









Last week, a team of researchers from Stanford University, Max Planck Institute for Informatics, Princeton University and Adobe Research published a paper titled “Text-based Editing of Talking-head Video”. This paper proposes a method to edit a talking-head video based on its transcript to produce a realistic output video, in which the dialogue of the speaker has been modified. Basically, the editor modifies a video using a text transcript, to add new words, delete unwanted ones or completely rearrange the pieces by dragging and dropping. This video will maintain a seamless audio-visual flow, without any jump cuts and will look almost flawless to the untrained eye.
The researchers want this kind of text-based editing approach to lay the foundation for better editing tools, in post production of movies and television. Actors often botch small bits of performance or leave out a critical word. This algorithm can help video editors fix that, which has until now involves expensive reshoots. It can also help in easy adaptation of audio-visual video content to specific target audiences. The tool supports three types of edit operations- add new words, rearrange existing words, delete existing words. Ohad Fried, a researcher in the paper says that “This technology is really about better storytelling. Instructional videos might be fine-tuned to different languages or cultural backgrounds, for instance, or children’s stories could be adapted to different ages.”
How does the application work?
The method uses an input talking-head video and a transcript to perform text-based editing.
- The first step is to align phonemes to the input audio and track each input frame to construct a parametric head model.
- Next, a 3D parametric face model with each frame of the input talking-head video is registered. This helps in selectively blending different aspects of the face.
- Then, a background sequence is selected and is used for pose data and background pixels. The background sequence allows editors to edit challenging videos with hair movement and slight camera motion. As Facial expressions are an important parameter, the researchers have tried to preserve the retrieved expression parameters as much as possible, by smoothing out the transition between them. This provides an output of edited parameter sequence which describes the new desired facial motion and a corresponding retimed background video clip.
- This is forwarded to a ‘neural face rendering’ approach. This step changes the facial motion of the retimed background video to match the parameter sequence. Thus the rendering procedure produces photo-realistic video frames of the subject, appearing to speak the new phrase.These localized edits seamlessly blends into the original video, producing an edited result.
- Lastly to add the audio, the resulted video is retimed to match the recording at the level of phones. The researchers have used the performers own voice in all their synthesis results.
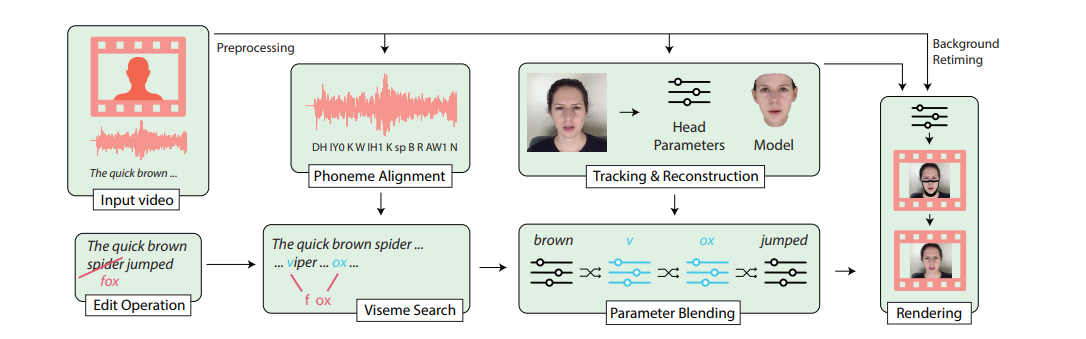
Image Source: Text-based Editing of Talking-head Video
The researchers have tested the system with a series of complex edits including adding, removing and changing words, as well as translations to different languages. When the application was tried in a crowd-sourced study with 138 participants, the edits were rated as “real”, almost 60% of the time. Fried said that “The visual quality is such that it is very close to the original, but there’s plenty of room for improvement.”
Ethical considerations: Erosion of truth, confusion and defamation
Even though the application is quite useful for video editors and producers, it raises important and valid concerns about its potential for misuse. The researchers have also agreed that such a technology might be used for illicit purposes. “We acknowledge that bad actors might use such technologies to falsify personal statements and slander prominent individuals. We are concerned about such deception and misuse.”
They have recommended certain precautions to be taken to avoid deception and misuse such as using watermarking. “The fact that the video is synthesized may be obvious by context, directly stated in the video or signaled via watermarking. We also believe that it is essential to obtain permission from the performers for any alteration before sharing a resulting video with a broad audience.”
They urge the community to continue to develop forensics, fingerprinting and verification techniques to identify manipulated video. They also support the creation of appropriate regulations and laws that would balance the risks of misuse of these tools against the importance of creative, consensual use cases.
The public however remain dubious pointing out valid arguments on why the ‘Ethical Concerns’ talked about in the paper, fail.
A user on Hacker News comments, “The “Ethical concerns” section in the article feels like a punt. The author quoting “this technology is really about better storytelling” is aspirational — the technology’s story will be written by those who use it, and you can bet people will use this maliciously.”
OMG, we're doomed. It's getting easier than ever to doctor video footage -> New algorithm developed by Stanford, Princeton, & Adobe allows researchers to change what people say on video by simply editing the transcript https://t.co/4lFdHFZppa pic.twitter.com/Mf6GUnm884
— Glenn Gabe (@glenngabe) June 6, 2019
Another user feels that such kind of technology will only result in “slow erosion of video evidence being trustworthy”.
Others have pointed out how the kind of transformation mentioned in the paper, does not come under the broad category of ‘video-editing’
‘We need more words to describe this new landscape’
Jaime, indeed! I fully agree. The implications are really very wide ranging. We have shifted into a new world where “seeing is believing” no longer applies.
— Brian Roemmele (@BrianRoemmele) June 6, 2019
Another common argument is that the algorithm can be used to generate terrifyingly real Deepfake videos. A Shallow Fake video was Nancy Pelosi’s altered video, which circulated recently, that made it appear she was slurring her words by slowing down the video. Facebook was criticized for not acting faster to slow the video’s spread. Not just altering speeches of politicians, altered videos like these can also, for instance, be used to create fake emergency alerts, or disrupt elections by dropping a fake video of one of the candidates before voting starts. There is also the issue of defaming someone on a personal capacity.
Sam Gregory, Program Director at Witness, tweets that one of the main steps in ensuring effective use of such tools would be to “ensure that any commercialization of synthetic media tools has equal $ invested in detection/safeguards as in detection.; and to have a grounded conversation on trade-offs in mitigation”. He has also listed more interesting recommendations.
4. Another would be to have a commitment made by as many politicians as possible not to use these in campaigning – an example already has been pushed here: https://t.co/q6yVTB3yEo. Norms do matter still for harm reduction even if not as effective as b4. pic.twitter.com/NsXhO2HAYE
— Sam Gregory (@SamGregory) June 7, 2019
For more details, we recommend you to read the research paper.