
Domain driven design exists because all software exists for a purpose. It does something. For example, you can’t provide a software solution for a financial system such as online stock trading if you don’t understand the stock exchanges and their functioning. Having domain knowledge is essential to solving problems with software. Domain driven design is simply designing software with the specific domain – whether that’s finance, medicine, law, eCommerce – in mind.
This has been taken from Mastering Microservices with Java 9 – Second Edition.

Central to Domain Driven Design is the concept of a model. A model is an abstraction, or a blueprint, of the domain.
Domain driven design is a collaborative activity
Designing this model is not rocket science, but it does take a lot of effort, refining, and input from domain experts. It is the collective job of software designers, domain experts, and developers. They organize information, divide it into smaller parts, group them logically, and create modules. Each module can be taken up individually, and can be divided using a similar approach. This process can be followed until we reach the unit level, or when we cannot divide it any further. A complex project may have more of such iterations; similarly, a simple project could have just a single iteration of it.
Once a model is defined and well documented, it can move onto the next stage – code design. So, here we have a software design—a domain model and code design, and code implementation of the domain model. The domain model provides a high level of the architecture of a solution (software/application), and the code implementation gives the domain model a life, as a working model.
Domain Driven Design makes design and development work together. It provides the ability to develop software continuously, while keeping the design up to date based on feedback received from the development. It solves one of the limitations offered by Agile and Waterfall methodologies, making software maintainable, including design and code, as well as keeping application minimum viable. It gives developers the right platform to understand the domain, and provides the opportunity to share early feedback of the domain model implementation. It removes the bottleneck that appears in later stages when stockholders wait for deliverables.
The fundamental components of Domain Driven Design
To understand domain driven design, you can break it down into 3 fundamental concepts:
- Ubiquitous language and unified model language (UML)
- Multilayer architecture
- Artifacts (components)
Ubiquitous language
Ubiquitous language is a common language to communicate within a project. It’s because designing a model is a collaborative effort of software designers, domain experts, and developers that it requires a common language to communicate with. It removes misunderstandings, misinterpretations. Communication gaps so often lead to bad software – ubiquitous language minimizes these gaps. It does, however, need to be used everywhere on a project.
Unified Modeling Language (UML) is widely used and very popular when creating models. It also has a few limitations; for example, when you have thousands of classes drawn from a paper, it’s difficult to represent class relationships and simultaneously understand their abstraction while taking a meaning from it. Also, UML diagrams do not represent the concepts of a model and what objects are supposed to do. Therefore, UML should always be used with other documents, code, or any other reference for effective communication.
Multilayered architecture
Multilayered architecture is a common solution for Domain Driven Design. It contains four layers:
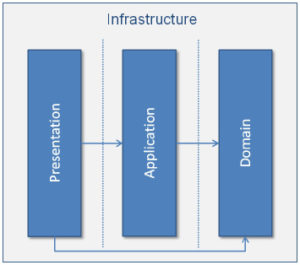
- Presentation layer or (UI)
- Application layer – responsible for application logic. It maintains and coordinates the overall flow of the product/service. It does not contain business logic or UI. It may hold the state of application objects, like tasks in progress.
- Domain layer – contains the domain information and business logic. It holds the state of the business object.
- Infrastructure layer – provides support to all the other layers and is responsible for communication between them.
To understand the interaction of the different layers, take the example of table booking at a restaurant. The end user places a request for a table booking using UI. The UI passes the request to the application layer. The application layer fetches the domain objects, such as the restaurant, the table, a date, and so on, from the domain layer. The domain layer fetches these existing persisted objects from the infrastructure, and invokes relevant methods to make the booking and persist them back to the infrastructure layer. Once domain objects are persisted, the application layer shows the booking confirmation to the end user.
Artifacts used in Domain Driven Design
There are seven different artifacts used in Domain Driven Design to express, create, and retrieve domain models:
- Entities
- Value objects
- Services
- Aggregates
- Repository
- Factory
- Module
Entities are certain types of objects that are identifiable and remain the same throughout the states of the products/services. These objects are not identified by their attributes, but by their identity and thread of continuity. These type of objects are known as entities.
It sounds pretty simple, but it carries complexity. You need to understand how we can define the entities. Let’s take an example of a table booking system, where we have a restaurant class with attributes such as restaurant name, address, phone number, establishment data, and so on. We can take two instances of the restaurant class that are not identifiable using the restaurant name, as there could be other restaurants with the same name. Similarly, if we go by any other single attribute, we will not find any attributes that can singularly identify a unique restaurant. If two restaurants have all the same attribute values, they are therefore the same and are interchangeable with each other. Still, they are not the same entities, as both have different references (memory addresses).
Conversely, let’s take a class of U.S. citizens. Every U.S. citizen has his or her own social security number. This number is not only unique, but remains unchanged throughout the life of the citizen and assures continuity. This citizen object would exist in the memory, would be serialized, and would be removed from the memory and stored in the database. It even exists after the person is deceased. It will be kept in the system for as long as the system exists. A citizen’s social security number remains the same irrespective of its representation.
Therefore, creating entities in a product means creating an identity. So, now give an identity to any restaurant in the previous example, then either use a combination of attributes such as restaurant name, establishment date, and street, or add an identifier such as restaurant_id to identify it. The basic rule is that two identifiers cannot be the same. Therefore, when we introduce an identifier for an entity, we need to be sure of it.
There are different ways to create a unique identity for objects, described as follows:
- Using the primary key in a table.
- Using an automated generated ID by a domain module. A domain program generates the identifier and assigns it to objects that are being persisted among different layers.
- A few real-life objects carry user-defined identifiers themselves. For example, each country has its own country codes for dialing ISD calls.
- Composite key. This is a combination of attributes that can also be used for creating an identifier, as explained for the preceding restaurant object.
Value objects
Value objects (VOs) simplify the design. In contrast to entities, value objects have only attributes and no conceptual identity. A best practice is to keep value objects as immutable objects. If possible, you should even keep entity objects immutable too.
You might want to keep all objects as entities, but you’re likely to run into problems if you do this; there has to be one instance for each object. Let’s say you are creating customers as entity objects. Each customer object would represent the restaurant guest; this cannot be used for booking orders for other guests. This may create millions of customer entity objects in the memory if millions of customers are using the system. Not only are there millions of uniquely identifiable objects that exist in the system, but each object is being tracked. Tracking as well as creating an identity is complex. A highly credible system is required to create and track these objects, which is not only very complex, but also resource heavy. It may result in system performance degradation. Therefore, it is important to use value objects instead of using entities. The reasons are explained in the next few paragraphs.
Applications don’t always need to have to be trackable and have an identifiable customer object. There are cases when you just need to have some or all attributes of the domain element. These are the cases when value objects can be used by the application. It makes things simple and improves the performance.
Value objects can easily be created and destroyed, owing to the absence of identity. This simplifies the design—it makes value objects available for garbage collection if no other object has referenced them.
Value objects should be designed and coded as immutable. Once they are created, they should never be modified during their life-cycle. If you need a different value of the VO, or any of its objects, then simply create a new value object, but don’t modify the original value object. Here, immutability carries all the significance from object-oriented programming (OOP). A value object can be shared and used without impacting on its integrity if, and only if, it is immutable.
Services
While creating the domain model, you may come across situations where behavior may not be related to any object. These behaviors can be accommodated in service objects.
Service objects are part of the domain layer and do not have any internal state. The sole purpose of service objects is to provide behavior to the domain that does not belong to a single entity or value object.
Ubiquitous language helps you to identify different objects, identities, or value objects with different attributes and behaviors during the process of domain driven design and domain modelling. During the course of creating the domain model, you may find different behaviors or methods that do not belong to any specific object. Such behaviors are important, and so cannot be neglected. Neither can you add them to entities or value objects. It would spoil the object to add behavior that does not belong to it. Keep in mind, that behavior may impact on various objects. The use of object-oriented programming makes it possible to attach to some objects; this is known as a service.
Services are common in technical frameworks. These are also used in domain layers in domain driven design. A service object does not have any internal state; its only purpose is to provide a behavior to the domain. Service objects provide behaviors that cannot be related to specific entities or value objects. Service objects may provide one or more related behaviors to one or more entities or value objects. It is a practice to define the services explicitly in the domain model.
While creating the services, you need to tick all of the following points:
- Service objects’ behavior performs on entities and value objects, but it does not belong to entities or value objects
- Service objects’ behavior state is not maintained, and hence, they are stateless
Services are part of the domain model - Services may also exist in other layers. It is very important to keep domain-layer services isolated. It removes the complexities and keeps the design decoupled.
Let’s take an example where a restaurant owner wants to see the report of his monthly table bookings. In this case, he will log in as an admin and click the Display Report button after providing the required input fields, such as duration.
Application layers pass the request to the domain layer that owns the report and templates objects, with some parameters such as report ID, and so on. Reports get created using the template, and data is fetched from either the database or other sources. Then the application layer passes through all the parameters, including the report ID to the business layer. Here, a template needs to be fetched from the database or another source to generate the report based on the ID. This operation does not belong to either the report object or the template object. Therefore, a service object is used that performs this operation to retrieve the required template from the database.
Aggregates
Aggregate domain pattern is related to the object’s life cycle. It defines ownership and boundaries which is crucial in Domain Driven Design
When you reserve a table at your favorite restaurant online using an application, you don’t need to worry about the internal system and process that takes place to book your reservation, including searching for available restaurants, then for available tables on the given date, time, and so on and so forth. Therefore, you can say that a reservation application is an aggregate of several other objects, and works as a root for all the other objects for a table reservation system.
This root should be an entity that binds collections of objects together. It is also called the aggregate root. This root object does not pass any reference of inside objects to external worlds, and protects the changes performed within internal objects.
We need to understand why aggregators are required. A domain model can contain large numbers of domain objects. The bigger the application functionalities and size and the more complex its design, the greater number of objects present. A relationship exists between these objects. Some may have a many-to-many relationship, a few may have a one-to-many relationship, and others may have a one-to-one relationship. These relationships are enforced by the model implementation in the code, or in the database that ensures that these relationships among the objects are kept intact. Relationships are not just unidirectional; they can also be bidirectional. They can also increase in complexity.
The designer’s job is to simplify these relationships in the model. Some relationships may exist in a real domain, but may not be required in the domain model. Designers need to ensure that such relationships do not exist in the domain model. Similarly, multiplicity can be reduced by these constraints. One constraint may do the job where many objects satisfy the relationship. It is also possible that a bidirectional relationship could be converted into a unidirectional relationship.
No matter how much simplification you input, you may still end up with relationships in the model. These relationships need to be maintained in the code. When one object is removed, the code should remove all the references to this object from other places. For example, a record removal from one table needs to be addressed wherever it has references in the form of foreign keys and such, to keep the data consistent and maintain its integrity. Also, invariants (rules) need to be forced and maintained whenever data changes.
Relationships, constraints, and invariants bring a complexity that requires an efficient handling in code. We find the solution by using the aggregate represented by the single entity known as the root, which is associated with the group of objects that maintains consistency with regards to data changes.
This root is the only object that is accessible from outside, so this root element works as a boundary gate that separates the internal objects from the external world. Roots can refer to one or more inside objects, and these inside objects can have references to other inside objects that may or may not have relationships with the root. However, outside objects can also refer to the root, and not to any inside objects.
An aggregate ensures data integrity and enforces the invariant. Outside objects cannot make any change to inside objects; they can only change the root. However, they can use the root to make a change inside the object by calling exposed operations. The root should pass the value of inside objects to outside objects if required.
If an aggregate object is stored in the database, then the query should only return the aggregate object. Traversal associations should be used to return the object when it is internally linked to the aggregate root. These internal objects may also have references to other aggregates.
An aggregate root entity holds its global identity, and holds local identities inside their entities.
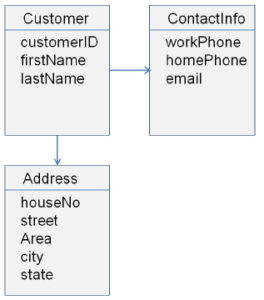
A simple example of an aggregate in the table booking system is the customer. Customers can be exposed to external objects, and their root object contains their internal object address and contact information.
When requested, the value object of internal objects, such as address, can be passed to external objects:
Repository
In a domain model, at a given point in time, many domain objects may exist. Each object may have its own life-cycle, from the creation of objects to their removal or persistence. Whenever any domain operation needs a domain object, it should retrieve the reference of the requested object efficiently. It would be very difficult if you didn’t maintain all of the available domain objects in a central object. A central object carries the references of all the objects, and is responsible for returning the requested object reference. This central object is known as the repository.
The repository is a point that interacts with infrastructures such as the database or file system. A repository object is the part of the domain model that interacts with storage such as the database, external sources, and so on, to retrieve the persisted objects. When a request is received by the repository for an object’s reference, it returns the existing object’s reference. If the requested object does not exist in the repository, then it retrieves the object from storage. For example, if you need a customer, you would query the repository object to provide the customer with ID 31. The repository would provide the requested customer object if it is already available in the repository, and if not, it would query the persisted stores such as the database, fetch it, and provide its reference.
The main advantage of using the repository is having a consistent way to retrieve objects where the requestor does not need to interact directly with the storage such as the database.

A repository may query objects from various storage types, such as one or more databases, filesystems, or factory repositories, and so on. In such cases, a repository may have strategies that also point to different sources for different object types
As you can see in the repository object flow diagram on the right, the repository interacts with the infrastructure layer, and this interface is part of the domain layer. The requestor may belong to a domain layer, or an application layer. The repository helps the system to manage the life cycle of domain objects.
Factory
A factory is required when a simple constructor is not enough to create the object. It helps to create complex objects, or an aggregate that involves the creation of other related objects.
A factory is also a part of the life cycle of domain objects, as it is responsible for creating them. Factories and repositories are in some way related to each other, as both refer to domain objects. The factory refers to newly created objects, whereas the repository returns the already existing objects either from the memory, or from external storage.
Let’s see how control flows, by using a user creation process application. Let’s say that a user signs up with a username user1. This user creation first interacts with the factory, which creates the name user1 and then caches it in the domain using the repository, which also stores it in the storage for persistence.
When the same user logs in again, the call moves to the repository for a reference. This uses the storage to load the reference and pass it to the requestor.
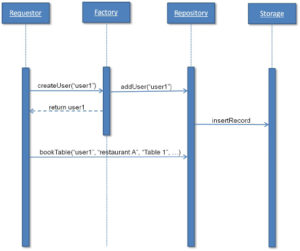
The requestor may then use this user1 object to book the table in a specified restaurant, and at a specified time. These values are passed as parameters, and a table booking record is created in storage using the repository:
The factory may use one of the object-oriented programming patterns, such as the factory or abstract factory pattern, for object creation.
Modules
Modules are the best way to separate related business objects. These are best suited to large projects where the size of domain objects is bigger. For the end user, it makes sense to divide the domain model into modules and set the relationship between these modules. Once you understand the modules and their relationship, you start to see the bigger picture of the domain model, thus it’s easier to drill down further and understand the model.
Modules also help you to write code that is highly cohesive, or maintains low coupling. Ubiquitous language can be used to name these modules. For the table booking system, we could have different modules, such as user-management, restaurants and tables, analytics and reports, and reviews, and so on.
This introduction to domain driven design should give you a strong foundation for using it when you build software. It’s principles are useful – in particular, making sure you collaborate and use the same language as different stakeholders is one of domain driven design’s most valuable contributions to the way we approach software development.