
Design patterns have provided many ways to simplify the development of software applications. Now that organizations are beginning to tackle applications that leverage new sources and types of big data, design patterns for big data are needed. These big data design patterns aim to reduce complexity, boost the performance of integration and improve the results of working with new and larger forms of data.
This article intends to introduce readers to the common big data design patterns based on various data layers such as data sources and ingestion layer, data storage layer and data access layer.
This article is an excerpt from Architectural Patterns by Pethuru Raj, Anupama Raman, and Harihara Subramanian. In this book, you will learn the importance of architectural and design patterns in business-critical applications.
Data sources and ingestion layer

Enterprise big data systems face a variety of data sources with non-relevant information (noise) alongside relevant (signal) data. Noise ratio is very high compared to signals, and so filtering the noise from the pertinent information, handling high volumes, and the velocity of data is significant. This is the responsibility of the ingestion layer. The common challenges in the ingestion layers are as follows:
- Multiple data source load and prioritization
- Ingested data indexing and tagging
- Data validation and cleansing
- Data transformation and compression

The preceding diagram depicts the building blocks of the ingestion layer and its various components. We need patterns to address the challenges of data sources to ingestion layer communication that takes care of performance, scalability, and availability requirements.
In this section, we will discuss the following ingestion and streaming patterns and how they help to address the challenges in ingestion layers. We will also touch upon some common workload patterns as well, including:
- Multisource extractor
- Multidestination
- Protocol converter
- Just-in-time (JIT) transformation
- Real-time streaming pattern
Multisource extractor
An approach to ingesting multiple data types from multiple data sources efficiently is termed a Multisource extractor. Efficiency represents many factors, such as data velocity, data size, data frequency, and managing various data formats over an unreliable network, mixed network bandwidth, different technologies, and systems:

The multisource extractor system ensures high availability and distribution. It also confirms that the vast volume of data gets segregated into multiple batches across different nodes. The single node implementation is still helpful for lower volumes from a handful of clients, and of course, for a significant amount of data from multiple clients processed in batches. Partitioning into small volumes in clusters produces excellent results.
Data enrichers help to do initial data aggregation and data cleansing. Enrichers ensure file transfer reliability, validations, noise reduction, compression, and transformation from native formats to standard formats. Collection agent nodes represent intermediary cluster systems, which helps final data processing and data loading to the destination systems.
The following are the benefits of the multisource extractor:
- Provides reasonable speed for storing and consuming the data
- Better data prioritization and processing
- Drives improved business decisions
- Decoupled and independent from data production to data consumption
- Data semantics and detection of changed data
- Scaleable and fault tolerance system
The following are the impacts of the multisource extractor:
- Difficult or impossible to achieve near real-time data processing
- Need to maintain multiple copies in enrichers and collection agents, leading to data redundancy and mammoth data volume in each node
- High availability trade-off with high costs to manage system capacity growth
- Infrastructure and configuration complexity increases to maintain batch processing
Multidestination pattern
In multisourcing, we saw the raw data ingestion to HDFS, but in most common cases the enterprise needs to ingest raw data not only to new HDFS systems but also to their existing traditional data storage, such as Informatica or other analytics platforms. In such cases, the additional number of data streams leads to many challenges, such as storage overflow, data errors (also known as data regret), an increase in time to transfer and process data, and so on.
The multidestination pattern is considered as a better approach to overcome all of the challenges mentioned previously. This pattern is very similar to multisourcing until it is ready to integrate with multiple destinations (refer to the following diagram). The router publishes the improved data and then broadcasts it to the subscriber destinations (already registered with a publishing agent on the router). Enrichers can act as publishers as well as subscribers:

Deploying routers in the cluster environment is also recommended for high volumes and a large number of subscribers.
The following are the benefits of the multidestination pattern:
- Highly scalable, flexible, fast, resilient to data failure, and cost-effective
- Organization can start to ingest data into multiple data stores, including its existing RDBMS as well as NoSQL data stores
- Allows you to use simple query language, such as Hive and Pig, along with traditional analytics
- Provides the ability to partition the data for flexible access and decentralized processing
- Possibility of decentralized computation in the data nodes
- Due to replication on HDFS nodes, there are no data regrets
- Self-reliant data nodes can add more nodes without any delay
The following are the impacts of the multidestination pattern:
- Needs complex or additional infrastructure to manage distributed nodes
- Needs to manage distributed data in secured networks to ensure data security
- Needs enforcement, governance, and stringent practices to manage the integrity and consistency of data
Protocol converter
This is a mediatory approach to provide an abstraction for the incoming data of various systems. The protocol converter pattern provides an efficient way to ingest a variety of unstructured data from multiple data sources and different protocols.
The message exchanger handles synchronous and asynchronous messages from various protocol and handlers as represented in the following diagram. It performs various mediator functions, such as file handling, web services message handling, stream handling, serialization, and so on:

In the protocol converter pattern, the ingestion layer holds responsibilities such as identifying the various channels of incoming events, determining incoming data structures, providing mediated service for multiple protocols into suitable sinks, providing one standard way of representing incoming messages, providing handlers to manage various request types, and providing abstraction from the incoming protocol layers.
Just-In-Time (JIT) transformation pattern
The JIT transformation pattern is the best fit in situations where raw data needs to be preloaded in the data stores before the transformation and processing can happen. In this kind of business case, this pattern runs independent preprocessing batch jobs that clean, validate, corelate, and transform, and then store the transformed information into the same data store (HDFS/NoSQL); that is, it can coexist with the raw data:

The preceding diagram depicts the datastore with raw data storage along with transformed datasets. Please note that the data enricher of the multi-data source pattern is absent in this pattern and more than one batch job can run in parallel to transform the data as required in the big data storage, such as HDFS, Mongo DB, and so on.
Real-time streaming pattern
Most modern businesses need continuous and real-time processing of unstructured data for their enterprise big data applications.
Real-time streaming implementations need to have the following characteristics:
- Minimize latency by using large in-memory
- Event processors are atomic and independent of each other and so are easily scalable
- Provide API for parsing the real-time information
- Independent deployable script for any node and no centralized master node implementation
The real-time streaming pattern suggests introducing an optimum number of event processing nodes to consume different input data from the various data sources and introducing listeners to process the generated events (from event processing nodes) in the event processing engine:

Event processing engines (event processors) have a sizeable in-memory capacity, and the event processors get triggered by a specific event. The trigger or alert is responsible for publishing the results of the in-memory big data analytics to the enterprise business process engines and, in turn, get redirected to various publishing channels (mobile, CIO dashboards, and so on).
Big data workload patterns
Workload patterns help to address data workload challenges associated with different domains and business cases efficiently. The big data design pattern manifests itself in the solution construct, and so the workload challenges can be mapped with the right architectural constructs and thus service the workload.
The following diagram depicts a snapshot of the most common workload patterns and their associated architectural constructs:

Workload design patterns help to simplify and decompose the business use cases into workloads. Then those workloads can be methodically mapped to the various building blocks of the big data solution architecture.
Data storage layer
Data storage layer is responsible for acquiring all the data that are gathered from various data sources and it is also liable for converting (if needed) the collected data to a format that can be analyzed. The following sections discuss more on data storage layer patterns.
ACID versus BASE versus CAP
Traditional RDBMS follows atomicity, consistency, isolation, and durability (ACID) to provide reliability for any user of the database. However, searching high volumes of big data and retrieving data from those volumes consumes an enormous amount of time if the storage enforces ACID rules. So, big data follows basically available, soft state, eventually consistent (BASE), a phenomenon for undertaking any search in big data space.
Database theory suggests that the NoSQL big database may predominantly satisfy two properties and relax standards on the third, and those properties are consistency, availability, and partition tolerance (CAP).
With the ACID, BASE, and CAP paradigms, the big data storage design patterns have gained momentum and purpose. We will look at those patterns in some detail in this section. The patterns are:
- Façade pattern
- NoSQL pattern
- Polyglot pattern
Façade pattern
This pattern provides a way to use existing or traditional existing data warehouses along with big data storage (such as Hadoop). It can act as a façade for the enterprise data warehouses and business intelligence tools.
In the façade pattern, the data from the different data sources get aggregated into HDFS before any transformation, or even before loading to the traditional existing data warehouses:

The façade pattern allows structured data storage even after being ingested to HDFS in the form of structured storage in an RDBMS, or in NoSQL databases, or in a memory cache. The façade pattern ensures reduced data size, as only the necessary data resides in the structured storage, as well as faster access from the storage.
NoSQL pattern
This pattern entails getting NoSQL alternatives in place of traditional RDBMS to facilitate the rapid access and querying of big data. The NoSQL database stores data in a columnar, non-relational style. It can store data on local disks as well as in HDFS, as it is HDFS aware. Thus, data can be distributed across data nodes and fetched very quickly.
Let’s look at four types of NoSQL databases in brief:
- Column-oriented DBMS: Simply called a columnar store or big table data store, it has a massive number of columns for each tuple. Each column has a column key. Column family qualifiers represent related columns so that the columns and the qualifiers are retrievable, as each column has a column key as well. These data stores are suitable for fast writes.

- Key-value pair database: A key-value database is a data store that, when presented with a simple string (key), returns an arbitrarily large data (value). The key is bound to the value until it gets a new value assigned into or from a database. The key-value data store does not need to have a query language. It provides a way to add and remove key-value pairs. A key-value store is a dictionary kind of data store, where it has a list of words and each word represents one or more definitions.
- Graph database: This is a representation of a system that contains a sequence of nodes and relationships that creates a graph when combined. A graph represents three data fields: nodes, relationships, and properties. Some types of graph store are referred to as triple stores because of their node-relationship-node structure. You may be familiar with applications that provide evaluations of similar or likely characteristics as part of the search (for example, a user bought this item also bought… is a good illustration of graph store implementations).

- Document database: We can represent a graph data store as a tree structure. Document trees have a single root element or sometimes even multiple root elements as well. Note that there is a sequence of branches, sub-branches, and values beneath the root element. Each branch can have an expression or relative path to determine the traversal path from the origin node (root) and to any given branch, sub-branch, or value. Each branch may have a value associated with that branch. Sometimes the existence of a branch of the tree has a specific meaning, and sometimes a branch must have a given value to be interpreted correctly.

The following table summarizes some of the NoSQL use cases, providers, tools and scenarios that might need NoSQL pattern considerations. Most of this pattern implementation is already part of various vendor implementations, and they come as out-of-the-box implementations and as plug and play so that any enterprise can start leveraging the same quickly.
|
NoSQL DB to Use
|
Scenario
|
Vendor / Application / Tools
|
| Columnar database | Application that needs to fetch entire related columnar family based on a given string: for example, search engines | SAP HANA / IBM DB2 BLU / ExtremeDB / EXASOL / IBM Informix / MS SQL Server / MonetDB |
| Key Value Pair database | Needle in haystack applications (refer to the Big data workload patterns given in this section) | Redis / Oracle NoSQL DB / Linux DBM / Dynamo / Cassandra |
| Graph database | Recommendation engine: application that provides evaluation of Similar to / Like: for example, User that bought this item also bought | ArangoDB / Cayley / DataStax / Neo4j / Oracle Spatial and Graph / Apache Orient DB / Teradata Aster |
| Document database | Applications that evaluate churn management of social media data or non-enterprise data | Couch DB / Apache Elastic Search / Informix / Jackrabbit / Mongo DB / Apache SOLR |
Polyglot pattern
Traditional (RDBMS) and multiple storage types (files, CMS, and so on) coexist with big data types (NoSQL/HDFS) to solve business problems.
Most modern business cases need the coexistence of legacy databases. At the same time, they would need to adopt the latest big data techniques as well. Replacing the entire system is not viable and is also impractical. The polyglot pattern provides an efficient way to combine and use multiple types of storage mechanisms, such as Hadoop, and RDBMS. Big data appliances coexist in a storage solution:

The preceding diagram represents the polyglot pattern way of storing data in different storage types, such as RDBMS, key-value stores, NoSQL database, CMS systems, and so on. Unlike the traditional way of storing all the information in one single data source, polyglot facilitates any data coming from all applications across multiple sources (RDBMS, CMS, Hadoop, and so on) into different storage mechanisms, such as in-memory, RDBMS, HDFS, CMS, and so on.
Data access layer
Data access in traditional databases involves JDBC connections and HTTP access for documents. However, in big data, the data access with conventional method does take too much time to fetch even with cache implementations, as the volume of the data is so high.
So we need a mechanism to fetch the data efficiently and quickly, with a reduced development life cycle, lower maintenance cost, and so on.
Data access patterns mainly focus on accessing big data resources of two primary types:
- End-to-end user-driven API (access through simple queries)
- Developer API (access provision through API methods)
In this section, we will discuss the following data access patterns that held efficient data access, improved performance, reduced development life cycles, and low maintenance costs for broader data access:
- Connector pattern
- Lightweight stateless pattern
- Service locator pattern
- Near real-time pattern
- Stage transform pattern

The preceding diagram represents the big data architecture layouts where the big data access patterns help data access. We discuss the whole of that mechanism in detail in the following sections.
Connector pattern
The developer API approach entails fast data transfer and data access services through APIs. It creates optimized data sets for efficient loading and analysis. Some of the big data appliances abstract data in NoSQL DBs even though the underlying data is in HDFS, or a custom implementation of a filesystem so that the data access is very efficient and fast.
The connector pattern entails providing developer API and SQL like query language to access the data and so gain significantly reduced development time. As we saw in the earlier diagram, big data appliances come with connector pattern implementation. The big data appliance itself is a complete big data ecosystem and supports virtualization, redundancy, replication using protocols (RAID), and some appliances host NoSQL databases as well.
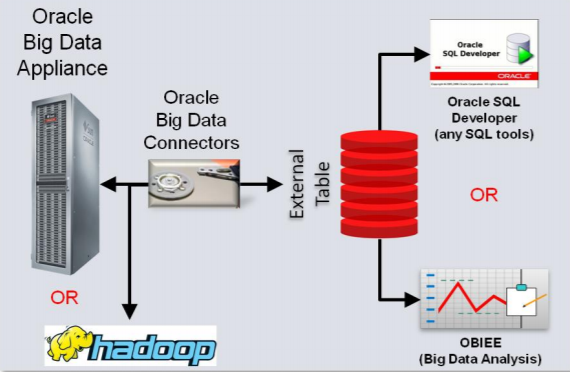
The preceding diagram shows a sample connector implementation for Oracle big data appliances. The data connector can connect to Hadoop and the big data appliance as well. It is an example of a custom implementation that we described earlier to facilitate faster data access with less development time.
Lightweight stateless pattern
This pattern entails providing data access through web services, and so it is independent of platform or language implementations. The data is fetched through restful HTTP calls, making this pattern the most sought after in cloud deployments. WebHDFS and HttpFS are examples of lightweight stateless pattern implementation for HDFS HTTP access. It uses the HTTP REST protocol. The HDFS system exposes the REST API (web services) for consumers who analyze big data. This pattern reduces the cost of ownership (pay-as-you-go) for the enterprise, as the implementations can be part of an integration Platform as a Service (iPaaS):

The preceding diagram depicts a sample implementation for HDFS storage that exposes HTTP access through the HTTP web interface.
Near real-time pattern
For any enterprise to implement real-time data access or near real-time data access, the key challenges to be addressed are:
- Rapid determination of data: Ensure rapid determination of data and make swift decisions (within a few seconds, not in minutes) before the data becomes meaningless
- Rapid analysis: Ability to analyze the data in real time and spot anomalies and relate them to business events, provide visualization, and generate alerts at the moment that the data arrived
Some examples of systems that would need real-time data analysis are:
- Radar systems
- Customer services applications
- ATMs
- Social media platforms
- Intrusion detection systems
Storm and in-memory applications such as Oracle Coherence, Hazelcast IMDG, SAP HANA, TIBCO, Software AG (Terracotta), VMware, and Pivotal GemFire XD are some of the in-memory computing vendor/technology platforms that can implement near real-time data access pattern applications:

As shown in the preceding diagram, with multi-cache implementation at the ingestion phase, and with filtered, sorted data in multiple storage destinations (here one of the destinations is a cache), one can achieve near real-time access. The cache can be of a NoSQL database, or it can be any in-memory implementations tool, as mentioned earlier. The preceding diagram depicts a typical implementation of a log search with SOLR as a search engine.
Stage transform pattern
In the big data world, a massive volume of data can get into the data store. However, all of the data is not required or meaningful in every business case. The stage transform pattern provides a mechanism for reducing the data scanned and fetches only relevant data.
HDFS has raw data and business-specific data in a NoSQL database that can provide application-oriented structures and fetch only the relevant data in the required format:

Combining the stage transform pattern and the NoSQL pattern is the recommended approach in cases where a reduced data scan is the primary requirement. The preceding diagram depicts one such case for a recommendation engine where we need a significant reduction in the amount of data scanned for an improved customer experience.
The implementation of the virtualization of data from HDFS to a NoSQL database, integrated with a big data appliance, is a highly recommended mechanism for rapid or accelerated data fetch.
We discussed big data design patterns by layers such as data sources and ingestion layer, data storage layer and data access layer.
To know more about patterns associated with object-oriented, component-based, client-server, and cloud architectures, read our book Architectural Patterns.