









[box type=”note” align=”” class=”” width=””]The following excerpt is taken from the book MySQL 8 Administrator’s Guide, co-authored by Chintan Mehta, Ankit Bhavsar, Hetal Oza and Subhash Shah. This book presents an in-depth view of the newly released features of MySQL 8 and how you can leverage them to administer a high-performance MySQL solution.[/box]
Following the best practices for the configuration of MySQL helps us design and manage efficient database, and are quite a cherry on top – without which, it might seem a bit incomplete. In addition to configuration, benchmarking helps us validate and find bottlenecks in the database system and address them. In this article, we look at specific areas that will help us understand the best practices for configuration and performance benchmarking.
1. Resource utilization
IO activity, CPU, and memory usage is something that you should not miss out. These metrics help us know how the system is performing while doing benchmarking and at the time of scaling. It also helps us derive impacts per transaction.
2. Stretching your benchmarking timelines
We may often like to have a quick glance at performance metrics; however, ensuring that MySQL behaves in the same way for a longer duration of testing is also a key element. There is some basic stuff that might impact on performance when you stretch your benchmark timelines, such as memory fragmentation, degradation of IO, impact after data accumulation, cache management, and so on.
We don’t want our database to get restarted just to clean up junk items, correct? Therefore, it is suggested to run benchmarking for a long duration for stability and performance Validation.
3. Replicating production settings
Let’s benchmark in a production-replicated environment. Wait! Let’s disable database replication in a replica environment until we are done with benchmarking. Gotcha! We have got some good numbers! It often happens that we don’t simulate everything completely that we are going to configure in the production environment. It could prove to be costly, as we might unintentionally be benchmarking something in an environment that might have an adverse impact when it’s in production. Replicate production settings, data, workload, and so on in your replicated environment while you do benchmarking.
4. Consistency of throughput and latency
Throughput and latency go hand in hand. It is important to keep your eyes primarily focused on throughput; however, latency over time might be something to look out for. Performance dips, slowness, or stalls were noticed in InnoDB in its earlier days. It has improved a lot since then, but as there might be other cases depending on your workload, it is always good to keep an eye on throughput along with latency.
5. Sysbench can do more
Sysbench is a wonderful tool to simulate your workloads, whether it be thousands of tables, transaction intensive, data in-memory, and so on. It is a splendid tool to simulate and gives you nice representation.
6. Virtualization world
I would like to keep this simple; bare metal as compared to virtualization isn’t the same. Hence, while doing benchmarking, measure your resources according to your environment. You might be surprised to see the difference in results if you compare both.
7. Concurrency
Big data is seated on heavy data workload; high concurrency is important. MySQL 8 is extending its maximum CPU core support in every new release, optimizing concurrency based on your requirements and hardware resources should be taken care of.
8. Hidden workloads
Do not miss out factors that run in the background, such as reporting for big data analytics, backups, and on-the-fly operations while you are benchmarking. The impact of such hidden workloads or obsolete benchmarking workloads can make your days (and nights) Miserable.
9. Nerves of your query
Oops! Did we miss the optimizer? Not yet. An optimizer is a powerful tool that will read the nerves of your query and provide recommendations. It’s a tool that I use before making changes to a query in production. It’s a savior when you have complex queries to be optimized.
These are a few areas that we should look out for. Let’s now look at a few benchmarks that we did on MySQL 8 and compare them with the ones on MySQL 5.7.
10. Benchmarks
To start with, let’s fetch all the column names from all the InnoDB tables. The following is the query that we executed:
SELECT t.table_schema, t.table_name, c.column_name
FROM information_schema.tables t,
information_schema.columns c
WHERE t.table_schema = c.table_schema
AND t.table_name = c.table_name
AND t.engine='InnoDB';The following figure shows how MySQL 8 performed a thousand times faster when having four instances:
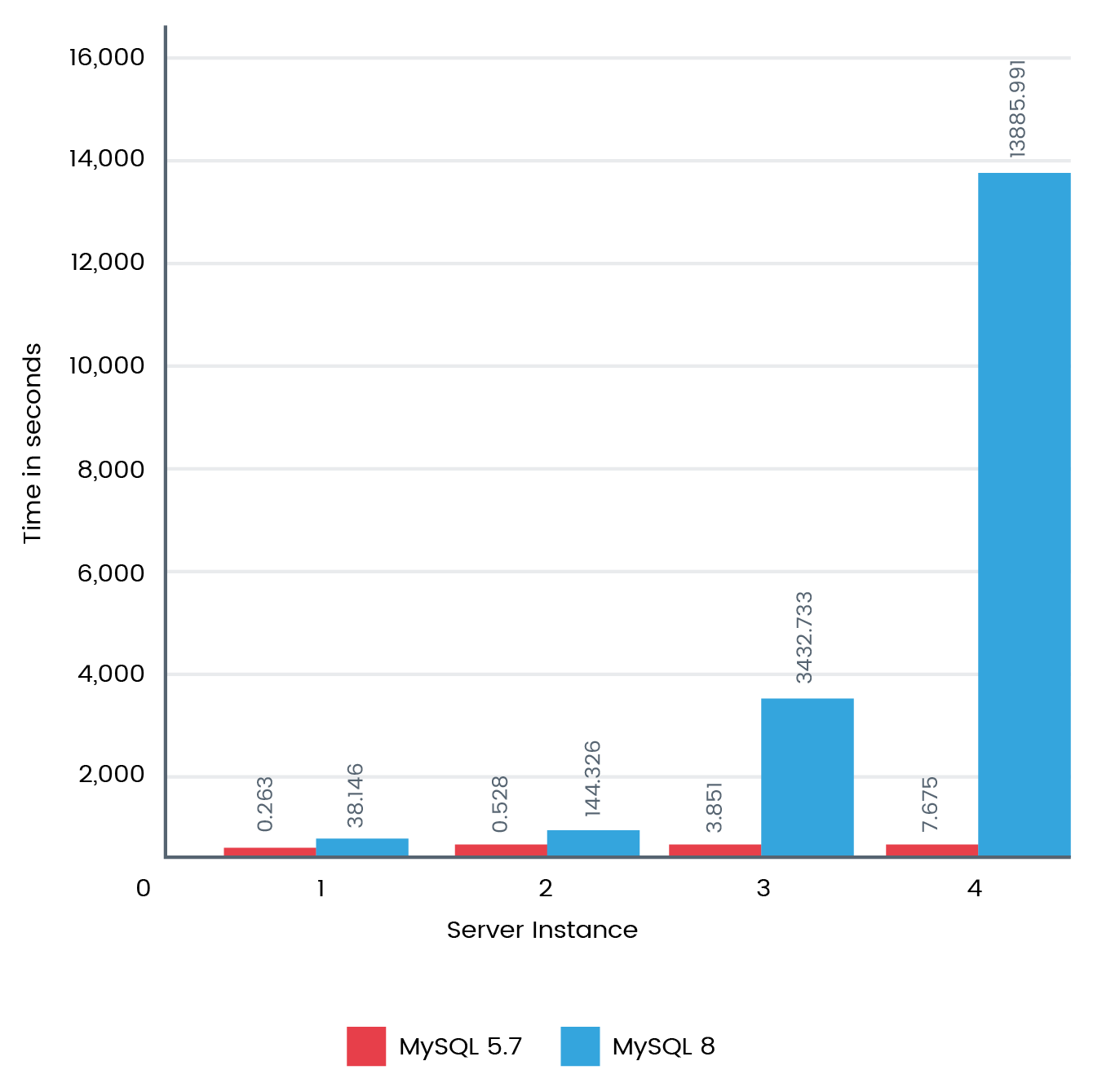
Following this, we also performed a benchmark to find static table metadata. The following is the query that we executed:
SELECT TABLE_SCHEMA, TABLE_NAME, TABLE_TYPE, ENGINE, ROW_FORMAT
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA LIKE 'chintan%';The following figure shows how MySQL 8 performed around 30 times faster than MySQL 5.7:
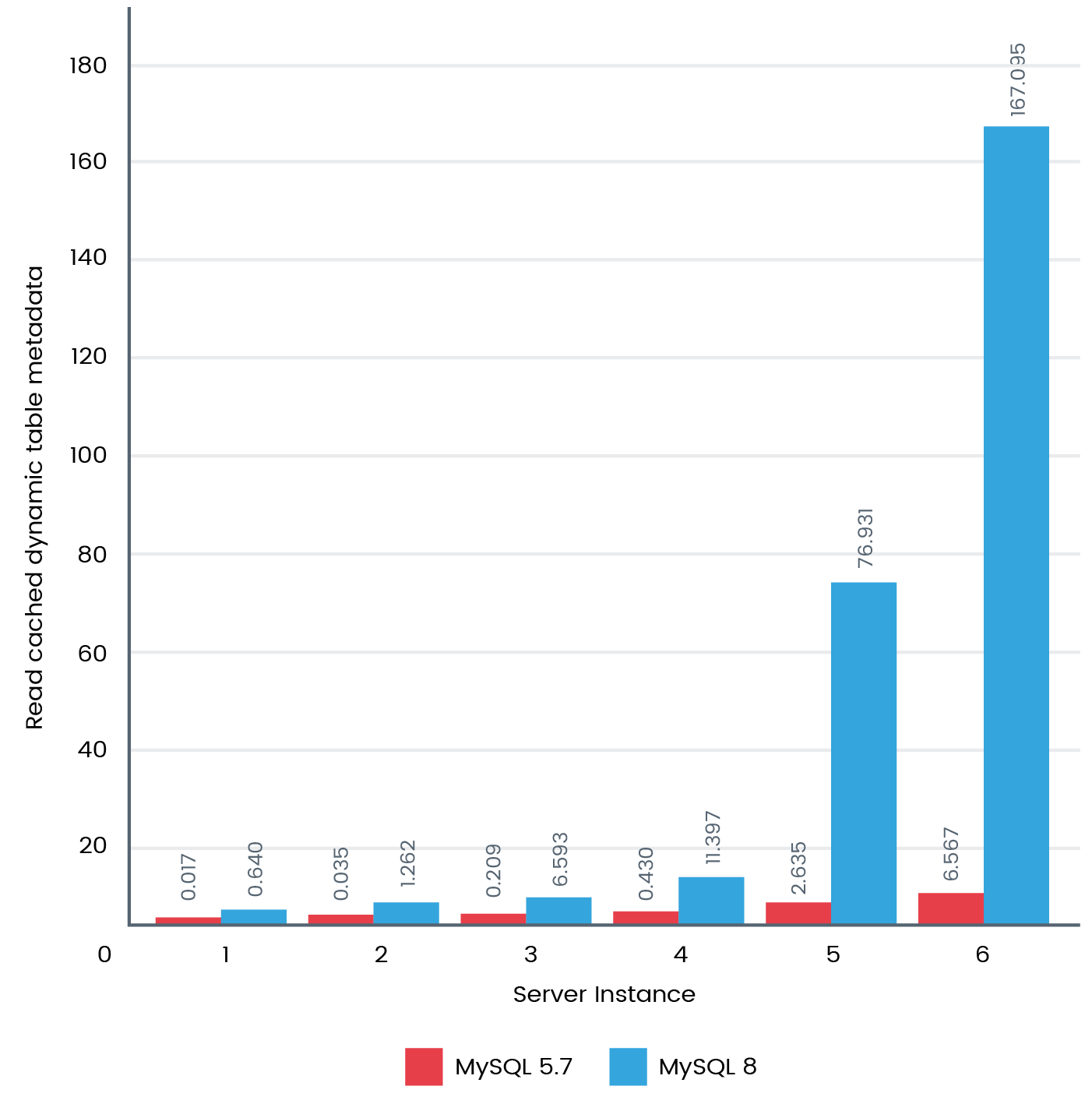
It made us eager to go into a bit more detail. So, we thought of doing one last test to find dynamic table metadata. The following is the query that we executed:
SELECT TABLE_ROWS
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA LIKE 'chintan%';The following figure shows how MySQL 8 performed around 30 times faster than MySQL 5.7:
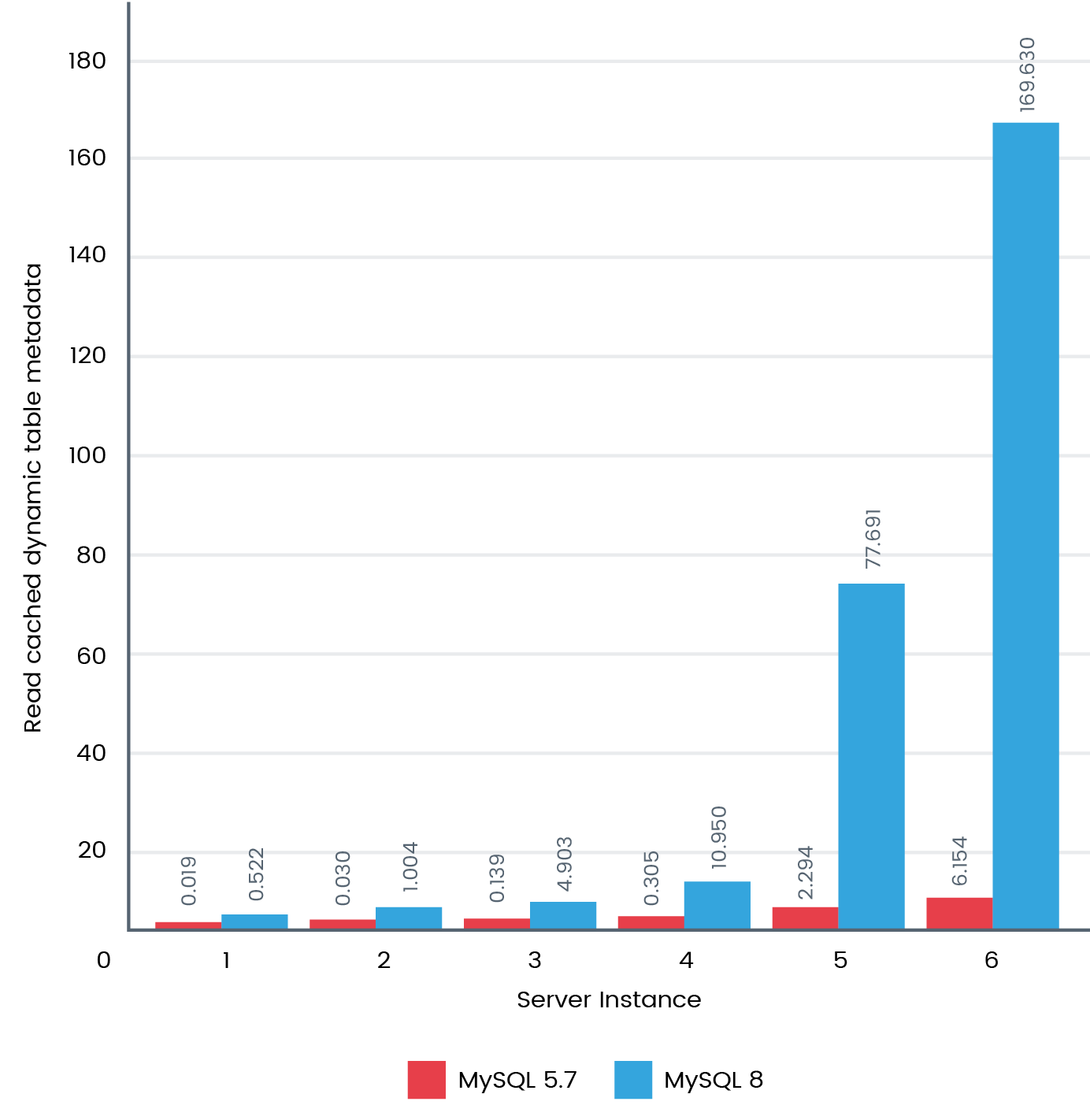
MySQL 8.0 brings enormous performance improvement to the table. Scaling from one to million tables, is a need for big data requirements, which is now achievable. We look forward to more benchmarks being officially released once MySQL 8 is available for general purpose.
If you found this post useful, make sure to check out the book MySQL 8 Administrator’s Guide for more tips and tricks to manage MySQL 8 effectively.
Read Next
MySQL 8.0 is generally available with added features
New updates to Microsoft Azure services for SQL Server, MySQL, and PostgreSQL