









[box type=”note” align=”” class=”” width=””]This article is an excerpt from a book Mastering PostgreSQL 10 written by Hans-Jürgen Schönig. This book will help you master the capabilities of PostgreSQL 10 to efficiently manage and maintain your database.[/box]
In today’s post, we will learn about the different index types available for sorting in PostgreSQL and also understand how they function.
What are index types and why you need them
Data types can be sorted in a useful way. Just imagine a polygon. How would you sort these objects in a useful way? Sure, you can sort by the area covered, its length or so, but doing this won’t allow you to actually find them using a geometric search.
The solution to the problem is to provide more than just one index type. Each index will serve a special purpose and do exactly what is needed. The following six index types are available (as of PostgreSQL 10.0):
test=# SELECT * FROM pg_am;
amname | amhandler | amtype
---------+-------------+--------
btree | bthandler | i
hash | hashhandler | i
GiST | GiSThandler | i
Gin | ginhandler | i
spGiST | spghandler | i
brin | brinhandler | i
(6 rows)A closer look at the 6 index types in PostgreSQL 10
The following sections will outline the purpose of each index type available in PostgreSQL.
Note that there are some extensions that can be used on top of what you can see here. Additional index types available on the web are rum, vodka, and in the future, cognac.
Hash indexes
Hash indexes have been around for many years. The idea is to hash the input value and store it for later lookups. Having hash indexes actually makes sense. However, before PostgreSQL 10.0, it was not advised to use hash indexes because PostgreSQL had no WAL support for them. In PostgreSQL 10.0, this has changed. Hash indexes are now fully logged and are therefore ready for replication and are considered to be a 100% crash safe.
Hash indexes are generally a bit larger than b-tree indexes. Suppose you want to index 4 million integer values. A btree will need around 90 MB of storage to do this. A hash index will need around 125 MB on disk. The assumption made by many people that a hash is super small on the disk is therefore, in many cases, just wrong.
GiST indexes
Generalized Search Tree (GiST) indexes are highly important index types because they are used for a variety of different things. GiST indexes can be used to implement R-tree behavior and it is even possible to act as b-tree. However, abusing GiST for b-tree indexes is not recommended.
Typical use cases for GiST are as follows:
- Range types
- Geometric indexes (for example, used by the highly popular PostGIS extension)
- Fuzzy searching
Understanding how GiST works
To many people, GiST is still a black box. We will now discuss how GiST works internally. Consider the following diagram:
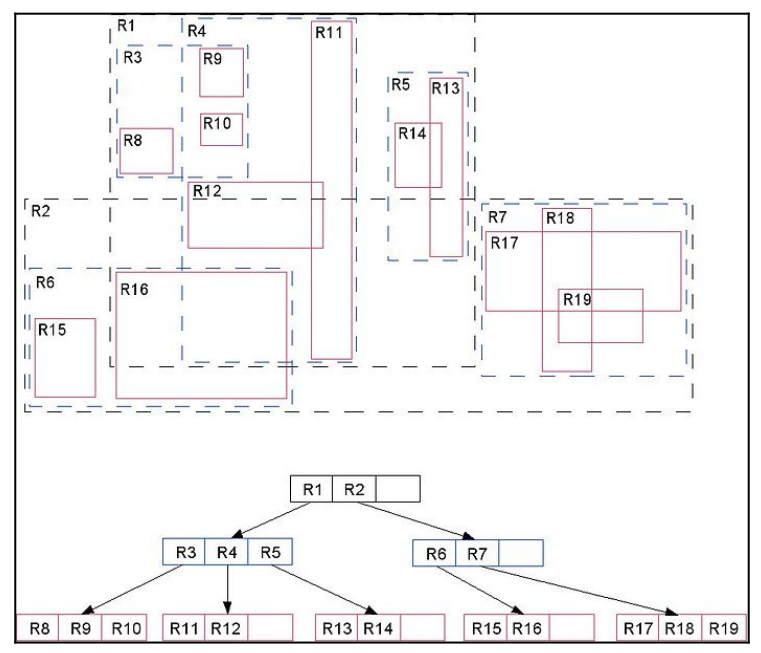
Source: http://leopard.in.ua/assets/images/postgresql/pg_indexes/pg_indexes2.jpg
Take a look at the tree. You will see that R1 and R2 are on top. R1 and R2 are the bounding boxes containing everything else. R3, R4, and R5 are contained by R1. R8, R9, and R10 are contained by R3, and so on. A GiST index is therefore hierarchically organized. What you can see in the diagram is that some operations, which are not available in b-trees are supported. Some of those operations are overlaps, left of, right of, and so on. The layout of a GiST tree is ideal for geometric indexing.
Extending GiST
Of course, it is also possible to come up with your own operator classes. The following strategies are supported:
| Operation | Strategy number |
| Strictly left of | 1 |
| Does not extend to right of | 2 |
| Overlaps | 3 |
| Does not extend to left of | 4 |
| Strictly right of | 5 |
| Same | 6 |
| Contains | 7 |
| Contained by | 8 |
| Does not extend above | 9 |
| Strictly below | 10 |
| Strictly above | 11 |
| Does not extend below | 12 |
If you want to write operator classes for GiST, a couple of support functions have to be provided. In the case of a b-tree, there is only the same function – GiST indexes provide a lot more:
| Function | Description | Support function number |
| consistent | The functions determine whether a key satisfies the query qualifier. Internally, strategies are looked up and checked. | 1 |
| union | Calculate the union of a set of keys. In case of numeric values, simply the upper and lower values or a range are computed. It is especially important to geometries. | 2 |
| compress | Compute a compressed representation of a key or value. | 3 |
| decompress | This is the counterpart of the compress function. | 4 |
| penalty | During insertion, the cost of inserting into the tree will be calculated. The cost determines where the new entry will go inside the tree. Therefore, a good penalty function is key to the good overall performance of the index. | 5 |
| picksplit | Determines where to move entries in case of a page split. Some entries have to stay on the old page while others will go to the new page being created. Having a good picksplit function is essential to a good index performance. | 6 |
| equal | The equal function is similar to the same function you have already seen in b-trees. | 7 |
| distance | Calculates the distance (a number) between a key and the query value. The distance function is optional and is needed in case KNN search is supported. | 8 |
| fetch | Determine the original representation of a compressed key. This function is needed to handle index only scans as supported by the recent version of PostgreSQL. | 9 |
Implementing operator classes for GiST indexes is usually done in C. If you are interested in a good example, I advise you to check out the btree_GiST module in the contrib directory. It shows how to index standard data types using GiST and is a good source of information as well as inspiration.
GIN indexes
Generalized inverted (GIN) indexes are a good way to index text. Suppose you want to index a million text documents. A certain word may occur millions of times. In a normal b- tree, this would mean that the key is stored millions of times. Not so in a GIN. Each key (or word) is stored once and assigned to a document list. Keys are organized in a standard b- tree. Each entry will have a document list pointing to all entries in the table having the same key. A GIN index is very small and compact. However, it lacks an important feature found in the b-trees-sorted data. In a GIN, the list of item pointers associated with a certain key is sorted by the position of the row in the table and not by some arbitrary criteria.
Extending GIN
Just like any other index, GIN can be extended. The following strategies are available:
| Operation | Strategy number |
| Overlap | 1 |
| Contains | 2 |
| Is contained by | 3 |
| Equal | 4 |
On top of this, the following support functions are available:
| Function | Description | Support function number |
| compare | The compare function is similar to the same function you have seen in b-trees. If two keys are compared, it
returns -1 (lower), 0 (equal), or 1 (higher). |
1 |
| extractValue | Extract keys from a value to be indexed. A value can have many keys. For example, a text value might consist of more than one word. | 2 |
| extractQuery | Extract keys from a query condition. | 3 |
| consistent | Check whether a value matches a query condition. | 4 |
| comparePartial | Compare a partial key from a query and a key from the index. Returns -1, 0, or 1 (similar to the same function supported by b-trees). | 5 |
| triConsistent | Determine whether a value matches a query condition (ternary variant). It is optional if the consistent function is present. | 6 |
If you are looking for a good example of how to extend GIN, consider looking at the btree_gin module in the PostgreSQL contrib directory. It is a valuable source of information and a good way to start your own implementation.
SP-GiST indexes
Space partitioned GiST (SP-GiST) has mainly been designed for in-memory use. The reason for this is an SP-GiST stored on disk needs a fairly high number of disk hits to function. Disk hits are way more expensive than just following a couple of pointers in RAM.
The beauty is that SP-GiST can be used to implement various types of trees such as quad- trees, k-d trees, and radix trees (tries).
The following strategies are provided:
| Operation | Strategy number |
| Strictly left of | 1 |
| Strictly right of | 5 |
| Same | 6 |
| Contained by | 8 |
| Strictly below | 10 |
| Strictly above | 11 |
To write your own operator classes for SP-GiST, a couple of functions have to be provided:
| Function | Description | Support function number |
| config | Provides information about the operator class in use | 1 |
| choose | Figures out how to insert a new value into an inner tuple | 2 |
| picksplit | Figures out how to partition/split a set of values | 3 |
| inner_consistent | Determine which subpartitions need to be searched for a query | 4 |
| leaf_consistent | Determine whether key satisfies the query qualifier | 5 |
BRIN indexes
Block range indexes (BRIN) are of great practical use. All indexes discussed until now need quite a lot of disk space. Although a lot of work has gone into shrinking GIN indexes and
the like, they still need quite a lot because an index pointer is needed for each entry. So, if there are 10 million entries, there will be 10 million index pointers. Space is the main concern addressed by the BRIN indexes. A BRIN index does not keep an index entry for each tuple but will store the minimum and the maximum value of 128 (default) blocks of data (1 MB). The index is therefore very small but lossy. Scanning the index will return more data than we asked for. PostgreSQL has to filter out these additional rows in a later step.
The following example demonstrates how small a BRIN index really is:
test=# CREATE INDEX idx_brin ON t_test USING brin(id); CREATE INDEX
test=# di+ idx_brin
List of relations
Schema | Name | Type | Owner | Table | Size
--------+----------+-------+-------+--------+-------+------------- public | idx_brin | index | hs | t_test | 48 KB
(1 row)In my example, the BRIN index is 2,000 times smaller than a standard b-tree. The question naturally arising now is, why don’t we always use BRIN indexes? To answer this kind of question, it is important to reflect on the layout of BRIN; the minimum and maximum value for 1 MB are stored. If the data is sorted (high correlation), BRIN is pretty efficient because we can fetch 1 MB of data, scan it, and we are done. However, what if the data is shuffled? In this case, BRIN won’t be able to exclude chunks of data anymore because it is very likely that something close to the overall high and the overall low is within 1 MB of data. Therefore, BRIN is mostly made for highly correlated data. In reality, correlated data is quite likely in data warehousing applications. Often, data is loaded every day and therefore dates can be highly correlated.
Extending BRIN indexes
BRIN supports the same strategies as a b-tree and therefore needs the same set of operators. The code can be reused nicely:
| Operation | Strategy number |
| Less than | 1 |
| Less than or equal | 2 |
| Equal | 3 |
| Greater than or equal | 4 |
| Greater than | 5 |
The support functions needed by BRIN are as follows:
| Function | Description | Support function number |
| opcInfo | Provide internal information about the indexed columns | 1 |
| add_value | Add an entry to an existing summary tuple | 2 |
| consistent | Check whether a value matches a condition | 3 |
| union | Calculate the union of two summary entries
(minimum/maximum values) |
4 |
Adding additional indexes
Since PostgreSQL 9.6, there has been an easy way to deploy entirely new index types as extensions. This is pretty cool because if those index types provided by PostgreSQL are not enough, it is possible to add additional ones serving precisely your purpose. The instruction to do this is CREATE ACCESS METHOD:
test=# h CREATE ACCESS METHOD Command: CREATE ACCESS METHOD
Description: define a new access method
Syntax:
CREATE ACCESS METHOD name TYPE
access_method_type HANDLER handler_functionDon’t worry too much about this command—just in case you ever deploy your own index type, it will come as a ready-to-use extension.
One of these extensions implements bloom filters. Bloom filters are probabilistic data structures. They sometimes return too many rows but never too few. Therefore, a bloom filter is a good method to pre-filter data.
How does it work? A bloom filter is defined on a couple of columns. A bitmask is calculated based on the input values, which is then compared to your query. The upside of a bloom filter is that you can index as many columns as you want. The downside is that the entire bloom filter has to be read. Of course, the bloom filter is smaller than the underlying data and so it is, in many cases, very beneficial.
To use bloom filters, just activate the extension, which is a part of the PostgreSQL contrib package:
test=# CREATE EXTENSION bloom; CREATE EXTENSIONAs stated previously, the idea behind a bloom filter is that it allows you to index as many columns as you want. In many real-world applications, the challenge is to index many columns without knowing which combinations the user will actually need at runtime. In the case of a large table, it is totally impossible to create standard b-tree indexes on, say, 80 fields or more. A bloom filter might be an alternative in this case:
test=# CREATE TABLE t_bloom (x1 int, x2 int, x3 int, x4 int, x5 int, x6 int, x7 int);
CREATE TABLECreating the index is easy:
test=# CREATE INDEX idx_bloom ON t_bloom USING bloom(x1, x2, x3, x4, x5, x6, x7);
CREATE INDEXIf sequential scans are turned off, the index can be seen in action:
test=# SET enable_seqscan TO off; SET
test=# explain SELECT * FROM t_bloom WHERE x5 = 9 AND x3 = 7; QUERY PLAN
------------------------------------------------------------------------- Bitmap Heap Scan on t_bloom (cost=18.50..22.52 rows=1 width=28)
Recheck Cond: ((x3 = 7) AND (x5 = 9))
-> Bitmap Index Scan on idx_bloom (cost=0.00..18.50 rows=1 width=0) Index Cond: ((x3 = 7) AND (x5 = 9))Note that I have queried a combination of random columns; they are not related to the actual order in the index. The bloom filter will still be beneficial.
If you are interested in bloom filters, consider checking out the website: https://en.wikipedia.org/wiki/Bloom_filter.
We learnt how to use the indexing features in PostgreSQL and fine-tune the performance of our queries.
If you liked our article, check out the book Mastering PostgreSQL 10 to implement advanced administrative tasks such as server maintenance and monitoring, replication, recovery, high availability, etc in PostgreSQL 10.