









Yesterday, TensorFlow introduced a new model optimization toolkit. It is a suite of techniques that both new and experienced developers can leverage to optimize machine learning models. These optimization techniques are suitable for any TensorFlow model and will be particularly of use to developers running TensorFlow Lite.
What is model optimization in TensorFlow?
Support is added for post-training quantization to the TensorFlow Lite conversion tool. This can theoretically result in up to four times more compression in the data and up to three times faster execution for relevant machine learning models.
On quantizing the models they work on, developers will also gain additional benefits of less power consumption.
Enabling post-training quantization
This quantization technique is integrated into the TensorFlow Lite conversion tool. Initiating is easy. After building a TensorFlow model, you can simple enable the ‘post_training_quantize’ flag in the TensorFlow Lite conversion tool. If the model is saved and stored in saved_model_dir, the quantized tflite flatbuffer can be generated.
converter=tf.contrib.lite.TocoConverter.from_saved_model(saved_model_dir)
converter.post_training_quantize=True
tflite_quantized_model=converter.convert()
open(“quantized_model.tflite”, “wb”).write(tflite_quantized_model)There is an illustrative tutorial that explains how to do this. To use this technique for deployment on platforms currently not supported by TensorFlow Lite, there are plans to incorporate it into general TensorFlow tooling as well.
Post-training quantization benefits
The benefits of this quantization technique include:
- Approx Four times reduction in model sizes.
- 10–50% faster execution in models consisting primarily of convolutional layers.
- Three times the speed for RNN-based models.
- Most models will also have lower power consumption due to reduced memory and computation requirements.
The following graph shows model size reduction and execution time speed-ups for a few models measured on a Google Pixel 2 phone using a single core. We can see that the optimized models are almost four times smaller.
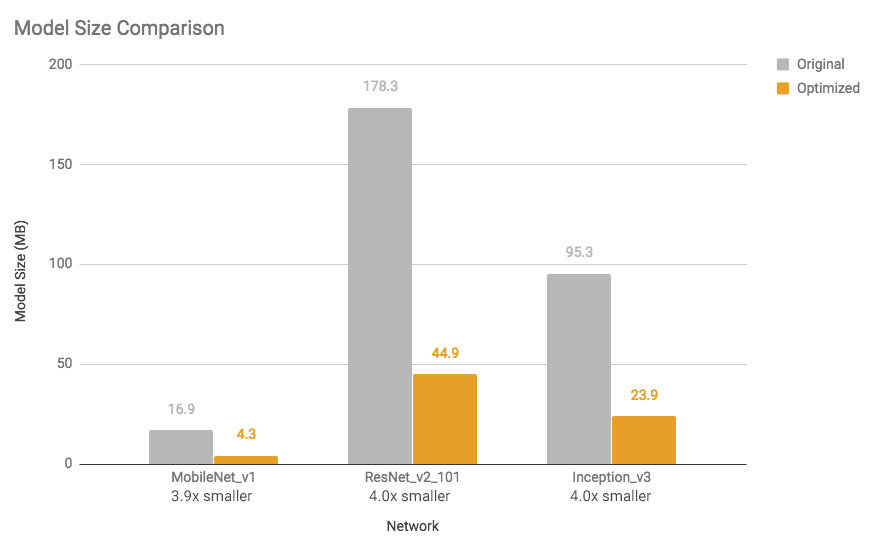 Source: Tensorflow Blog
Source: Tensorflow Blog
The speed-up and model size reductions do not impact the accuracy much. The models that are already small to begin with, may experience more significant losses. Here’s a comparison:
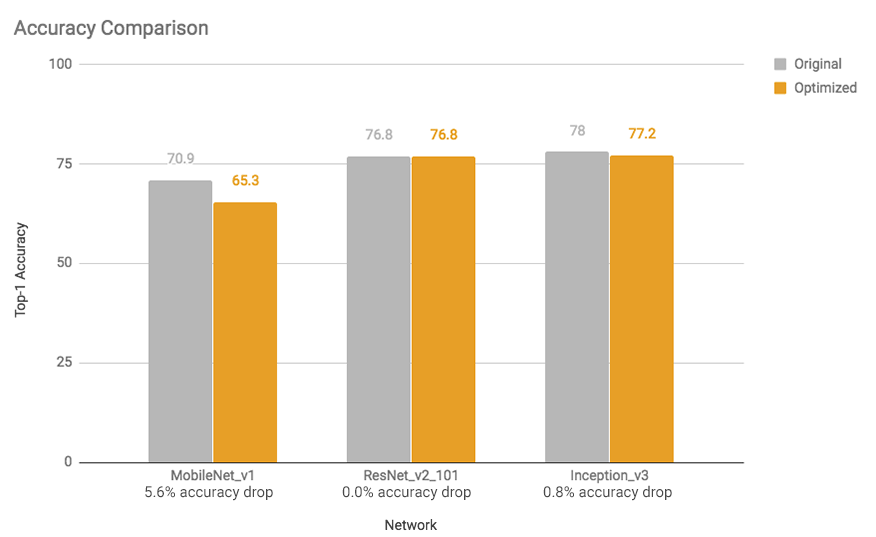
Source: Tensorflow Blog
How does it work?
Behind the scenes, optimizations are run by reducing the precision of the parameters (the neural network weights). The reduction is done from their training-time 32-bit floating-point representations to much smaller and efficient 8-bit integer representations.
These optimizations ensure pairing the less precise operation definitions in the resulting model with kernel implementations that use a mix of fixed and floating-point math. This results into executing the heaviest computations quickly, but with lower precision. However, the most sensitive ones are still computed with high precision. This gives little accuracy losses.
To know more about model optimization visit the TensorFlow website.
Read next
What can we expect from TensorFlow 2.0?
Understanding the TensorFlow data model [Tutorial]
AMD ROCm GPUs now support TensorFlow v1.8, a major milestone for AMD’s deep learning plans