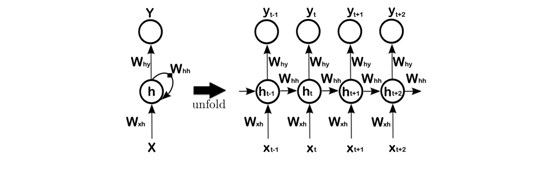
Figure 1: Left : A Recurrent Neural Network with recurrent connection from hidden units to themselves. Right : A same network but unfolded in time. Note that weight matrices are same for every time-step.
We can use a Recurrent Neural Network as a generative model in such a way that the output of the network in time-step t − 1 defines a probability distribution over the next input at time-step t. According to the chain rule, we can write the joint probability distribution over the input sequence as follows:
P(x_1, x_2, …, x_N ) = P(x_1) P(x_2|x_1) … P(x_T |x_1, …, X_{T −1}).
Now we can model each of these conditional probability distributions as a function of hidden states:
P(x_t|x_1, …, x_{t−1}) = f(h_t).
Obviously, since h_t is a fixed-length vector and {x_1, …, x_{t−1}} is a variable-length sequence, it can be considered a lossy compression. During the learning process, the network should learn to keep important information and throw away useless information. Thus, in practice the network just looks at time-steps back until x_{t−k}. The architecture of a Generative Recurrent Neural Network is shown in Figure 2.
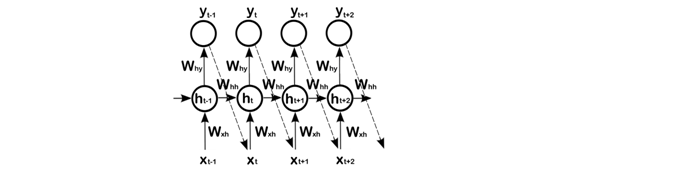
Figure 2: An unfolded Generative Recurrent Neural Network which output at time-step t-1 defines a conditional probability distribution over the next input. Dashed-lines are during generating phase.
However, as shown by Prof. Bengio et al., there are optimization issues when we try to train such models with long-term dependency in data. The problem is that when an error occurs, as we backpropagate it through time to update the parameters, the gradient may decay exponentially to zero (gradient vanishing) or get exponentially large (gradient explosion). For the problem of huge gradients, an ad-hoc solution is to restrict the gradient not to go over a threshold. This technique is known as gradient clipping. But the solution for gradient vanishing is not trivial. Over the past few decades, several methods were proposed to tackle this problem. Among them, gating methods have shown promising results in comparison with Vanilla RNN in different tasks such as speech recognition, machine translation, and image caption generation. One of the modelsthat exploit a gating mechanism is gated recurrent unit.
Among Motion Capture (MOCAP) datasets, we use simple walking motion from the MIT Motion dataset. The dataset is generated by filming a man wearing a cloth with 17 small lights, which determine position of body joints. Each data point in our dataset consists of information about global orientation and displacement. To be able to generate more realistic motions, we use the same preprocessing as used by Taylor et al. Our final dataset contains 375 rows where each row contains 49 ground-invariant, zero-mean, and unit variance features of body joints during walking. We also used Prof. Neil Lawrence’s motion capture toolbox to visualize data in 3D space. Samples of the data are shown in Figure 3.
Figure 3: Samples of training data from the MIT Motion Capture dataset (Takenfrom Prof. Taylor’s website)
We train our GRU Recurrent Neural Network, which has 49 input units and 120 hidden units in a single hidden layer. Then, we use it in a generative fashion, which each output at time t is fed to the model as x_{t+1}. To initialize the model, we first feed the model with 50 frames of the training data, and then let the model to generate arbitrary length sequence. Generation quality is good enough in a way that it cannot be distinguished from real training data. The initialization and generation phases are shown in Figure 4. Sample generation is visualized in Figure 5.
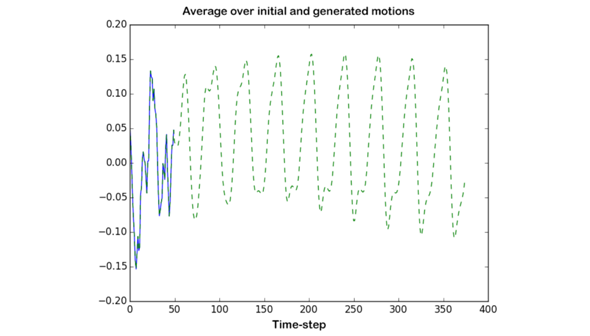
Figure 4: This graph shows the initialization using real data for first 50 time-steps in a solid blue line and the rest is a generated sequence in a green dashedline.
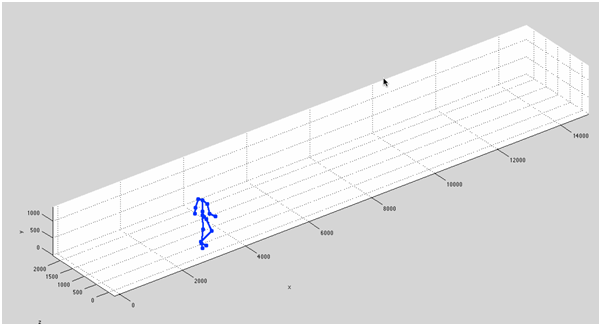
Figure 5: Samples of generated data from the trained model.
About the Author
Mohammad Pezeshki is a PhD student in the MILA lab at University of Montreal. He obtained his bachelor’s in computer engineering from Amirkabir University of Technology (Tehran Polytechnic) in July 2014. He then obtained his master’s in June 2016. His research interests lie in the fields of artificial intelligence, machine learning, probabilistic models and specifically deep learning.









