
Three MIT students and an associate professor published a paper in July. They introduce a concept called Instruction and Memory Level Parallelism (IMLP) task programming model for computing. They achieve this via a domain specific language (DSL) called Cimple (Coroutines for Instruction and Memory Parallel Language Extensions).
Why Cimple?
Before looking at what it is, let’s understand the motivation behind this work. As cited in the paper, currently there is a critical gap between millisecond and nanosecond latencies for process loading and execution. The existing software and hardware techniques hide the low latencies and are inadequate to fully utilize all of the memory from CPU caches to RAM. The work is based on a belief that an efficient, flexible, and expressive programming model can scale all of the memory hierarchy from tens to hundreds of nanoseconds.

Modern processors with dynamic execution are more capable of exploiting instruction level parallelism (ILP) and memory level parallelism (MLP). They do this by using wide superscalar pipelines and vector execution units, and deep buffers for inflight memory requests. However, these resources “often exhibit poor utilization rates on workloads with large working sets”.
With IMLP, the tasks execute as coroutines. These coroutines yield execution at annotated long-latency operations; for example, memory accesses, divisions, or unpredictable branches. The IMLP tasks are interleaved on a single process thread. They also integrate well with thread parallelism and vectorization. This led to a DSL embedded in C++ called Cimple.
What is Cimple?
It is a DSL embedded in C++, that allows exploring task scheduling and transformations which include buffering, vectorization, pipelining, and prefetching.
A simple IMLP programming model is introduced. It is based on concurrent tasks being executed as coroutines. Cimple separates the program logic from programmer hints and scheduling optimizations. It allows exploring task scheduling and techniques like buffering, vectorization, pipelining, and prefetching.
A compiler for CIMPLE automatically generates coroutines for the code. The CIMPLE compiler and runtime library are used via an embedded DSL. It separates the basic logic from scheduling hints and then into guide transformations. They also build an Abstract Syntax Tree (AST) directly from succinct C++ code.
The DSL treats expressions as opaque AST blocks. It exposes conventional control flow primitives in order to enable the transformations.
The results after using Cimple
Cimple is used as a template library generator and then the performance gains are reported. The peak system throughput increased from 1.3× on HashTable to 2.5× on SkipList iteration. It speedups of the time to complete a batch of queries on one thread range from 1.2× on HashTable to 6.4× on BinaryTree.
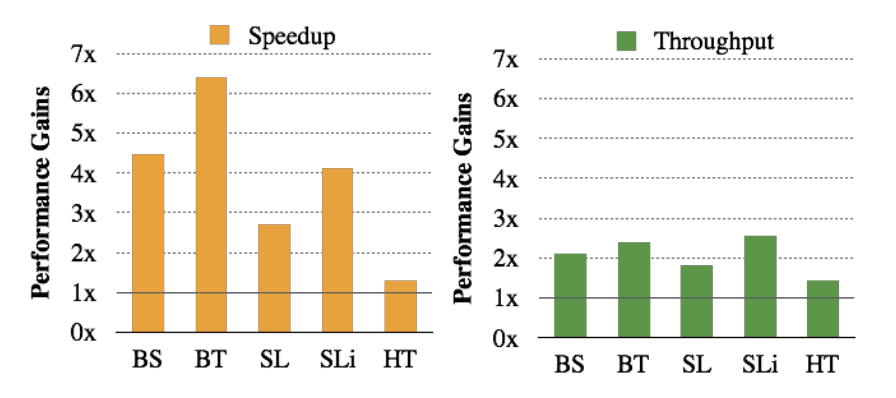
Source: Cimple: Instruction and Memory Level Parallelism
Where the abbreviations are Binary Search (BS), Binary Tree (BT), Skip List (SL), Skip List iterator (SLi), and Hash Table (HT).
Cimple reaches 2.5× throughput gains over hardware multithreading on a multi-core processor and 6.4× single thread. This is the resulting graph.
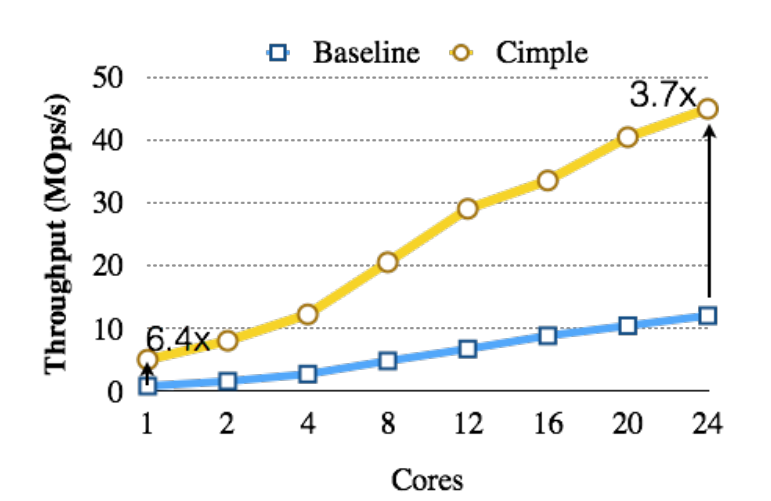
Source: Cimple: Instruction and Memory Level Parallelism
The final conclusions from the work is that Cimple is fast, maintainable, and portable. The paper will appear in PACT’18 to be held 1st to 4th November 2018. You can read it on the arXiv website.
Read next
KotlinConf 2018: Kotlin 1.3 RC out and Kotlin/Native hits beta
Facebook releases Skiplang, a general purpose programming language