In this article by Gaurav Barot, Chintan Mehta, and Amij Patel, authors of the book Hadoop Backup and Recovery Solutions, we will discuss backup and recovery needs. In the present age of information explosion, data is the backbone of business organizations of all sizes. We need a complete data backup and recovery system and a strategy to ensure that critical data is available and accessible when the organizations need it. Data must be protected against loss, damage, theft, and unauthorized changes. If disaster strikes, data recovery must be swift and smooth so that business does not get impacted. Every organization has its own data backup and recovery needs, and priorities based on the applications and systems they are using. Today's IT organizations face the challenge of implementing reliable backup and recovery solutions in the most efficient, cost-effective manner. To meet this challenge, we need to carefully define our business requirements and recovery objectives before deciding on the right backup and recovery strategies or technologies to deploy.
(For more resources related to this topic, see here.)
Before jumping onto the implementation approach, we first need to know about the backup and recovery strategies and how to efficiently plan them.
Understanding the backup and recovery philosophies
Backup and recovery is becoming more challenging and complicated, especially with the explosion of data growth and increasing need for data security today. Imagine big players such as Facebook, Yahoo! (the first to implement Hadoop), eBay, and more; how challenging it will be for them to handle unprecedented volumes and velocities of unstructured data, something which traditional relational databases can't handle and deliver. To emphasize the importance of backup, let's take a look at a study conducted in 2009. This was the time when Hadoop was evolving and a handful of bugs still existed in Hadoop. Yahoo! had about 20,000 nodes running Apache Hadoop in 10 different clusters.
HDFS lost only 650 blocks, out of 329 million total blocks. Now hold on a second. These blocks were lost due to the bugs found in the Hadoop package. So, imagine what the scenario would be now. I am sure you will bet on losing hardly a block. Being a backup manager, your utmost target is to think, make, strategize, and execute a foolproof backup strategy capable of retrieving data after any disaster. Solely speaking, the plan of the strategy is to protect the files in HDFS against disastrous situations and revamp the files back to their normal state, just like James Bond resurrects after so many blows and probably death-like situations.
Coming back to the backup manager's role, the following are the activities of this role:
Testing out various case scenarios to forestall any threats, if any, in the future
Building a stable recovery point and setup for backup and recovery situations
Preplanning and daily organization of the backup schedule
Constantly supervising the backup and recovery process and avoiding threats, if any
Repairing and constructing solutions for backup processes
The ability to reheal, that is, recover from data threats, if they arise (the resurrection power)
Data protection is one of the activities and it includes the tasks of maintaining data replicas for long-term storage
Resettling data from one destination to another
Basically, backup and recovery strategies should cover all the areas mentioned here. For any system data, application, or configuration, transaction logs are mission critical, though it depends on the datasets, configurations, and applications that are used to design the backup and recovery strategies. Hadoop is all about big data processing. After gathering some exabytes for data processing, the following are the obvious questions that we may come up with:
What's the best way to back up data?
Do we really need to take a backup of these large chunks of data?
Where will we find more storage space if the current storage space runs out?
Will we have to maintain distributed systems?
What if our backup storage unit gets corrupted?
The answer to the preceding questions depends on the situation you may be facing; let's see a few situations.
One of the situations is where you may be dealing with a plethora of data. Hadoop is used for fact-finding semantics and data is in abundance. Here, the span of data is short; it is short lived and important sources of the data are already backed up. Such is the scenario wherein the policy of not backing up data at all is feasible, as there are already three copies (replicas) in our data nodes (HDFS). Moreover, since Hadoop is still vulnerable to human error, a backup of configuration files and NameNode metadata (dfs.name.dir) should be created.
You may find yourself facing a situation where the data center on which Hadoop runs crashes and the data is not available as of now; this results in a failure to connect with mission-critical data. A possible solution here is to back up Hadoop, like any other cluster (the Hadoop command is Hadoop).
Replication of data using DistCp
To replicate data, the distcp command writes data to two different clusters. Let's look at the distcp command with a few examples or options.
DistCp is a handy tool used for large inter/intra cluster copying. It basically expands a list of files to input in order to map tasks, each of which will copy files that are specified in the source list.
Let's understand how to use distcp with some of the basic examples. The most common use case of distcp is intercluster copying. Let's see an example:
This command will expand the namespace under /parth/ghiya on the ka-16 NameNode into the temporary file, get its content, divide them among a set of map tasks, and start copying the process on each task tracker from ka-16 to ka-001.
The command used for copying can be generalized as follows:
Here, hftp://namenode-location:50070/basePath is the source and hdfs://namenode-location is the destination.
In the preceding command, namenode-location refers to the hostname and 50070 is the NameNode's HTTP server post.
Updating and overwriting using DistCp
The -update option is used when we want to copy files from the source that don't exist on the target or have some different contents, which we do not want to erase. The -overwrite option overwrites the target files even if they exist at the source.
The files can be invoked by simply adding -update and -overwrite.
In the example, we used distcp2, which is an advanced version of DistCp. The process will go smoothly even if we use the distcp command.
Now, let's look at two versions of DistCp, the legacy DistCp or just DistCp and the new DistCp or the DistCp2:
During the intercluster copy process, files that were skipped during the copy process have all their file attributes (permissions, owner group information, and so on) unchanged when we copy using legacy DistCp or just DistCp. This, however, is not the case in new DistCp. These values are now updated even if a file is skipped.
Empty root directories among the source inputs were not created in the target folder in legacy DistCp, which is not the case anymore in the new DistCp.
There is a common misconception that Hadoop protects data loss; therefore, we don't need to back up the data in the Hadoop cluster. Since Hadoop replicates data three times by default, this sounds like a safe statement; however, it is not 100 percent safe. While Hadoop protects from hardware failure on the data nodes—meaning that if one entire node goes down, you will not lose any data—there are other ways in which data loss may occur. Data loss may occur due to various reasons, such as Hadoop being highly susceptible to human errors, corrupted data writes, accidental deletions, rack failures, and many such instances. Any of these reasons are likely to cause data loss.
Consider an example where a corrupt application can destroy all data replications. During the process, it will attempt to compute each replication and on not finding a possible match, it will delete the replica. User deletions are another example of how data can be lost, as Hadoop's trash mechanism is not enabled by default.
Also, one of the most complicated and expensive-to-implement aspects of protecting data in Hadoop is the disaster recovery plan. There are many different approaches to this, and determining which approach is right requires a balance between cost, complexity, and recovery time.
A real-life scenario can be Facebook. The data that Facebook holds increases exponentially from 15 TB to 30 PB, that is, 3,000 times the Library of Congress. With increasing data, the problem faced was physical movement of the machines to the new data center, which required man power. Plus, it also impacted services for a period of time. Data availability in a short period of time is a requirement for any service; that's when Facebook started exploring Hadoop. To conquer the problem while dealing with such large repositories of data is yet another headache.
The reason why Hadoop was invented was to keep the data bound to neighborhoods on commodity servers and reasonable local storage, and to provide maximum availability to data within the neighborhood. So, a data plan is incomplete without data backup and recovery planning. A big data execution using Hadoop states a situation wherein the focus on the potential to recover from a crisis is mandatory.
The backup philosophy
We need to determine whether Hadoop, the processes and applications that run on top of it (Pig, Hive, HDFS, and more), and specifically the data stored in HDFS are mission critical. If the data center where Hadoop is running disappeared, will the business stop?
Some of the key points that have to be taken into consideration have been explained in the sections that follow; by combining these points, we will arrive at the core of the backup philosophy.
Changes since the last backup
Considering the backup philosophy that we need to construct, the first thing we are going to look at are changes. We have a sound application running and then we add some changes. In case our system crashes and we need to go back to our last safe state, our backup strategy should have a clause of the changes that have been made. These changes can be either database changes or configuration changes.
Our clause should include the following points in order to construct a sound backup strategy:
Changes we made since our last backup
The count of files changed
Ensure that our changes are tracked
The possibility of bugs in user applications since the last change implemented, which may cause hindrance and it may be necessary to go back to the last safe state
After applying new changes to the last backup, if the application doesn't work as expected, then high priority should be given to the activity of taking the application back to its last safe state or backup. This ensures that the user is not interrupted while using the application or product.
The rate of new data arrival
The next thing we are going to look at is how many changes we are dealing with. Is our application being updated so much that we are not able to decide what the last stable version was? Data is produced at a surpassing rate. Consider Facebook, which alone produces 250 TB of data a day. Data production occurs at an exponential rate. Soon, terms such as zettabytes will come upon a common place.
Our clause should include the following points in order to construct a sound backup:
The rate at which new data is arriving
The need for backing up each and every change
The time factor involved in backup between two changes
Policies to have a reserve backup storage
The size of the cluster
The size of a cluster is yet another important factor, wherein we will have to select cluster size such that it will allow us to optimize the environment for our purpose with exceptional results. Recalling the Yahoo! example, Yahoo! has 10 clusters all over the world, covering 20,000 nodes. Also, Yahoo! has the maximum number of nodes in its large clusters.
Our clause should include the following points in order to construct a sound backup:
Selecting the right resource, which will allow us to optimize our environment. The selection of the right resources will vary as per need. Say, for instance, users with I/O-intensive workloads will go for more spindles per core. A Hadoop cluster contains four types of roles, that is, NameNode, JobTracker, TaskTracker, and DataNode.
Handling the complexities of optimizing a distributed data center.
Priority of the datasets
The next thing we are going to look at are the new datasets, which are arriving. With the increase in the rate of new data arrivals, we always face a dilemma of what to backup. Are we tracking all the changes in the backup? Now, if are we backing up all the changes, will our performance be compromised?
Our clause should include the following points in order to construct a sound backup:
Making the right backup of the dataset
Taking backups at a rate that will not compromise performance
Selecting the datasets or parts of datasets
The next thing we are going to look at is what exactly is backed up. When we deal with large chunks of data, there's always a thought in our mind: Did we miss anything while selecting the datasets or parts of datasets that have not been backed up yet?
Our clause should include the following points in order to construct a sound backup:
Backup of necessary configuration files
Backup of files and application changes
The timeliness of data backups
With such a huge amount of data collected daily (Facebook), the time interval between backups is yet another important factor. Do we back up our data daily? In two days? In three days? Should we backup small chunks of data daily, or should we back up larger chunks at a later period?
Our clause should include the following points in order to construct a sound backup:
Dealing with any impacts if the time interval between two backups is large
Monitoring a timely backup strategy and going through it
The frequency of data backups depends on various aspects. Firstly, it depends on the application and usage. If it is I/O intensive, we may need more backups, as each dataset is not worth losing. If it is not so I/O intensive, we may keep the frequency low.
Unlock access to the largest independent learning library in Tech for FREE!
Get unlimited access to 7500+ expert-authored eBooks and video courses covering every tech area you can think of.
Renews at $19.99/month. Cancel anytime
We can determine the timeliness of data backups from the following points:
The amount of data that we need to backup
The rate at which new updates are coming
Determining the window of possible data loss and making it as low as possible
Critical datasets that need to be backed up
Configuration and permission files that need to be backed up
Reducing the window of possible data loss
The next thing we are going to look at is how to minimize the window of possible data loss. If our backup frequency is great then what are the chances of data loss? What's our chance of recovering the latest files?
Our clause should include the following points in order to construct a sound backup:
The potential to recover latest files in the case of a disaster
Having a low data-loss probability
Backup consistency
The next thing we are going to look at is backup consistency. The probability of invalid backups should be less or even better zero. This is because if invalid backups are not tracked, then copies of invalid backups will be made further, which will again disrupt our backup process.
Our clause should include the following points in order to construct a sound backup:
Avoid copying data when it's being changed
Possibly, construct a shell script, which takes timely backups
Ensure that the shell script is bug-free
Avoiding invalid backups
We are going to continue the discussion on invalid backups. As you saw, HDFS makes three copies of our backup for the recovery process. What if the original backup was flawed with errors or bugs? The three copies will be corrupted copies; now, when we recover these flawed copies, the result indeed will be a catastrophe.
Our clause should include the following points in order to construct a sound backup:
Avoid having a long backup frequency
Have the right backup process, and probably having an automated shell script
Track unnecessary backups
If our backup clause covers all the preceding mentioned points, we surely are on the way to making a good backup strategy. A good backup policy basically covers all these points; so, if a disaster occurs, it always aims to go to the last stable state. That's all about backups. Moving on, let's say a disaster occurs and we need to go to the last stable state. Let's have a look at the recovery philosophy and all the points that make a sound recovery strategy.
The recovery philosophy
After a deadly storm, we always try to recover from the after-effects of the storm. Similarly, after a disaster, we try to recover from the effects of the disaster. In just one moment, storage capacity which was a boon turns into a curse and just another expensive, useless thing. Starting off with the best question, what will be the best recovery philosophy? Well, it's obvious that the best philosophy will be one wherein we may never have to perform recovery at all. Also, there may be scenarios where we may need to do a manual recovery.
Let's look at the possible levels of recovery before moving on to recovery in Hadoop:
Recovery to the flawless state
Recovery to the last supervised state
Recovery to a possible past state
Recovery to a sound state
Recovery to a stable state
So, obviously we want our recovery state to be flawless. But if it's not achieved, we are willing to compromise a little and allow the recovery to go to a possible past state we are aware of. Now, if that's not possible, again we are ready to compromise a little and allow it to go to the last possible sound state. That's how we deal with recovery: first aim for the best, and if not, then compromise a little.
Just like the saying goes, "The bigger the storm, more is the work we have to do to recover," here also we can say "The bigger the disaster, more intense is the recovery plan we have to take."
So, the recovery philosophy that we construct should cover the following points:
An automation system setup that detects a crash and restores the system to the last working state, where the application runs as per expected behavior.
The ability to track modified files and copy them.
Track the sequences on files, just like an auditor trails his audits.
Merge the files that are copied separately.
Multiple version copies to maintain a version control.
Should be able to treat the updates without impacting the application's security and protection.
Delete the original copy only after carefully inspecting the changed copy.
Treat new updates but first make sure they are fully functional and will not hinder anything else. If they hinder, then there should be a clause to go to the last safe state.
Coming back to recovery in Hadoop, the first question we may think of is what happens when the NameNode goes down? When the NameNode goes down, so does the metadata file (the file that stores data about file owners and file permissions, where the file is stored on data nodes and more), and there will be no one present to route our read/write file request to the data node.
Our goal will be to recover the metadata file. HDFS provides an efficient way to handle name node failures. There are basically two places where we can find metadata. First, fsimage and second, the edit logs.
Our clause should include the following points:
Maintain three copies of the name node.
When we try to recover, we get four options, namely, continue, stop, quit, and always. Choose wisely.
Give preference to save the safe part of the backups. If there is an ABORT! error, save the safe state.
Hadoop provides four recovery modes based on the four options it provides (continue, stop, quit, and always):
Continue: This allows you to continue over the bad parts. This option will let you cross over a few stray blocks and continue over to try to produce a full recovery mode. This can be the Prompt when found error mode.
Stop: This allows you to stop the recovery process and make an image file of the copy. Now, the part that we stopped won't be recovered, because we are not allowing it to. In this case, we can say that we are having the safe-recovery mode.
Quit: This exits the recovery process without making a backup at all. In this, we can say that we are having the no-recovery mode.
Always: This is one step further than continue. Always selects continue by default and thus avoids stray blogs found further. This can be the prompt only once mode.
We will look at these in further discussions. Now, you may think that the backup and recovery philosophy is cool, but wasn't Hadoop designed to handle these failures? Well, of course, it was invented for this purpose but there's always the possibility of a mashup at some level. Are we overconfident and not ready to take precaution, which can protect us, and are we just entrusting our data blindly with Hadoop? No, certainly we aren't. We are going to take every possible preventive step from our side. In the next topic, we look at the very same topic as to why we need preventive measures to back up Hadoop.
Knowing the necessity of backing up Hadoop
Change is the fundamental law of nature. There may come a time when Hadoop may be upgraded on the present cluster, as we see many system upgrades everywhere. As no upgrade is bug free, there is a probability that existing applications may not work the way they used to. There may be scenarios where we don't want to lose any data, let alone start HDFS from scratch.
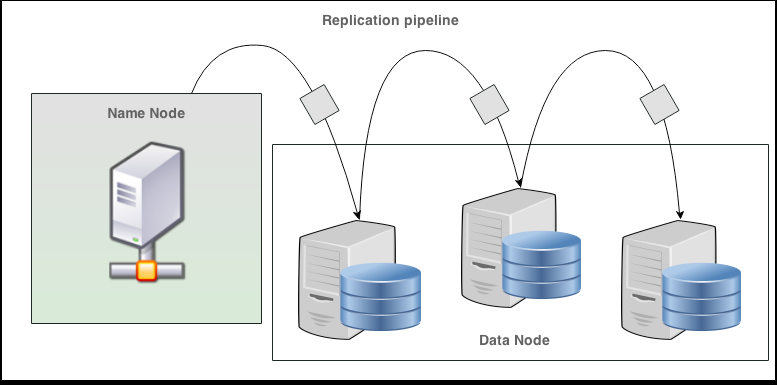
This is a scenario where backup is useful, so a user can go back to a point in time. Looking at the HDFS replication process, the NameNode handles the client request to write a file on a DataNode. The DataNode then replicates the block and writes the block to another DataNode. This DataNode repeats the same process. Thus, we have three copies of the same block. Now, how these DataNodes are selected for placing copies of blocks is another issue, which we are going to cover later in Rack awareness. You will see how to place these copies efficiently so as to handle situations such as hardware failure. But the bottom line is when our DataNode is down there's no need to panic; we still have a copy on a different DataNode.
Now, this approach gives us various advantages such as:
Security: This ensures that blocks are stored on two different DataNodes
High write capacity: This writes only on a single DataNode; the replication factor is handled by the DataNode
Read options: This denotes better options from where to read; the NameNode maintains records of all the locations of the copies and the distance from the NameNode
Block circulation: The client writes only a single block; others are handled through the replication pipeline
During the write operation on a DataNode, it receives data from the client as well as passes data to the next DataNode simultaneously; thus, our performance factor is not compromised. Data never passes through the NameNode. The NameNode takes the client's request to write data on a DataNode and processes the request by deciding on the division of files into blocks and the replication factor.
The following figure shows the replication pipeline, wherein a block of the file is written and three different copies are made at different DataNode locations:
After hearing such a foolproof plan and seeing so many advantages, we again arrive at the same question: is there a need for backup in Hadoop? Of course there is. There often exists a common mistaken belief that Hadoop shelters you against data loss, which gives you the freedom to not take backups in your Hadoop cluster. Hadoop, by convention, has a facility to replicate your data three times by default. Although reassuring, the statement is not safe and does not guarantee foolproof protection against data loss. Hadoop gives you the power to protect your data over hardware failures; the scenario wherein one disk, cluster, node, or region may go down, data will still be preserved for you. However, there are many scenarios where data loss may occur.
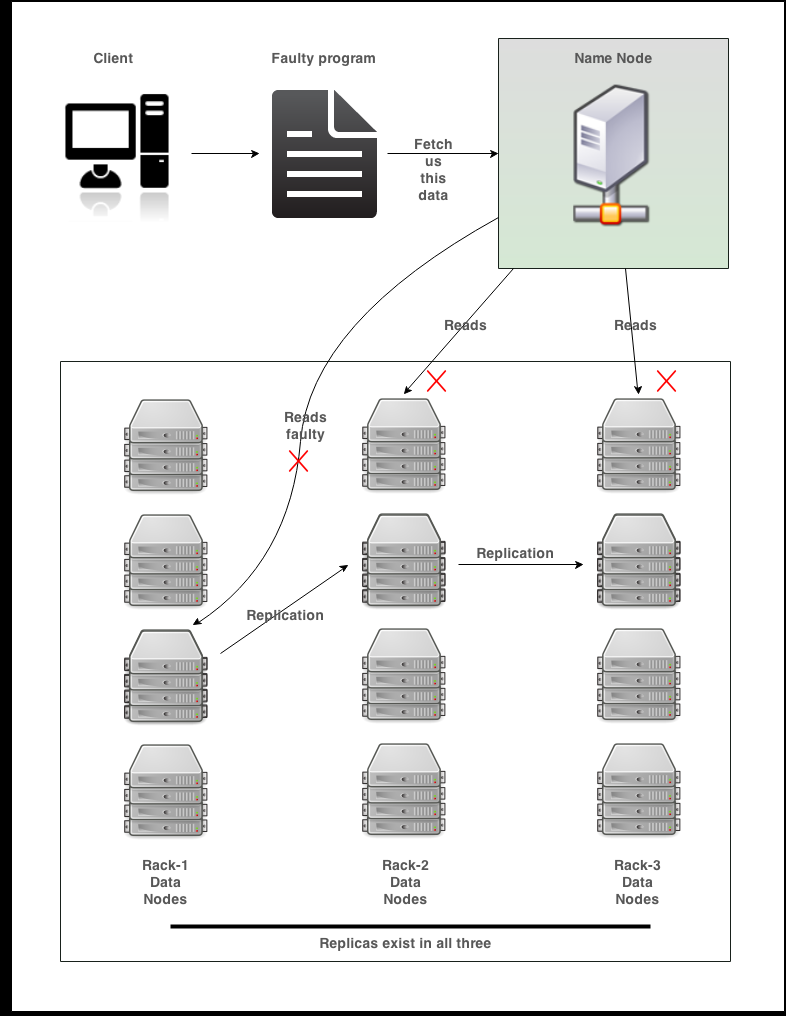
Consider an example where a classic human-prone error can be the storage locations that the user provides during operations in Hive. If the user provides a location wherein data already exists and they perform a query on the same table, the entire existing data will be deleted, be it of size 1 GB or 1 TB.
In the following figure, the client gives a read operation but we have a faulty program. Going through the process, the NameNode is going to see its metadata file for the location of the DataNode containing the block. But when it reads from the DataNode, it's not going to match the requirements, so the NameNode will classify that block as an under replicated block and move on to the next copy of the block. Oops, again we will have the same situation. This way, all the safe copies of the block will be transferred to under replicated blocks, thereby HDFS fails and we need some other backup strategy:
When copies do not match the way NameNode explains, it discards the copy and replaces it with a fresh copy that it has.
HDFS replicas are not your one-stop solution for protection against data loss.
The needs for recovery
Now, we need to decide up to what level we want to recover. Like you saw earlier, we have four modes available, which recover either to a safe copy, the last possible state, or no copy at all. Based on your needs decided in the disaster recovery plan we defined earlier, you need to take appropriate steps based on that.
We need to look at the following factors:
The performance impact (is it compromised?)
How large is the data footprint that my recovery method leaves?
What is the application downtime?
Is there just one backup or are there incremental backups?
Is it easy to implement?
What is the average recovery time that the method provides?
Based on the preceding aspects, we will decide which modes of recovery we need to implement. The following methods are available in Hadoop:
Snapshots: Snapshots simply capture a moment in time and allow you to go back to the possible recovery state.
Replication: This involves copying data from one cluster and moving it to another cluster, out of the vicinity of the first cluster, so that if one cluster is faulty, it doesn't have an impact on the other.
Manual recovery: Probably, the most brutal one is moving data manually from one cluster to another. Clearly, its downsides are large footprints and large application downtime.
API: There's always a custom development using the public API available. We will move on to the recovery areas in Hadoop.
Understanding recovery areas
Recovering data after some sort of disaster needs a well-defined business disaster recovery plan. So, the first step is to decide our business requirements, which will define the need for data availability, precision in data, and requirements for the uptime and downtime of the application. Any disaster recovery policy should basically cover areas as per requirements in the disaster recovery principal. Recovery areas define those portions without which an application won't be able to come back to its normal state. If you are armed and fed with proper information, you will be able to decide the priority of which areas need to be recovered.
Recovery areas cover the following core components:
Datasets
NameNodes
Applications
Database sets in HBase
Let's go back to the Facebook example. Facebook uses a customized version of MySQL for its home page and other interests. But when it comes to Facebook Messenger, Facebook uses the NoSQL database provided by Hadoop. Now, looking from that point of view, Facebook will have both those things in recovery areas and will need different steps to recover each of these areas.
Summary
In this article, we went through the backup and recovery philosophy and what all points a good backup philosophy should have. We went through what a recovery philosophy constitutes. We saw the modes available for recovery in Hadoop. Then, we looked at why backup is important even though HDFS provides the replication process.
Lastly, we looked at the recovery needs and areas. Quite a journey, wasn't it? Well, hold on tight. These are just your first steps into Hadoop User Group (HUG).

 United States
United States
 Great Britain
Great Britain
 India
India
 Germany
Germany
 France
France
 Canada
Canada
 Russia
Russia
 Spain
Spain
 Brazil
Brazil
 Australia
Australia
 Singapore
Singapore
 Canary Islands
Canary Islands
 Hungary
Hungary
 Ukraine
Ukraine
 Luxembourg
Luxembourg
 Estonia
Estonia
 Lithuania
Lithuania
 South Korea
South Korea
 Turkey
Turkey
 Switzerland
Switzerland
 Colombia
Colombia
 Taiwan
Taiwan
 Chile
Chile
 Norway
Norway
 Ecuador
Ecuador
 Indonesia
Indonesia
 New Zealand
New Zealand
 Cyprus
Cyprus
 Denmark
Denmark
 Finland
Finland
 Poland
Poland
 Malta
Malta
 Czechia
Czechia
 Austria
Austria
 Sweden
Sweden
 Italy
Italy
 Egypt
Egypt
 Belgium
Belgium
 Portugal
Portugal
 Slovenia
Slovenia
 Ireland
Ireland
 Romania
Romania
 Greece
Greece
 Argentina
Argentina
 Netherlands
Netherlands
 Bulgaria
Bulgaria
 Latvia
Latvia
 South Africa
South Africa
 Malaysia
Malaysia
 Japan
Japan
 Slovakia
Slovakia
 Philippines
Philippines
 Mexico
Mexico
 Thailand
Thailand