In this article by Erik Westra, author of the book Modular Programming with Python, we learn the concepts of wrappers. A wrapper is essentially a group of functions that call other functions to do the work.
Wrappers are used to simplify an interface, to make a confusing or badly designed API easier to use, to convert data formats into something more convenient, and to implement cross-language compatibility. Wrappers are also sometimes used to add testing and error-checking code to an existing API.
Let's take a look at a real-world application of a wrapper module. Imagine that you work for a large bank and have been asked to write a program to analyze fund transfers to help identify possible fraud. Your program receives information, in real time, about every inter-bank funds transfer that takes place. For each transfer, you are given:
The amount of the transfer
The ID of the branch in which the transfer took place
The identification code for the bank the funds are being sent to
Your task is to analyze the transfers over time to identify unusual patterns of activity. To do this, you need to calculate, for each of the last eight days, the total value of all transfers for each branch and destination bank. You can then compare the current day's totals against the average for the previous seven days, and flag any daily totals that are more than 50% above the average.
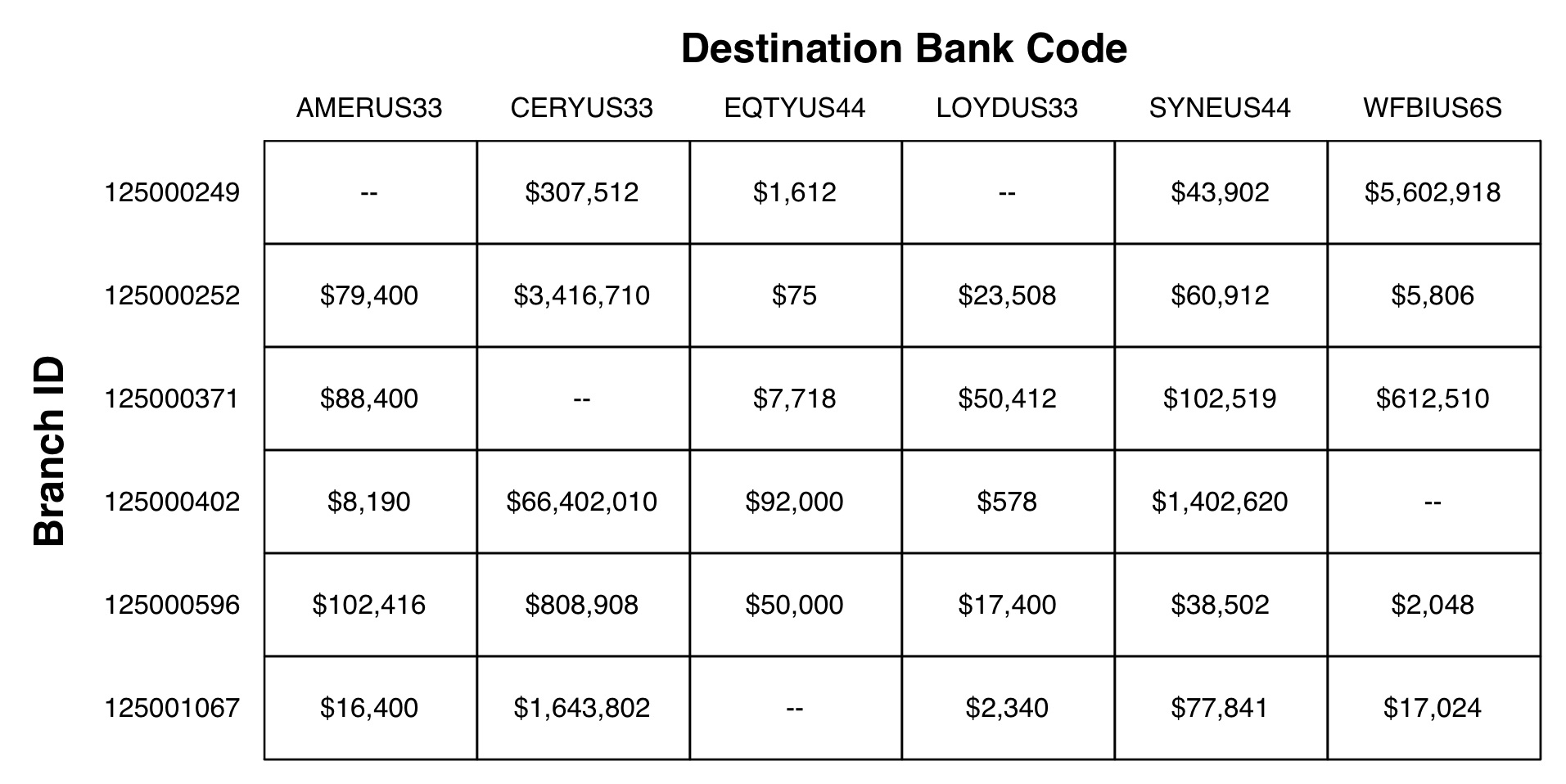
You start by deciding how to represent the total transfers for a day. Because you need to keep track of this for each branch and destination bank, it makes sense to store these totals in a two-dimensional array:
In Python, this type of two-dimensional array is represented as a list of lists:
Using these lists, you can calculate the totals for a given day by processing the transfers that took place on that particular day:
totals = []
for branch in branch_ids:
branch_totals = []
for bank in bank_codes:
branch_totals.append(0)
totals.append(branch_totals)
for transfer in transfers_for_day:
branch_index = branch_ids.index(transfer['branch'])
bank_index = bank_codes.index(transfer['dest_bank'])
totals[branch_index][bank_index] += transfer['amount']
So far so good. Once you have these totals for each day, you can then calculate the average and compare it against the current day's totals to identify the entries that are higher than 150% of the average.
Let's imagine that you've written this program and managed to get it working. When you start using it, though, you immediately discover a problem: your bank has over 5,000 branches, and there are more than 15,000 banks worldwide that your bank can transfer funds to—that's a total of 75 million combinations that you need to keep totals for, and as a result, your program is taking far too long to calculate the totals.
To make your program faster, you need to find a better way of handling large arrays of numbers. Fortunately, there's a library designed to do just this: NumPy.
NumPy is an excellent array-handling library. You can create huge arrays and perform sophisticated operations on an array with a single function call. Unfortunately, NumPy is also a dense and impenetrable library. It was designed and written for people with a deep understanding of mathematics. While there are many tutorials available and you can generally figure out how to use it, the code that uses NumPy is often hard to comprehend. For example, to calculate the average across multiple matrices would involve the following:
daily_totals = []
for totals in totals_to_average:
daily_totals.append(totals)
average = numpy.mean(numpy.array(daily_totals), axis=0)
Figuring out what that last line does would require a trip to the NumPy documentation. Because of the complexity of the code that uses NumPy, this is a perfect example of a situation where a wrapper module can be used: the wrapper module can provide an easier-to-use interface to NumPy, so your code can use it without being cluttered with complex and confusing function calls.
To work through this example, we'll start by installing the NumPy library. NumPy (http://www.numpy.org) runs on Mac OS X, Windows, and Linux machines. How you install it depends on which operating system you are using:
For MS Windows, you can download a Python "wheel" file for NumPy from http://www.lfd.uci.edu/~gohlke/pythonlibs/#numpy. Choose the pre-built version of NumPy that matches your operating system and the desired version of Python. To use the wheel file, use the pip install command, for example, pip install numpy-1.10.4+mkl-cp34-none-win32.whl.
If your computer runs Linux, you can use your Linux package manager to install NumPy. Alternatively, you can download and build NumPy in source code form.
To ensure that NumPy is working, fire up your Python interpreter and enter the following:
import numpy
a = numpy.array([[1, 2], [3, 4]])
print(a)
All going well, you should see a 2 x 2 matrix displayed:
[[1 2]
[3 4]]
Now that we have NumPy installed, let's start working on our wrapper module. Create a new Python source file, named numpy_wrapper.py, and enter the following into this file:
import numpy
That's all for now; we'll add functions to this wrapper module as we need them.
Next, create another Python source file, named detect_unusual_transfers.py, and enter the following into this file:
As you can see, we are hardwiring the bank and branch codes for our example; in a real program, these values would be loaded from somewhere, such as a file or a database. Since we don't have any available data, we will use the random module to create some. We are also changing the name of the numpy_wrapper module to make it easier to access from our code.
Let's now create some funds transfer data to process, using the random module:
days = [1, 2, 3, 4, 5, 6, 7, 8]
transfers = []
for i in range(10000):
day = random.choice(days)
bank_code = random.choice(BANK_CODES)
branch_id = random.choice(BRANCH_IDS)
amount = random.randint(1000, 1000000)
transfers.append((day, bank_code, branch_id, amount))
Here, we randomly select a day, a bank code, a branch ID, and an amount, storing these values in the transfers list.
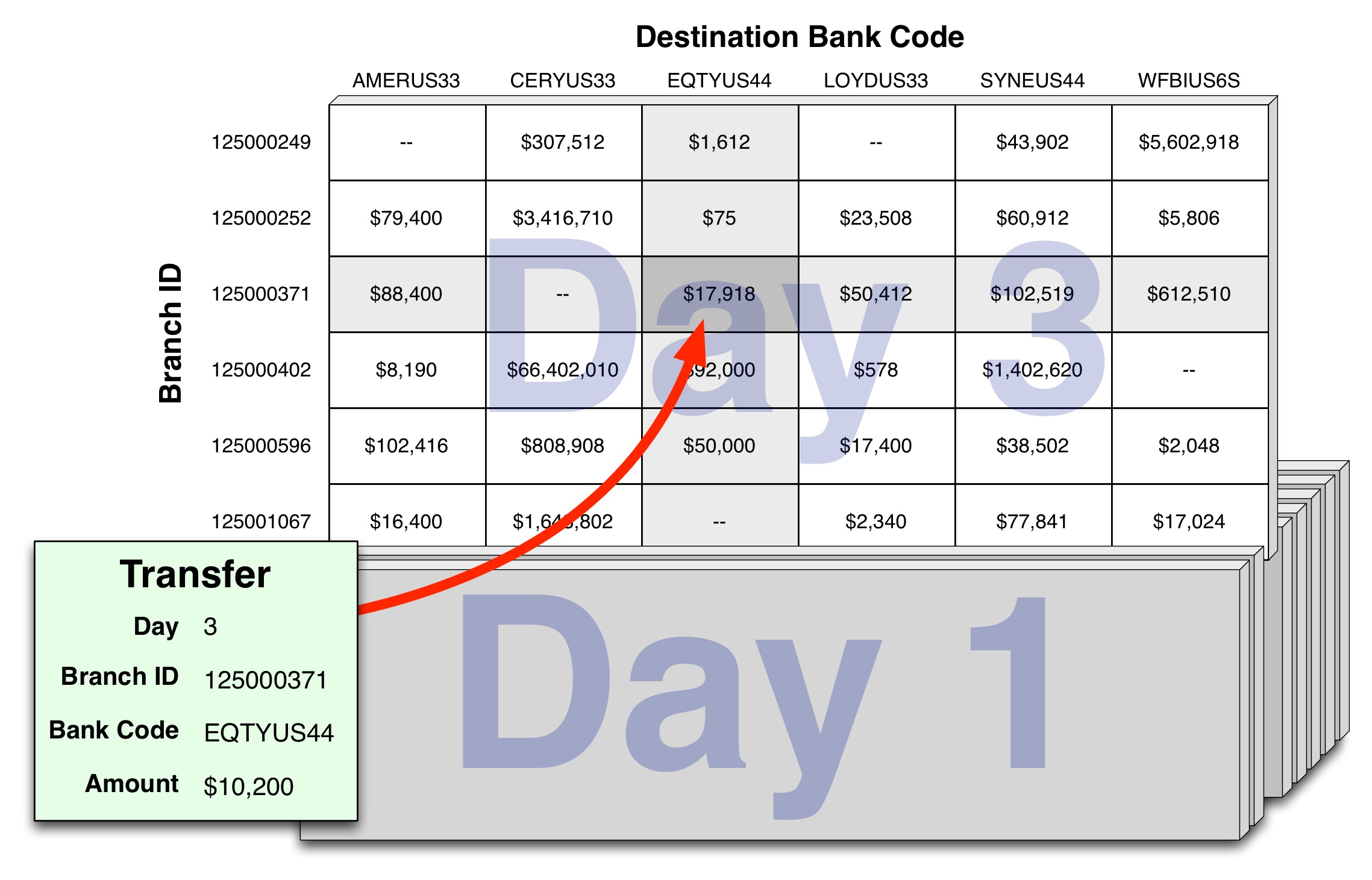
Our next task is to collate this information into a series of arrays. This allows us to calculate the total value of the transfers for each day, grouped by the branch ID and destination bank. To do this, we'll create a NumPy array for each day, where the rows in each array represent branches and the columns represent destination banks. We'll then go through the list of transfers, processing them one by one. The following illustration summarizes how we process each transfer in turn:
First, we select the array for the day on which the transfer occurred, and then we select the appropriate row and column based on the destination bank and the branch ID. Finally, we add the amount of the transfer to that item within the day's array.
Let's implement this logic. Our first task is to create a series of NumPy arrays, one for each day. Here, we immediately hit a snag: NumPy has many different options for creating arrays; in this case, we want to create an array that holds integer values and has its contents initialized to zero. If we used NumPy directly, our code would look like the following:
Unlock access to the largest independent learning library in Tech for FREE!
Get unlimited access to 7500+ expert-authored eBooks and video courses covering every tech area you can think of.
This is not exactly easy to understand, so we're going to move this logic into our NumPy wrapper module. Edit the numpy_wrapper.py file, and add the following to the end of this module:
Now, we can create a new array by calling our wrapper function (npw.new()) and not have to worry about the details of how NumPy works at all. We have simplified the interface to this particular aspect of NumPy:
Let's now use our wrapper function to create the eight arrays that we will need, one for each day. Add the following to the end of the detect_unusual_transfers.py file:
transfers_by_day = {}
for day in days:
transfers_by_day[day] = npw.new(num_rows=len(BANK_CODES),
num_cols=len(BRANCH_IDS))
Now that we have our NumPy arrays, we can use them as if they were nested Python lists. For example:
array[row][col] = array[row][col] + amount
We just need to choose the appropriate array, and calculate the row and column numbers to use. Here is the necessary code, which you should add to the end of your detect_unusual_transfers.py script:
for day,bank_code,branch_id,amount in transfers:
array = transfers_by_day[day]
row = BRANCH_IDS.index(branch_id)
col = BANK_CODES.index(bank_code)
array[row][col] = array[row][col] + amount
Now that we've collated the transfers into eight NumPy arrays, we want to use all this data to detect any unusual activity. For each combination of branch ID and destination bank code, we will need to do the following:
Calculate the average of the first seven days' activity.
Multiply the calculated average by 1.5.
If the activity on the eighth day is greater than the average multiplied by 1.5, then we consider this activity to be unusual.
Of course, we need to do this for every row and column in our arrays, which would be very slow; this is why we're using NumPy. So, we need to calculate the average for multiple arrays of numbers, then multiply the array of averages by 1.5, and finally, compare the values within the multiplied array against the array for the eighth day of data. Fortunately, these are all things that NumPy can do for us.
We'll start by collecting together the seven arrays we need to average, as well as the array for the eighth day. To do this, add the following to the end of your program:
latest_day = max(days)
transfers_to_average = []
for day in days:
if day != latest_day:
transfers_to_average.append(transfers_by_day[day])
current = transfers_by_day[latest_day]
To calculate the average of a list of arrays, NumPy requires us to use the following function call:
average = numpy.mean(numpy.array(arrays_to_average), axis=0)
Since this is confusing, we will move this function into our wrapper. Add the following code to the end of the numpy_wrapper.py module:
This lets us calculate the average of the seven day's activity using a single call to our wrapper function. To do this, add the following to the end of your detect_unusual_transfers.py script:
average = npw.average(transfers_to_average)
As you can see, using the wrapper makes our code much easier to understand.
Our next task is to multiply the array of calculated averages by 1.5, and compare the result against the current day's totals. Fortunately, NumPy makes this easy:
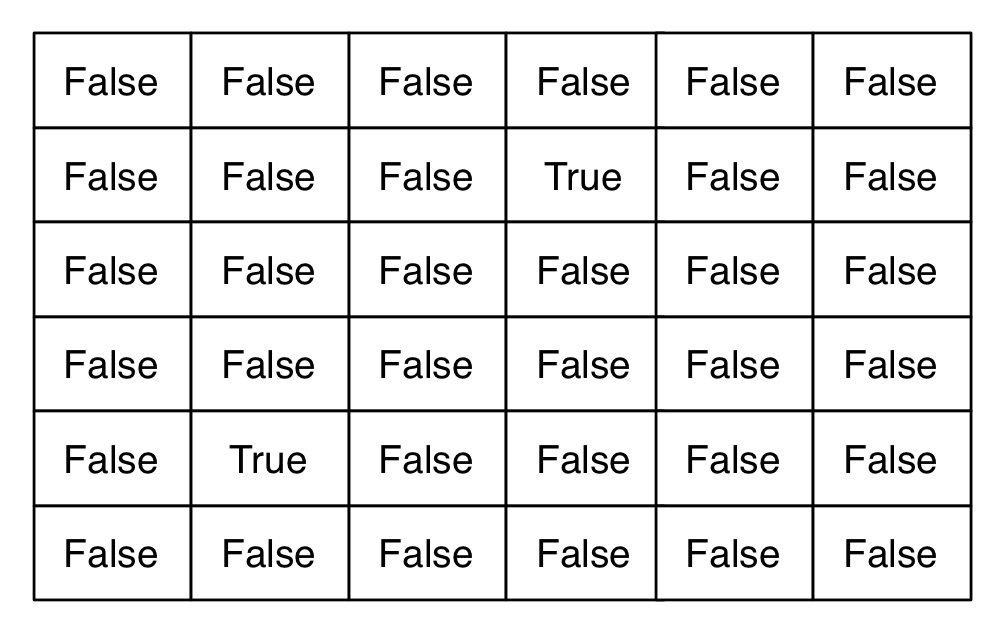
unusual_transfers = current > average * 1.5
Because this code is so clear, there's no advantage in creating a wrapper function for it. The resulting array, unusual_transfers, will be the same size as our current and average arrays, where each entry in the array is either True or False:
We're almost done; our final task is to identify the array entries with a value of True, and tell the user about the unusual activity. While we could scan through every row and column to find the True entries, using NumPy is much faster. The following NumPy code will give us a list containing the row and column numbers for the True entries in the array:
indices = numpy.transpose(array.nonzero())
True to form, though, this code is hard to understand, so it's a perfect candidate for another wrapper function. Go back to your numpy_wrapper.py module, and add the following to the end of the file:
This function returns a list (actually an array) of (row,col) values for all the True entries in the array. Back in our detect_unusual_activity.py file, we can use this function to quickly identify the unusual activity:
for row,col in npw.get_indices(unusual_transfers):
branch_id = BRANCH_IDS[row]
bank_code = BANK_CODES[col]
average_amt = int(average[row][col])
current_amt = current[row][col]
print("Branch {} transferred ${:,d}".format(branch_id,
current_amt) +
" to bank {}, average = ${:,d}".format(bank_code,
average_amt))
As you can see, we use the BRANCH_IDS and BANK_CODES lists to convert from the row and column number back to the relevant branch ID and bank code. We also retrieve the average and current amounts for the suspicious activity. Finally, we print out this information to warn the user about the unusual activity.
If you run your program, you should see an output that looks something like this:
Branch 125000371 transferred $24,729,847 to bank WFBIUS6S, average = $14,954,617
Branch 125000402 transferred $26,818,710 to bank CERYUS33, average = $16,338,043
Branch 125001067 transferred $27,081,511 to bank EQTYUS44, average = $17,763,644
Because we are using random numbers for our financial data, the output will be random too. Try running the program a few times; you may not get any output at all if none of the randomly-generated values are suspicious.
Of course, we are not really interested in detecting suspicious financial activity—this example is just an excuse for working with NumPy. What is far more interesting is the wrapper module that we created, hiding the complexity of the NumPy interface so that the rest of our program can concentrate on the job to be done.
If we were to continue developing our unusual activity detector, we would no doubt add more functionality to our numpy_wrapper.py module as we found more NumPy functions that we wanted to wrap.
Summary
This is just one example of a wrapper module. As we mentioned earlier, simplifying a complex and confusing API is just one use for a wrapper module; they can also be used to convert data from one format to another, add testing and error-checking code to an existing API, and call functions that are written in a different language.
Note that, by definition, a wrapper is always thin—while there might be code in a wrapper (for example, to convert a parameter from an object into a dictionary), the wrapper function always ends up calling another function to do the actual work.

 United States
United States
 Great Britain
Great Britain
 India
India
 Germany
Germany
 France
France
 Canada
Canada
 Russia
Russia
 Spain
Spain
 Brazil
Brazil
 Australia
Australia
 Singapore
Singapore
 Canary Islands
Canary Islands
 Hungary
Hungary
 Ukraine
Ukraine
 Luxembourg
Luxembourg
 Estonia
Estonia
 Lithuania
Lithuania
 South Korea
South Korea
 Turkey
Turkey
 Switzerland
Switzerland
 Colombia
Colombia
 Taiwan
Taiwan
 Chile
Chile
 Norway
Norway
 Ecuador
Ecuador
 Indonesia
Indonesia
 New Zealand
New Zealand
 Cyprus
Cyprus
 Denmark
Denmark
 Finland
Finland
 Poland
Poland
 Malta
Malta
 Czechia
Czechia
 Austria
Austria
 Sweden
Sweden
 Italy
Italy
 Egypt
Egypt
 Belgium
Belgium
 Portugal
Portugal
 Slovenia
Slovenia
 Ireland
Ireland
 Romania
Romania
 Greece
Greece
 Argentina
Argentina
 Netherlands
Netherlands
 Bulgaria
Bulgaria
 Latvia
Latvia
 South Africa
South Africa
 Malaysia
Malaysia
 Japan
Japan
 Slovakia
Slovakia
 Philippines
Philippines
 Mexico
Mexico
 Thailand
Thailand