









Last month, at USENIX ATC 2019, many systems researchers presented their work on topics including real-world deployed systems, runtimes, big-data programming models, security, virtualization, and much more. This year it happened from 10-12 July at Renton, WA, USA.
The USENIX Annual Technical Conference (ATC) is considered to be one of the most prestigious systems research conferences. It covers all practical facets of systems software and aims to improve and further the knowledge of computing systems of all scales. Along with providing a platform to showcase cutting-edge systems research, it also allows researchers to gain insight into fields like virtualization, system management and troubleshooting, cloud and edge computing, security, and more.
Here are some of the remarkable papers presented at this event:
Captive – a retargetable system-level DBT hypervisor
By: Tom Spink, Harry Wagstaff, and Björn Franke from the University of Edinburgh
Why Captive is needed
To boot an operating system and execute programs compiled for an Instruction Set Architecture (ISA) other than the host machine, system-level Dynamic Binary Translation (DBT) is used. DBT is a process of translating code for one ISA to another on the fly. Due to their performance-critical nature, DBT frameworks are generally hardcoded and heavily optimized for both their guest and host ISAs. Though this ensures performance gains, it poses high engineering costs for supporting a new architecture or extending an existing one.
How Captive works
The researchers have devised a novel, retargetable system-level DBT hypervisor called Captive. It includes guest specific modules generated from high-level guest machine specifications, which simplifies retargeting of the DBT and relieves users from low-level implementation effort.
Captive enforces aggressive optimizations by combining the offline optimizations of the architecture model with online optimizations performed within the generated Just-In-Time compiler. It reduces the compilation overheads while providing high code quality. Additionally, it operates in a virtual bare-metal environment provided by a VM hypervisor. This allows you to fully exploit the underlying host architecture, especially the system-related and privileged features not accessible to other DBT systems operating as user processes.
Here’s a diagram depicting how it works:
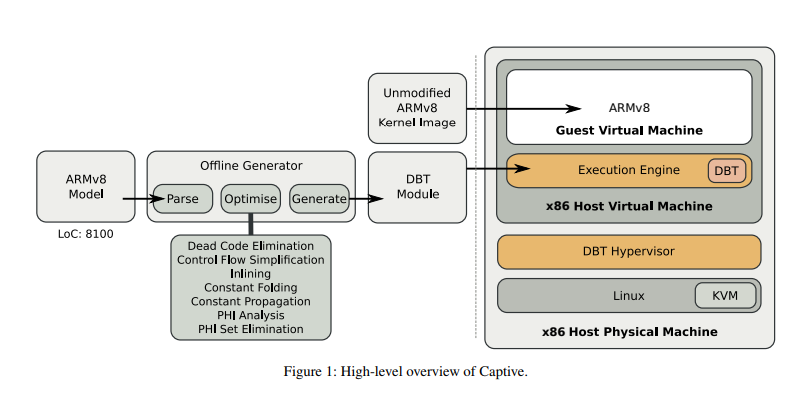
Source: Usenix ATC
The researchers evaluated the DBT based on both targeted micro-benchmarks and standard application benchmarks. They also compared it with the de-facto standard Qemu DBT system. The evaluation revealed that Captive delivers an average speedup of 2.21x over Qemu across SPEC CPU2006 integer benchmarks. In the case of floating-point applications, it shows further speedup reaching a 6.49x average. It also significantly reduces the effort required to support a new ISA, while delivering outstanding performance.
To know more about Captive, check out this USENIX ATC ’19 lightning talk by the authors:
SILK – a new open-source key-value store derived from RocksDB, designed to prevent latency spikes
By: Oana Balmau, Florin Dinu, and Willy Zwaenepoel, University of Sydney; Karan Gupta and Ravishankar Chandhiramoorthi, Nutanix, Inc.; Diego Didona, IBM Research–Zurich
Why SILK is needed
Latency-critical applications demand data platforms that can provide low latency and predictable throughput. Log-structured merge key-value stores (LSM KVs) were designed to handle such write-heavy workloads and large scale data where working set does not fit in the main memory. Some of the common LSM KVs are RocksDB, LevelD, and Cassandra that are widely adopted in production environments and claim to optimize the heavy workload. Despite these claims, the researchers show that tail latencies in state-of-the-art LSM KVs can be quite poor, particularly in the case of heavy and variable client write loads.
How SILK works
To address the aforementioned limitations, the researchers have come up with the notion of an I/O scheduler for LSM KVs, which aims to achieve the following three goals:
- Opportunistically allocating I/O bandwidth to internal operations
- Prioritizing internal operations at the lower levels of the tree.
- Preempting compactions.
This notion of I/O scheduler is implemented in SILK, a new open-source KV store derived from RocksDB. It is designed to prevent client request latency spikes. It uses this I/O scheduler to manage external client load and internal LSM maintenance work. It was tested on a production workload and synthetic benchmarks and was able to achieve up to two orders of magnitude lower 99th percentile latencies than RocksDB and TRIAD.
To know more about SILK, check out this USENIX ATC ’19 lightning talk by the authors:
Transactuations and its implementation, Relacs for building reliable IoT applications
By: Aritra Sengupta, Tanakorn Leesatapornwongsa, and Masoud Saeida Ardekani, Samsung Research; Cesar A. Stuardo, University of Chicago
Why transactuations and the Relacs runtime are needed
IoT applications are responsible for reading sensors, executing application logic, and taking action with actuators accordingly. One of the challenges developers face while building an IoT application is ensuring its correctness and reliability. Though current solutions do offer simple abstractions for reading and actuating, they lack high-level abstractions for writing reliable and fault-tolerant applications. Not properly handling failures can lead to inconsistencies between the physical and application state.
How transactuations and Relacs work
In this paper, the researchers introduced “transactuations”, which are similar to database transactions. These abstract the complexity of handling various failures and make it easy to maintain soft states so that they are consistent with respect to reads and writes to hard states. You need to specify dependencies among operations on soft and hard states along with sensing or actuating policy that specifies the conditions under which soft states can commit despite failures. Transactuation will then be responsible for preserving this dependence even in cases of hardware and communication failures and ensure isolation among transactuations that are executing concurrently.
The researchers have also introduced Relacs, a runtime system that implements the abstraction for a smart home platform. It first transforms an application into a serverless function and executes the application in the cloud while enforcing transactuation specific semantics.
The researchers further showed that transactuations are an effective solution for building reliable IoT applications. Using them also significantly reduces lines of code compared to manually handling failures. The Relacs runtime also guarantees reliable execution of transactuations while imposing reasonable overheads over a baseline that does not provide consistency between operations on hard states and soft states.
To know more about transactuations, check out this USENIX ATC ’19 lightning talk by the authors:
Browsix-Wasm – Run unmodified WebAssembly-compiled Unix applications inside the browser in a performant way
By: Abhinav Jangda, Bobby Powers, Emery D. Berger, and Arjun Guha, University of Massachusetts Amherst
Why Browsix-Wasm is needed
Major browsers today including Mozilla, Chrome, Safari, and Edge support WebAssembly, a small binary format that promises to bring near-native performance to the web. It serves as a portable compilation target for high-level languages like C, C++, and Rust.
One of the key goals of WebAssembly is performance parity with native code. The paper that introduced WebAssembly showed that its performance is competitive with native code. However, the evaluation was limited to a suite of scientific kernels rather than full applications with each consisting of about 100 lines of code.
The researchers conducted a comprehensive performance analysis using the established SPEC CPU benchmark suite of large programs. However, using such suites also pose a challenge, that is, currently it is not possible to simply compile a sophisticated native program to WebAssembly. These need operating system services such as a filesystem, synchronous I/O, and processes, which WebAssembly and the browser do not provide.
How Browsix-Wasm works
As a solution to this challenge, the researchers have built Browsix-Wasm, an extension to Browsix that allows running unmodified WebAssembly-compiled Unix applications directly inside the browser. They used Browsix-Wasm to conduct the very first large-scale evaluation of the performance of WebAssembly vs. native.
The evaluation results show a substantial performance gap across the SPEC CPU suite of benchmarks. The applications compiled to WebAssembly were slower by an average of 45% (Firefox) to 55% (Chrome), with peak slowdowns of 2.08$\times$ (Firefox) and 2.5$\times$ (Chrome). Some of the reasons behind this performance degradation were missing optimizations and code generation issues.
Here’s a chart showing the comparison between the performance analysis done on the basis of PolyBenchC (previous work) and SPEC CPU benchmarks.
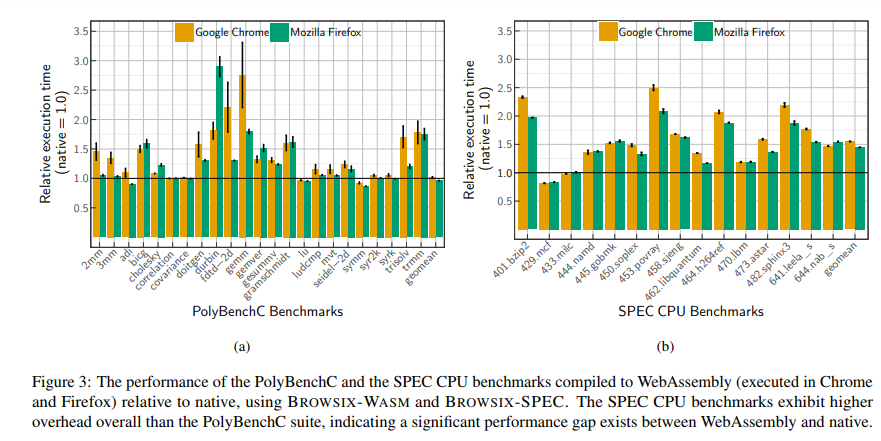
Source: Usenix ATC
To know more about Browsix-Wasm, check out this USENIX ATC ’19 lightning talk by the authors:
Zanzibar – Google’s global authorization system
By: Ruoming Pang, Ramon Caceres, Mike Burrows, Zhifeng Chen, Pratik Dave, Nathan Germer, Alexander Golynski, Kevin Graney, and Nina Kang, Jeffrey L. Korn, Christopher D. Richards and Mengzhi Wang, Google; Lea Kissner, Humu, Inc.; Abhishek Parmar, Carbon, Inc.
Why Zanzibar is needed
Every day online interactions involve the exchange of a lot of personal information. These interactions are authorized to ensure that a user has permission to perform an operation on a digital object. For instance, we have several web-based photo storage services that allow users to share a few photos with friends while keeping other photos private. These services must have checks in place to ensure that photos are shared before another user can view them. There are already many ways of authorization and developers constantly work on making them more robust to guarantee online privacy.
How Zanzibar works
The researchers have come up with Zanzibar, a system that allows you to store permissions and perform authorization checks based on the stored permissions. Many Google services use it including Calendar, Cloud, Drive, Maps, Photos, and YouTube.
Zanzibar takes up two roles:
- A storage system for Access Control Lists (ACLs) and groups.
- An authorization engine that interprets permissions.
It provides a uniform data model and language to define a wide range of access control policies. While making authorization decisions it takes into account the causal ordering of user actions to provide external consistency amid changes to access control lists and object contents.
Here’s a diagram depicting its architecture:
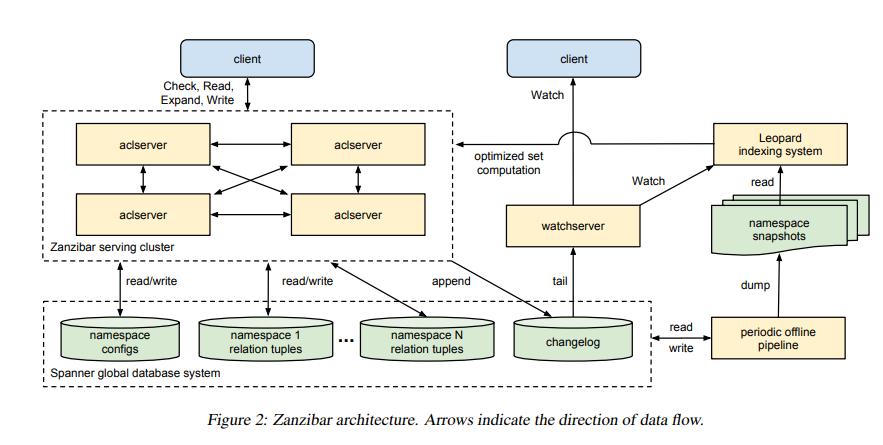
Source: Usenix ATC
Zanzibar is scalable to trillions of access control lists and millions of authorization requests per second to support services. In more than 3 years of production use at Google, it has maintained 95th-percentile latency of less than 10 milliseconds and availability of greater than 99.999%.
To know more about Zanzibar, check out this USENIX ATC ’19 lightning talk by the authors:
These were some of the papers presented at USENIX ATC 2019. You can find other research papers on its official website.
Read Next
Google Cloud and Nvidia Tesla set new AI training records with MLPerf benchmark results