This article by Nishant Garg, the author of the book Learning Apache Kafka Second Edition, focuses on the details of Writing Consumers. Consumers are the applications that consume the messages published by Kafka producers and process the data extracted from them. Like producers, consumers can also be different in nature, such as applications doing real-time or near real-time analysis, applications with NoSQL or data warehousing solutions, backend services, consumers for Hadoop, or other subscriber-based solutions. These consumers can also be implemented in different languages such as Java, C, and Python.
(For more resources related to this topic, see here.)
In this article, we will focus on the following topics:
At the end of the article, we will explore some of the important properties that can be set for a Kafka consumer. So, let's start.
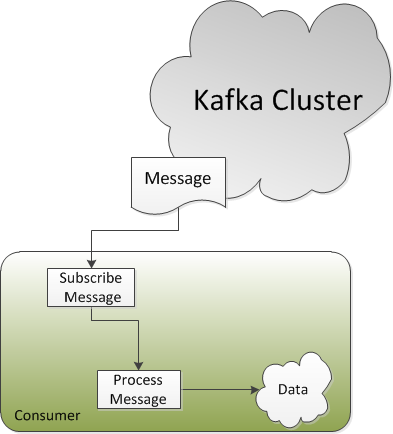
The preceding diagram explains the high-level working of the Kafka consumer when consuming the messages. The consumer subscribes to the message consumption from a specific topic on the Kafka broker. The consumer then issues a fetch request to the lead broker to consume the message partition by specifying the message offset (the beginning position of the message offset). Therefore, the Kafka consumer works in the pull model and always pulls all available messages after its current position in the Kafka log (the Kafka internal data representation).
While subscribing, the consumer connects to any of the live nodes and requests metadata about the leaders for the partitions of a topic. This allows the consumer to communicate directly with the lead broker receiving the messages. Kafka topics are divided into a set of ordered partitions and each partition is consumed by one consumer only. Once a partition is consumed, the consumer changes the message offset to the next partition to be consumed. This represents the states about what has been consumed and also provides the flexibility of deliberately rewinding back to an old offset and re-consuming the partition. In the next few sections, we will discuss the API provided by Kafka for writing Java-based custom consumers.
All the Kafka classes referred to in this article are actually written in Scala.
Kafka consumer APIs
Kafka provides two types of API for Java consumers:
High-level API
Low-level API
The high-level consumer API
The high-level consumer API is used when only data is needed and the handling of message offsets is not required. This API hides broker details from the consumer and allows effortless communication with the Kafka cluster by providing an abstraction over the low-level implementation. The high-level consumer stores the last offset (the position within the message partition where the consumer left off consuming the message), read from a specific partition in Zookeeper. This offset is stored based on the consumer group name provided to Kafka at the beginning of the process.
The consumer group name is unique and global across the Kafka cluster and any new consumers with an in-use consumer group name may cause ambiguous behavior in the system. When a new process is started with the existing consumer group name, Kafka triggers a rebalance between the new and existing process threads for the consumer group. After the rebalance, some messages that are intended for a new process may go to an old process, causing unexpected results. To avoid this ambiguous behavior, any existing consumers should be shut down before starting new consumers for an existing consumer group name.
The following are the classes that are imported to write Java-based basic consumers using the high-level consumer API for a Kafka cluster:
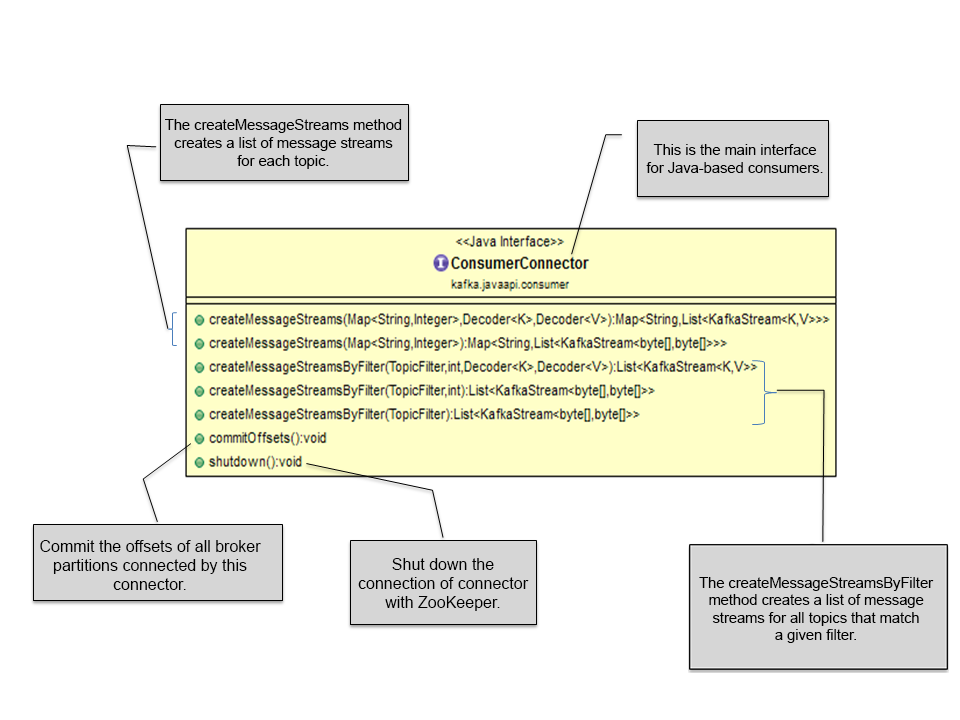
ConsumerConnector: Kafka provides the ConsumerConnector interface (interface ConsumerConnector) that is further implemented by the ZookeeperConsumerConnector class (kafka.javaapi.consumer.ZookeeperConsumerConnector). This class is responsible for all the interaction a consumer has with ZooKeeper.
The following is the class diagram for the ConsumerConnector class:
KafkaStream: Objects of the kafka.consumer.KafkaStream class are returned by the createMessageStreams call from the ConsumerConnector implementation. This list of the KafkaStream objects is returned for each topic, which can further create an iterator over messages in the stream. The following is the Scala-based class declaration:
class KafkaStream[K,V](private val queue:
BlockingQueue[FetchedDataChunk],
consumerTimeoutMs: Int,
private val keyDecoder: Decoder[K],
private val valueDecoder: Decoder[V],
val clientId: String)
Here, the parameters K and V specify the type for the partition key and message value, respectively.
In the create call from the ConsumerConnector class, clients can specify the number of desired streams, where each stream object is used for single-threaded processing. These stream objects may represent the merging of multiple unique partitions.
ConsumerConfig: The kafka.consumer.ConsumerConfig class encapsulates the property values required for establishing the connection with ZooKeeper, such as ZooKeeper URL, ZooKeeper session timeout, and ZooKeeper sink time. It also contains the property values required by the consumer such as group ID and so on.
A high-level API-based working consumer example is discussed after the next section.
The low-level consumer API
The high-level API does not allow consumers to control interactions with brokers. Also known as "simple consumer API", the low-level consumer API is stateless and provides fine grained control over the communication between Kafka broker and the consumer. It allows consumers to set the message offset with every request raised to the broker and maintains the metadata at the consumer's end. This API can be used by both online as well as offline consumers such as Hadoop. These types of consumers can also perform multiple reads for the same message or manage transactions to ensure the message is consumed only once.
Compared to the high-level consumer API, developers need to put in extra effort to gain low-level control within consumers by keeping track of offsets, figuring out the lead broker for the topic and partition, handling lead broker changes, and so on.
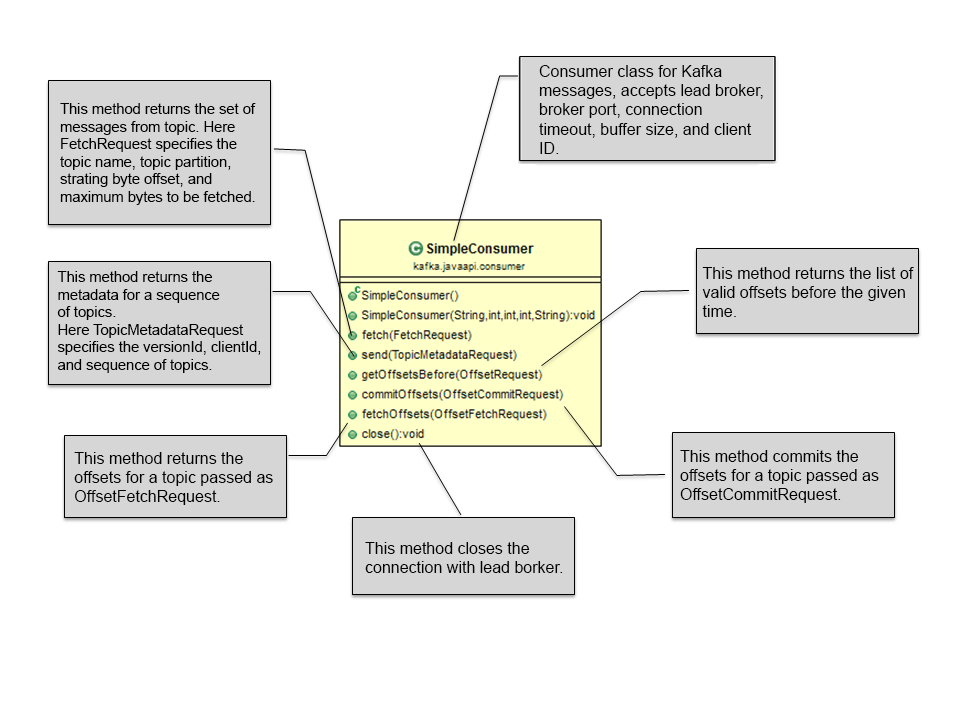
In the low-level consumer API, consumers first query the live broker to find out the details about the lead broker. Information about the live broker can be passed on to the consumers either using a properties file or from the command line. The topicsMetadata() method of the kafka.javaapi.TopicMetadataResponse class is used to find out metadata about the topic of interest from the lead broker. For message partition reading, the kafka.api.OffsetRequest class defines two constants: EarliestTime and LatestTime, to find the beginning of the data in the logs and the new messages stream. These constants also help consumers to track which messages are already read.
The main class used within the low-level consumer API is the SimpleConsumer (kafka.javaapi.consumer.SimpleConsumer) class. The following is the class diagram for the SimpleConsumer class:
A simple consumer class provides a connection to the lead broker for fetching the messages from the topic and methods to get the topic metadata and the list of offsets.
A few more important classes for building different request objects are FetchRequest (kafka.api.FetchRequest), OffsetRequest (kafka.javaapi.OffsetRequest), OffsetFetchRequest (kafka.javaapi.OffsetFetchRequest), OffsetCommitRequest (kafka.javaapi.OffsetCommitRequest), and TopicMetadataRequest (kafka.javaapi.TopicMetadataRequest).
Now we will start writing a single-threaded simple Java consumer developed using the high-level consumer API for consuming the messages from a topic. This SimpleHLConsumer class is used to fetch a message from a specific topic and consume it, assuming that there is a single partition within the topic.
Importing classes
As a first step, we need to import the following classes:
As a next step, we need to define properties for making a connection with Zookeeper and pass these properties to the Kafka consumer using the following code:
Properties props = new Properties();
props.put("zookeeper.connect", "localhost:2181");
props.put("group.id", "testgroup");
props.put("zookeeper.session.timeout.ms", "500");
props.put("zookeeper.sync.time.ms", "250");
props.put("auto.commit.interval.ms", "1000");
new ConsumerConfig(props);
Now let us see the major properties mentioned in the code:
zookeeper.connect: This property specifies the ZooKeeper <node:port> connection detail that is used to find the Zookeeper running instance in the cluster. In the Kafka cluster, Zookeeper is used to store offsets of messages consumed for a specific topic and partition by this consumer group.
group.id: This property specifies the name for the consumer group shared by all the consumers within the group. This is also the process name used by Zookeeper to store offsets.
zookeeper.session.timeout.ms: This property specifies the Zookeeper session timeout in milliseconds and represents the amount of time Kafka will wait for Zookeeper to respond to a request before giving up and continuing to consume messages.
zookeeper.sync.time.ms: This property specifies the ZooKeeper sync time in milliseconds between the ZooKeeper leader and the followers.
auto.commit.interval.ms: This property defines the frequency in milliseconds at which consumer offsets get committed to Zookeeper.
Reading messages from a topic and printing them
As a final step, we need to read the message using the following code:
Map<String, Integer> topicMap = new HashMap<String, Integer>();
// 1 represents the single thread
topicCount.put(topic, new Integer(1));
Map<String, List<KafkaStream<byte[], byte[]>>> consumerStreamsMap = consumer.createMessageStreams(topicMap);
// Get the list of message streams for each topic, using the default decoder.
List<KafkaStream<byte[], byte[]>>streamList = consumerStreamsMap.get(topic);
for (final KafkaStream <byte[], byte[]> stream : streamList) {
ConsumerIterator<byte[], byte[]> consumerIte = stream.iterator();
while (consumerIte.hasNext())
System.out.println("Message from Single Topic :: "
+ new String(consumerIte.next().message()));
}
So the complete program will look like the following code:
package kafka.examples.ch5;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
public class SimpleHLConsumer {
private final ConsumerConnector consumer;
private final String topic;
public SimpleHLConsumer(String zookeeper, String groupId, String topic) {
consumer = kafka.consumer.Consumer
.createJavaConsumerConnector(createConsumerConfig(zookeeper,
groupId));
this.topic = topic;
}
private static ConsumerConfig createConsumerConfig(String zookeeper,
String groupId) {
Properties props = new Properties();
props.put("zookeeper.connect", zookeeper);
props.put("group.id", groupId);
props.put("zookeeper.session.timeout.ms", "500");
props.put("zookeeper.sync.time.ms", "250");
props.put("auto.commit.interval.ms", "1000");
return new ConsumerConfig(props);
}
public void testConsumer() {
Map<String, Integer> topicMap = new HashMap<String, Integer>();
// Define single thread for topic
topicMap.put(topic, new Integer(1));
Map<String, List<KafkaStream<byte[], byte[]>>> consumerStreamsMap =
consumer.createMessageStreams(topicMap);
List<KafkaStream<byte[], byte[]>> streamList = consumerStreamsMap
.get(topic);
for (final KafkaStream<byte[], byte[]> stream : streamList) {
ConsumerIterator<byte[], byte[]> consumerIte = stream.iterator();
while (consumerIte.hasNext())
System.out.println("Message from Single Topic :: "
+ new String(consumerIte.next().message()));
}
if (consumer != null)
consumer.shutdown();
}
public static void main(String[] args) {
String zooKeeper = args[0];
String groupId = args[1];
String topic = args[2];
SimpleHLConsumer simpleHLConsumer = new SimpleHLConsumer(
zooKeeper, groupId, topic);
simpleHLConsumer.testConsumer();
}
}
Before running this, make sure you have created the topic kafkatopic from the command line:
Before compiling and running a Java-based Kafka program in the console, make sure you download the slf4j-1.7.7.tar.gz file from http://www.slf4j.org/download.html and copy slf4j-log4j12-1.7.7.jar contained within slf4j-1.7.7.tar.gz to the /opt/kafka_2.9.2-0.8.1.1/libs directory. Also add all the libraries available in /opt/kafka_2.9.2-0.8.1.1/libs to the classpath using the following commands:
The previous example is a very basic example of a consumer that consumes messages from a single broker with no explicit partitioning of messages within the topic. Let's jump to the next level and write another program that consumes messages from multiple partitions connecting to single/multiple topics.
A multithreaded, high-level, consumer-API-based design is usually based on the number of partitions in the topic and follows a one-to-one mapping approach between the thread and the partitions within the topic. For example, if four partitions are defined for any topic, as a best practice, only four threads should be initiated with the consumer application to read the data; otherwise, some conflicting behavior, such as threads never receiving a message or a thread receiving messages from multiple partitions, may occur. Also, receiving multiple messages will not guarantee that the messages will be placed in order. For example, a thread may receive two messages from the first partition and three from the second partition, then three more from the first partition, followed by some more from the first partition, even if the second partition has data available.
Let's move further on.
Importing classes
As a first step, we need to import the following classes:
As the next step, we need to define properties for making a connection with Zookeeper and pass these properties to the Kafka consumer using the following code:
Properties props = new Properties();
props.put("zookeeper.connect", "localhost:2181");
props.put("group.id", "testgroup");
props.put("zookeeper.session.timeout.ms", "500");
props.put("zookeeper.sync.time.ms", "250");
props.put("auto.commit.interval.ms", "1000");
new ConsumerConfig(props);
The preceding properties have already been discussed in the previous example. For more details on Kafka consumer properties, refer to the last section of this article.
Reading the message from threads and printing it
The only difference in this section from the previous section is that we first create a thread pool and get the Kafka streams associated with each thread within the thread pool, as shown in the following code:
// Define thread count for each topic
topicMap.put(topic, new Integer(threadCount));
// Here we have used a single topic but we can also add
// multiple topics to topicCount MAP
Map<String, List<KafkaStream<byte[], byte[]>>> consumerStreamsMap
= consumer.createMessageStreams(topicMap);
List<KafkaStream<byte[], byte[]>> streamList = consumerStreamsMap.get(topic);
// Launching the thread pool
executor = Executors.newFixedThreadPool(threadCount);
The complete program listing for the multithread Kafka consumer based on the Kafka high-level consumer API is as follows:
package kafka.examples.ch5;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
public class MultiThreadHLConsumer {
private ExecutorService executor;
private final ConsumerConnector consumer;
private final String topic;
public MultiThreadHLConsumer(String zookeeper, String groupId, String topic) {
consumer = kafka.consumer.Consumer
.createJavaConsumerConnector(createConsumerConfig(zookeeper, groupId));
this.topic = topic;
}
private static ConsumerConfig createConsumerConfig(String zookeeper,
String groupId) {
Properties props = new Properties();
props.put("zookeeper.connect", zookeeper);
props.put("group.id", groupId);
props.put("zookeeper.session.timeout.ms", "500");
props.put("zookeeper.sync.time.ms", "250");
props.put("auto.commit.interval.ms", "1000");
return new ConsumerConfig(props);
}
public void shutdown() {
if (consumer != null)
consumer.shutdown();
if (executor != null)
executor.shutdown();
}
public void testMultiThreadConsumer(int threadCount) {
Map<String, Integer> topicMap = new HashMap<String, Integer>();
// Define thread count for each topic
topicMap.put(topic, new Integer(threadCount));
// Here we have used a single topic but we can also add
// multiple topics to topicCount MAP
Map<String, List<KafkaStream<byte[], byte[]>>> consumerStreamsMap =
consumer.createMessageStreams(topicMap);
List<KafkaStream<byte[], byte[]>> streamList = consumerStreamsMap
.get(topic);
// Launching the thread pool
executor = Executors.newFixedThreadPool(threadCount);
// Creating an object messages consumption
int count = 0;
for (final KafkaStream<byte[], byte[]> stream : streamList) {
final int threadNumber = count;
executor.submit(new Runnable() {
public void run() {
ConsumerIterator<byte[], byte[]> consumerIte = stream.iterator();
while (consumerIte.hasNext())
System.out.println("Thread Number " + threadNumber + ": "
+ new String(consumerIte.next().message()));
System.out.println("Shutting down Thread Number: " +
threadNumber);
}
});
count++;
}
if (consumer != null)
consumer.shutdown();
if (executor != null)
executor.shutdown();
}
public static void main(String[] args) {
String zooKeeper = args[0];
String groupId = args[1];
String topic = args[2];
int threadCount = Integer.parseInt(args[3]);
MultiThreadHLConsumer multiThreadHLConsumer =
new MultiThreadHLConsumer(zooKeeper, groupId, topic);
multiThreadHLConsumer.testMultiThreadConsumer(threadCount);
try {
Thread.sleep(10000);
} catch (InterruptedException ie) {
}
multiThreadHLConsumer.shutdown();
}
}
Compile the preceding program, and before running it, read the following tip.
Before we run this program, we need to make sure our cluster is running as a multi-broker cluster (comprising either single or multiple nodes).
Once your multi-broker cluster is up, create a topic with four partitions and set the replication factor to 2 before running this program using the following command:
The following lists of a few important properties that can be configured for high-level, consumer-API-based Kafka consumers. The Scala class kafka.consumer.ConsumerConfig provides implementation-level details for consumer configurations. For a complete list, visit http://kafka.apache.org/documentation.html#consumerconfigs.
Property name
Unlock access to the largest independent learning library in Tech for FREE!
Get unlimited access to 7500+ expert-authored eBooks and video courses covering every tech area you can think of.
Renews at $19.99/month. Cancel anytime
Description
Default value
group.id
This property defines a unique identity for the set of consumers within the same consumer group.
consumer.id
This property is specified for the Kafka consumer and generated automatically if not defined.
null
zookeeper.connect
This property specifies the Zookeeper connection string, < hostname:port/chroot/path>. Kafka uses Zookeeper to store offsets of messages consumed for a specific topic and partition by the consumer group. /chroot/path defines the data location in a global zookeeper namespace.
client.id
The client.id value is specified by the Kafka client with each request and is used to identify the client making the requests.
${group.id}
zookeeper.session.timeout.ms
This property defines the time (in milliseconds) for a Kafka consumer to wait for a Zookeeper pulse before it is declared dead and rebalance is initiated.
6000
zookeeper.connection.timeout.ms
This value defines the maximum waiting time (in milliseconds) for the client to establish a connection with ZooKeeper.
6000
zookeeper.sync.time.ms
This property defines the time it takes to sync a Zookeeper follower with the Zookeeper leader (in milliseconds).
2000
auto.commit.enable
This property enables a periodical commit of message offsets to the Zookeeper that are already fetched by the consumer. In the event of consumer failures, these committed offsets are used as a starting position by the new consumers.
true
auto.commit.interval.ms
This property defines the frequency (in milliseconds) for the consumed offsets to get committed to ZooKeeper.
60 * 1000
auto.offset.reset
This property defines the offset value if an initial offset is available in Zookeeper or the offset is out of range. Possible values are:
largest: reset to largest offset
smallest: reset to smallest offset
anything else: throw an exception
largest
consumer.timeout.ms
This property throws an exception to the consumer if no message is available for consumption after the specified interval.
-1
Summary
In this article, we have learned how to write basic consumers and learned about some advanced levels of Java consumers that consume messages from partitions.

 United States
United States
 Great Britain
Great Britain
 India
India
 Germany
Germany
 France
France
 Canada
Canada
 Russia
Russia
 Spain
Spain
 Brazil
Brazil
 Australia
Australia
 Singapore
Singapore
 Canary Islands
Canary Islands
 Hungary
Hungary
 Ukraine
Ukraine
 Luxembourg
Luxembourg
 Estonia
Estonia
 Lithuania
Lithuania
 South Korea
South Korea
 Turkey
Turkey
 Switzerland
Switzerland
 Colombia
Colombia
 Taiwan
Taiwan
 Chile
Chile
 Norway
Norway
 Ecuador
Ecuador
 Indonesia
Indonesia
 New Zealand
New Zealand
 Cyprus
Cyprus
 Denmark
Denmark
 Finland
Finland
 Poland
Poland
 Malta
Malta
 Czechia
Czechia
 Austria
Austria
 Sweden
Sweden
 Italy
Italy
 Egypt
Egypt
 Belgium
Belgium
 Portugal
Portugal
 Slovenia
Slovenia
 Ireland
Ireland
 Romania
Romania
 Greece
Greece
 Argentina
Argentina
 Netherlands
Netherlands
 Bulgaria
Bulgaria
 Latvia
Latvia
 South Africa
South Africa
 Malaysia
Malaysia
 Japan
Japan
 Slovakia
Slovakia
 Philippines
Philippines
 Mexico
Mexico
 Thailand
Thailand