









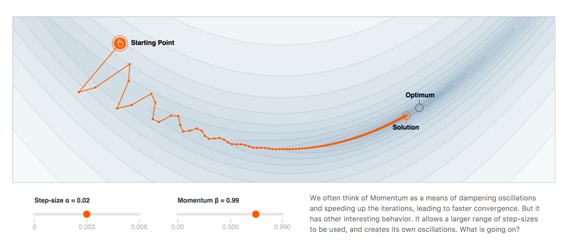
Momentum works
In 1984, the idea of an AI winter (a period where deep research in this artificial intelligence almost completely stops) appeared. The interesting thing is that it emerged both from technical disillusions, and bad press coverage. Scientists were woeful after the initial promises of artificial intelligence funding stopped, and everything broke apart for a while.
This example serves as a solemn statement; the way research is communicated matters a great deal for development. Through the lens of Distill, a publishing platform for machine learning papers, we will explore why. Then, we shall see why you should care if you embrace data for a living.
How we share knowledge
Engineering is a subtle alchemy of knowledge and experience. The convenient state of the industry is that we are keen to share both online. It builds carriers, relationships, helps in the hiring process, enhances companies’ image, etc. The process is not perfect, but once the sources are right, it starts to become addictive.
Yet, shocking exceptions occur in the middle of this never-ending stream of exciting articles that crash forever in Pocket. A majority of the content is beautifully published on carefully designed engineering blogs, or on Medium, and takes less than 10 minutes to read. Yet, sometimes the click-bait title gets you redirected on a black and white PDF with dense text and low-resolution images.
We can feel the cognitive overhead of going through such papers. For one, they are usually more in-depth analyses. Putting in the effort to understand them when the material is also less practical and the content harder to parse, can distract readers. This is unfortunate because practical projects are growing in complexity, and engineers are expected to deliver deep expertise on the edge of new technologies like machine learning.
So, maybe you care about consuming knowledge resulting from three years of intensive research and countless more years of collaborative work. Or maybe you want your paper to help your peers to progress, build upon it, and recognize you as a valuable contributor to their field. If so, then the Distill publishing platform could really help you out.
What is Distill?
Before exploring the how, let’s detail the what. As explained in the footer of the website:
“Distill is dedicated to clear explanations of machine learning.”
Or to paraphrase Michael Nielsen from Hacker News,
“In a nutshell, Distill is an interactive, visual journal for machine learning research.”
Thanks to modern web tools, authors can craft and submit papers for review before being published. The project was founded by Chris Olah and Shan Carter, members of the Google Brain team. They put together a Steering Committee composed of venerable leaders from open source, Deep Mind, and YC research. Effectively, they gathered an exciting panel of experts to lead how machine learning knowledge should be spread in 2017. Mike Bostock, for example, is the creator of d3.js, a reference for data visualization, or [Amanda Cox] [7], a remarkable data journalist at the New York Times.
Together they shape the concept of “explorable explanations,” i.e. articles the reader can interact with. By directly experimenting the theories in the article, the reader can better map their own mental models with the author’s explanations. It is also a great opportunity to verbalize complex problems in a form that triggers new insights and seed productive collaboration for future work. I hope it sounds exciting to you, but let’s dive into the specifics of why you should care.
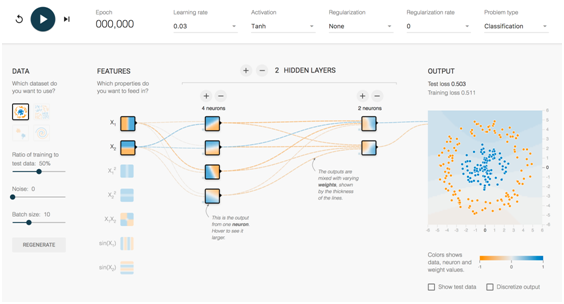
Tensorflow Playground
Why does it matter?
Improving research clarity, range of audience, efficiency, and opportunity of communication should have a beautiful side effect: accelerating research. Chris and Shan explain the pain points they intend to solve in their article Research Debt. As scientists’ work piles up, we need, as a community, to transform this ever-growing debt into an opportunity that enables technologies to thrive. Especially today where most of the world wonders how the latest advances in AI will be used. With Distill you should be able to have a flexible medium to base research on clearly and explicitly, and is a great way to improve confidence in our work and push faster and safer beyond the bounds.
But as a data professional, you sometimes spend your days not thinking of saving the world from robots—like thinking of yourself and your career. As a reader, I can’t encourage you enough to follow the article feed or even the twitter account. There are only a few for now, but they are exceptional (in my humble opinion). Your mileage may vary depending on your experience, or how you apply data for a living, but I bet you can boost your data science skills browsing through the publications.
As an author, it provides an opportunity:
- Reaching the level of quality and empathy of the previous publications
- Interacting with top-level experts in the community during reviews
- Gaining an advantageous visibility in machine learning and setting yourself as an expert on highly technical matters
- Making money by competing for the Distill Prize
The articles are lengthy and demanding, but if you work in the field of machine learning, you’ve probably already accepted that the journey was worth it.
The founders of the project have put a lot of effort into making the platform as impactful as possible for the whole community. As an author, as a reader, or even as an open source contributor, you can be part of it and advance both your accomplishments and machine learning state of the art.
Distill as a project is also exciting to follow for its intrinsic philosophy and technologies. As engineers,quality blog posts overwhelm us, as we read to keep our minds sharp. The concept of explorable explanations could very well be a significant advancement in how we share knowledge online. Distill proves the technology is there, so this kind of publication could boost how a whole industry digests the flow of technologies. Explanations of really advanced concepts could become easier to grasp for beginners, or more actionable for busy senior engineers.I hope you will reflect on that and pick how Distill can move you forward.
About the author
Xavier Bruhiereis a Senior Data Engineer at Kpler. He is a curious, sharp, entrepreneur and engineer who has built many projects, broke most of them, and launch and scaled what was left, learning from them all.