









Social engineering is one of the most dangerous threats facing every individual and modern organization. Phishing is a well-known, computer-based, social engineering technique. Attackers use disguised email addresses as a weapon to target large companies. With the huge number of phishing emails received every day, companies are not able to detect all of them. That is why new techniques and safeguards are needed to defend against phishing. This article will present the steps required to build three different machine learning-based projects to detect phishing attempts, using cutting-edge Python machine learning libraries.
We will use the following Python libraries:
- scikit-learn Python (≥ 2.7 or ≥ 3.3)
- NumPy (≥ 1.8.2)
- NLTK
Make sure that they are installed before moving forward. You can find the code files here.
Social engineering overview
Social engineering, by definition, is the psychological manipulation of a person to get useful and sensitive information from them, which can later be used to compromise a system. In other words, criminals use social engineering to gain confidential information from people, by taking advantage of human behavior.
Social Engineering Engagement Framework
The Social Engineering Engagement Framework (SEEF) is a framework developed by Dominique C. Brack and Alexander Bahmram. It summarizes years of experience in information security and defending against social engineering. The stakeholders of the framework are organizations, governments, and individuals (personals). Social engineering engagement management goes through three steps:
- Pre-engagement process: Preparing the social engineering operation
- During-engagement process: The engagement occurs
- Post-engagement process: Delivering a report
There are many social engineering techniques used by criminals:
- Baiting: Convincing the victim to reveal information, promising him a reward or a gift.
- Impersonation: Pretending to be someone else.
- Dumpster diving: Collecting valuable information (papers with addresses, emails, and so on) from dumpsters.
- Shoulder surfing: Spying on other peoples’ machines from behind them, while they are typing.
- Phishing: This is the most often used technique; it occurs when an attacker, masquerading as a trusted entity, dupes a victim into opening an email, instant message, or text message.
Steps of social engineering penetration testing
Penetration testing simulates a black hat hacker attack in order to evaluate the security posture of a company for deploying the required safeguard. Penetration testing is a methodological process, and it goes through well-defined steps. There are many types of penetration testing:
- White box pentesting
- Black box pentesting
- Grey box pentesting
To perform a social engineering penetration test, you need to follow the following steps:

Building real-time phishing attack detectors using different machine learning models
In the next sections, we are going to learn how to build machine learning phishing detectors. We will cover the following two methods:
- Phishing detection with logistic regression
- Phishing detection with decision trees
Phishing detection with logistic regression
In this section, we are going to build a phishing detector from scratch with a logistic regression algorithm. Logistic regression is a well-known statistical technique used to make binomial predictions (two classes).
Like in every machine learning project, we will need data to feed our machine learning model. For our model, we are going to use the UCI Machine Learning Repository (Phishing Websites Data Set). You can check it out at https://archive.ics.uci.edu/ml/datasets/Phishing+Websites:

The dataset is provided as an arff file:
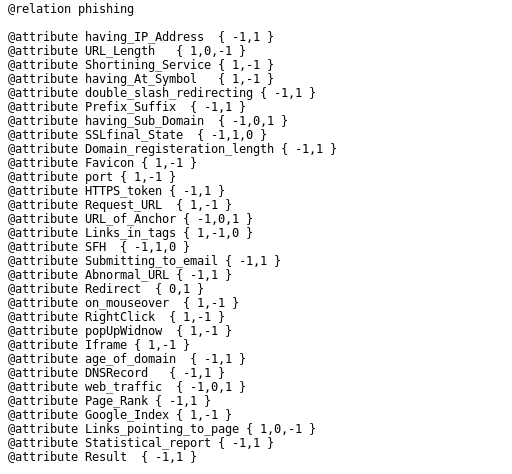
The following is a snapshot from the dataset:

For better manipulation, we have organized the dataset into a csv file:
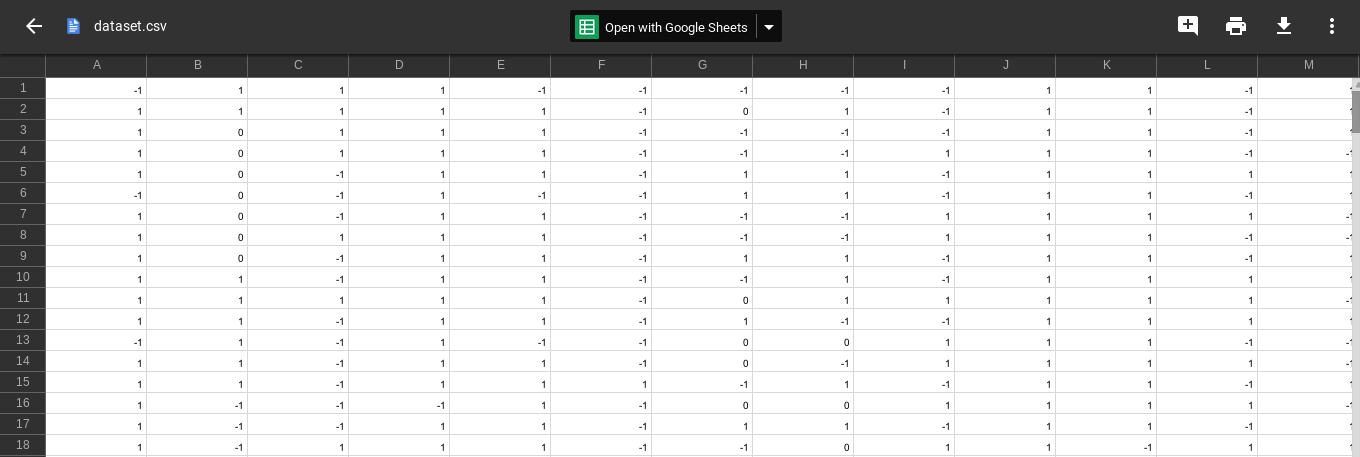
As you probably noticed from the attributes, each line of the dataset is represented in the following format – {30 Attributes (having_IP_Address URL_Length, abnormal_URL and so on)} + {1 Attribute (Result)}:
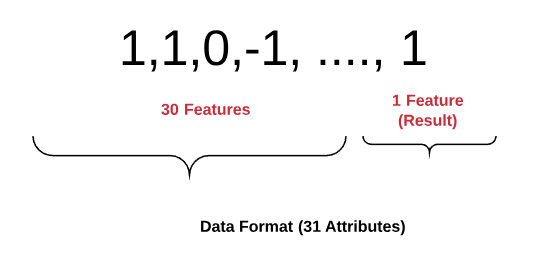
For our model, we are going to import two machine learning libraries, NumPy and scikit-learn.
Let’s open the Python environment and load the required libraries:
>>> import numpy as np >>> from sklearn import * >>> from sklearn.linear_model import LogisticRegression >>> from sklearn.metrics import accuracy_score
Next, load the data:
training_data = np.genfromtxt('dataset.csv', delimiter=',', dtype=np.int32)
Identify the inputs (all of the attributes, except for the last one) and the outputs (the last attribute):
>>> inputs = training_data[:,:-1] >>> outputs = training_data[:, -1]
We need to divide the dataset into training data and testing data:
training_inputs = inputs[:2000] training_outputs = outputs[:2000] testing_inputs = inputs[2000:] testing_outputs = outputs[2000:]

Create the scikit-learn logistic regression classifier:
classifier = LogisticRegression()
Train the classifier:
classifier.fit(training_inputs, training_outputs)
Make predictions:
predictions = classifier.predict(testing_inputs)
Let’s print out the accuracy of our phishing detector model:
accuracy = 100.0 * accuracy_score(testing_outputs, predictions) print ("The accuracy of your Logistic Regression on testing data is: " + str(accuracy))

The accuracy of our model is approximately 85%. This is a good accuracy, since our model detected 85 phishing URLs out of 100. But let’s try to make an even better model with decision trees, using the same data.
Phishing detection with decision trees
To build the second model, we are going to use the same machine learning libraries, so there is no need to import them again. However, we are going to import the decision tree classifier from sklearn:
>>> from sklearn import tree
Create the tree.DecisionTreeClassifier() scikit-learn classifier:
classifier = tree.DecisionTreeClassifier()
Train the model:
classifier.fit(training_inputs, training_outputs)
Compute the predictions:
predictions = classifier.predict(testing_inputs)
Calculate the accuracy:
accuracy = 100.0 * accuracy_score(testing_outputs, predictions)
Then, print out the results:
print ("The accuracy of your decision tree on testing data is: " + str(accuracy))

The accuracy of the second model is approximately 90.4%, which is a great result, compared to the first model. We have now learned how to build two phishing detectors, using two machine learning techniques.
NLP in-depth overview
NLP is the art of analyzing and understanding human languages by machines. According to many studies, more than 75% of the used data is unstructured. Unstructured data does not have a predefined data model or not organized in a predefined manner. Emails, tweets, daily messages and even our recorded speeches are forms of unstructured data. NLP is a way for machines to analyze, understand, and derive meaning from natural language. NLP is widely used in many fields and applications, such as:
- Real-time translation
- Automatic summarization
- Sentiment analysis
- Speech recognition
- Build chatbots
Generally, there are two different components of NLP:
- Natural Language Understanding (NLU): This refers to mapping input into a useful representation.
- Natural Language Generation (NLG): This refers to transforming internal representations into useful representations. In other words, it is transforming data into written or spoken narrative. Written analysis for business intelligence dashboards is one of NLG applications.
Every NLP project goes through five steps. To build an NLP project the first step is identifying and analyzing the structure of words. This step involves dividing the data into paragraphs, sentences, and words. Later we analyze the words in the sentences and relationships among them. The third step involves checking the text for meaningfulness. Then, analyzing the meaning of consecutive sentences. Finally, we finish the project by the pragmatic analysis.

Open source NLP libraries
There are many open source Python libraries that provide the structures required to build real-world NLP applications, such as:
- Apache OpenNLP
- GATE NLP library
- Stanford NLP
- And, of course, Natural Language Toolkit (NLTK)
Let’s fire up our Linux machine and try some hands-on techniques.
Open the Python terminal and import nltk:
>>> import nltk
Download a book type, as follows:
>>> nltk.download()

You can also type:
>> from nltk.book import *
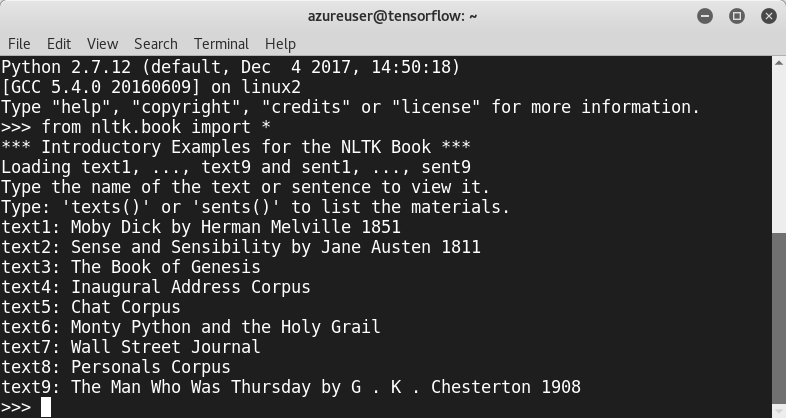
To get text from a link, it is recommended to use the urllib module to crawl a website:
>>> from urllib import urlopen >>> url = "http://www.URL_HERE/file.txt"
As a demonstration, we are going to load a text called Security.in.Wireless.Ad.Hoc.and.Sensor.Networks:
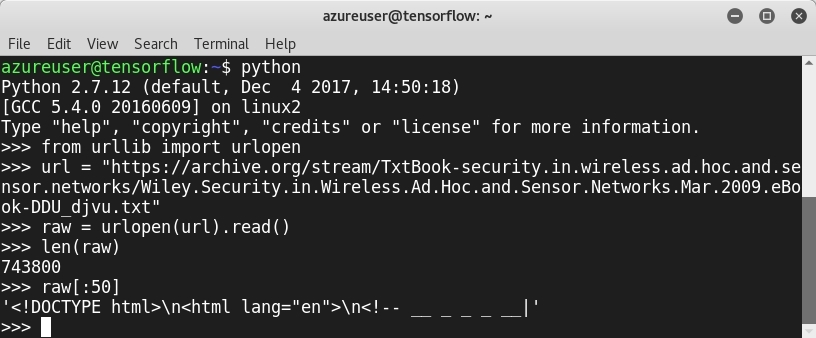
We crawled the text file, and used len to check its length and raw[:50] to display some content. As you can see from the screenshot, the text contains a lot of symbols that are useless for our projects. To get only what we need, we use tokenization:
>>> tokens = nltk.word_tokenize(raw) >>> len(tokens) > tokens[:10]
To summarize what we learned in the previous section, we saw how to download a web page, tokenize the text, and normalize the words.
Spam detection with NLTK
Now it is time to build our spam detector using the NLTK. The principle of this type of classifier is simple; we need to detect the words used by spammers. We are going to build a spam/non-spam binary classifier using Python and the nltk library, to detect whether or not an email is spam. First, we need to import the library as usual:
>>> import nltk
We need to load data and feed our model with an emails dataset. To achieve that, we can use the dataset delivered by the Internet CONtent FIltering Group. You can visit the website at https://labs-repos.iit.demokritos.gr/skel/i-config/:

Basically, the website provides four datasets:
- Ling-spam
- PU1
- PU123A
- Enron-spam
For our project, we are going to use the Enron-spam dataset:

Let’s download the dataset using the wget command:
Extract the tar.gz file by using the tar -xzf enron1.tar.gz command:
Shuffle the cp spam/* emails && cp ham/* emails object:
To shuffle the emails, let’s write a small Python script, Shuffle.py, to do the job:
import os
import random
#initiate a list called emails_list
emails_list = []
Directory = '/home/azureuser/spam_filter/enron1/emails/'
Dir_list = os.listdir(Directory)
for file in Dir_list:
f = open(Directory + file, 'r')
emails_list.append(f.read())
f.close()
Just change the directory variable, and it will shuffle the files:

After preparing the dataset, you should be aware that, as we learned previously, we need to tokenize the emails:
>> from nltk import word_tokenize

Also, we need to perform another step, called lemmatizing. Lemmatizing connects words that have different forms, like hacker/hackers and is/are. We need to import WordNetLemmatizer:
>>> from nltk import WordNetLemmatizer
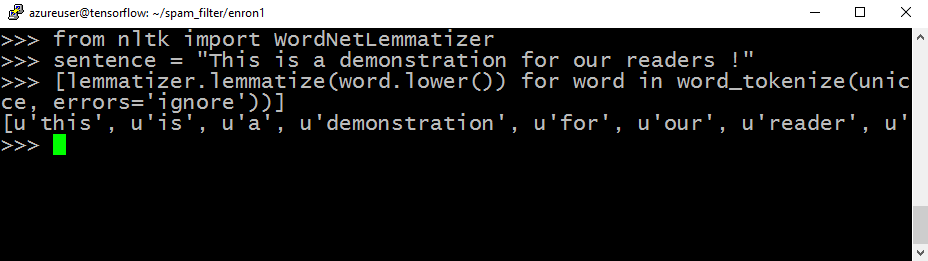
Create a sentence for the demonstration, and print out the result of the lemmatizer:
>>> [lemmatizer.lemmatize(word.lower()) for word in word_tokenize(unicode(sentence, errors='ignore'))]
Then, we need to remove stopwords, such as of, is, the, and so on:
from nltk.corpus import stopwords
stop = stopwords.words('english')
To process the email, a function called Process must be created, to lemmatize and tokenize our dataset:
def Process(data): lemmatizer = WordNetLemmatizer() return [lemmatizer.lemmatize(word.lower()) for word in word_tokenize(unicode(sentence, errors='ignore'))]
The second step is feature extraction, by reading the emails’ words:
from collections import Counter
def Features_Extraction(text, setting):
if setting=='bow':
# Bow means bag-of-words
return {word: count for word, count in Counter(Process(text)).items() if not word in stop}
else:
return {word: True for word in Process(text) if not word in stop}
Extract the features:
features = [(Features_Extraction(email, 'bow'), label) for (email, label) in emails]
Now, let’s define training the model Python function:
def training_Model (Features, samples):
Size = int(len(Features) * samples)
training , testing = Features[:Size], Features[Size:]
print ('Training = ' + str(len(training)) + ' emails')
print ('Testing = ' + str(len(testing)) + ' emails')
As a classification algorithm, we are going to use NaiveBayesClassifier:
from nltk import NaiveBayesClassifier, classify classifier = NaiveBayesClassifier.train(training)
Finally, we define the evaluation Python function:
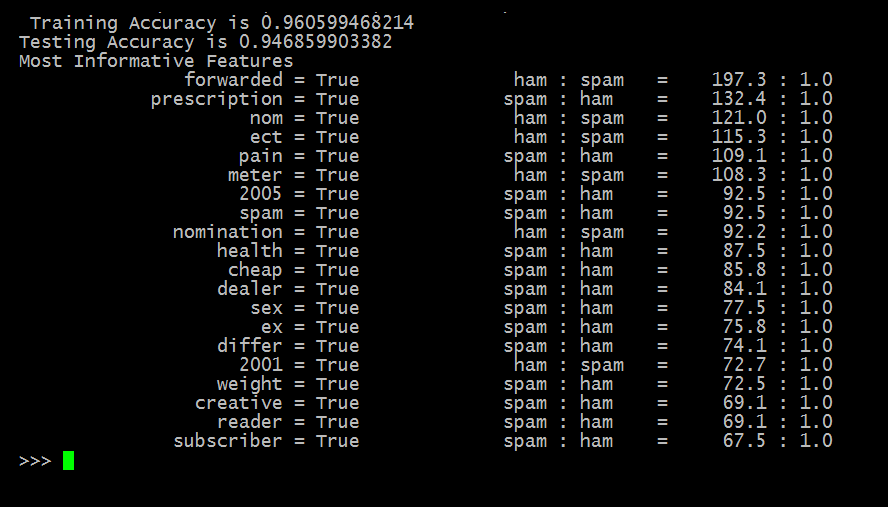
def evaluate(training, tesing, classifier):
print ('Training Accuracy is ' + str(classify.accuracy(classifier, train_set)))
print ('Testing Accuracy i ' + str(classify.accuracy(classifier, test_set)))
In this article, we learned to detect phishing attempts by building three different projects from scratch. First, we discovered how to develop a phishing detector using two different machine learning techniques—logistic regression and decision trees. The third project was a spam filter, based on NLP and Naive Bayes classification.
To become a master at penetration testing using machine learning with Python, check out this book Mastering Machine Learning for Penetration Testing.









