









Generative adversarial networks (GANs) have been at the forefront of research on generative models in the last couple of years. GANs have been used for image generation, image processing, image synthesis from captions, image editing, visual domain adaptation, data generation for visual recognition, and many other applications, often leading to state of the art results. One of the tutorials titled, ‘Generative Adversarial Networks’ conducted at the CVPR 2018 (a Conference on Computer Vision and Pattern Recognition held at Salt Lake City, USA) provides a broad overview of generative adversarial networks and how GANs can be trained to perform different purposes.
The tutorial involved various speakers sharing basic concepts, best practices of the current state-of-the-art GAN including network architectures, objective functions, other training tricks, and much more. Let us look at how GANs are trained for different use cases.
| There’s more to GANs….. If you further want to explore different examples of modern GAN implementations, including CycleGAN, simGAN, DCGAN, and 2D image to 3D model generation, you can explore the book, Generative Adversarial Networks Cookbook written by Josh Kalin. The recipes given in this cookbook will help you build on a common architecture in Python, TensorFlow and Keras to explore increasingly difficult GAN architectures in an easy-to-read format. |
Training GANs for object detection using Adversarial Learning
Xialong Wang, from Carnegie Mellon University talked about object detection in computer vision as well as from the context of taking actions in robots. He also explained how to use adversarial learning for instances beyond image generation.
To train a GAN, the key idea is to find the adversarial tasks for your target tasks to improve your target by fighting against these adversarial tasks. In computer vision if your target task is to recognize a bird using object detection, one adversarial task is adding occlusions by generating a mask to accrue the bird’s head and its leg which will make it difficult for the detector to recognize. The detector will further try to conquer these difficult tasks and from then on it will become robust to Occlusions. Another adversarial task for object detection can be Deformations. Here the image can be slightly rotated to make the detection difficult.

For training robots to grasp objects, one of the adversaries would be the Shaking test. If the robot arm is stable enough the object it grasps should not fall even with a rigourous shake. Another example is snatching. If another arm can snatch easily, it means it is not completely trained to resist snatching or stealing.
Wang said the CMU research team tried generating images using DCGAN on the COCO dataset. However, the images generated could not assist in training the detector as the detectors could easily detect them as false images. Next, the team generated images using Conditional GANs on COCO but these didn’t help either. Hence, the team generated hard positive examples in feed by adding real world occlusions or real world deformations to challenge the detectors.

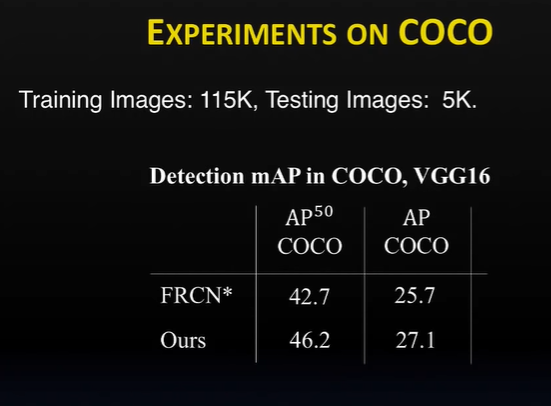
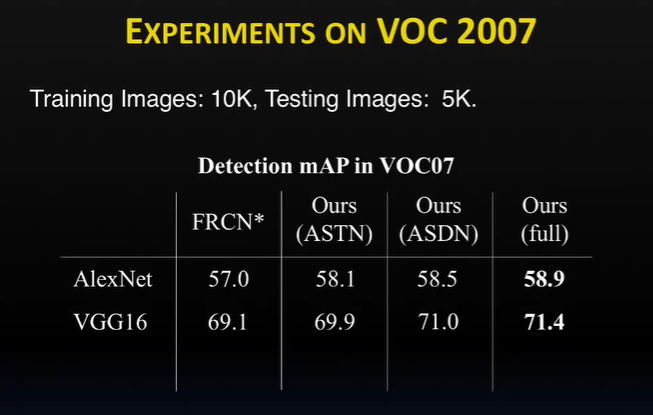
He then talked about a Standard Fast R-CNN Detector which takes an image input in the convolutional neural network language model. After taking the input, the detector extracts features for the whole image, and later you can crop the features according to the proposal bounding box. These cropped features are resized to channel (C*6*6); here 6*6 is interred spatial dimensions. These features are the object features you want to focus on and can also use them to perform classification or regression for detections. The team has added a small network in the middle that would input the extracted features and generate a mask. The mask will assist which spatial locations to chop out certain features that would make it hard for the detectors to recognize. He also shared the benchmark results of the tests using different datasets like the AlexNet, VGG16, FRCN, and so on. The ASTN and the ASDN model showed improved output over the other networks.
Understanding Generative Adversarial Imitation Learning (GAIL) for training a machine to imitate human behaviours
Stefano Ermon from Stanford University explained how to use Generative modeling ideas and GAN training to imitate human behaviours in complex environments.
A lot of progress in reinforcement learning has been made with successes in playing board games such as Chess, video games, and so on. However, Reinforcement Learning has one limitation. If you want to use it to solve a new task you have to specify a cost signal / a reward signal to provide some supervision to your reinforcement learning algorithm. You also need to specify what kind of behaviors are desirable and which are not.
In a game scenario the cost signal is whether you win or you lose. However, in further complex tasks like driving an autonomous vehicles to specify a cost signal becomes difficult as there are different objective functions like going off road, not moving above the speed limit, avoiding a road crash, and much more.
The simplest method one can use is Behavioural cloning where you can use your trajectories and your demonstrations to construct a training set of states with the corresponding action that the expert took in those states. You can further use your favorite supervised learning method classification or regression if the actions are continuous.
However, this has some limitations:
- Small errors may compound over time as the learning algorithm will make certain mistakes initially and these mistakes will lead towards never seen before states or objects.
- It is like a Black box approach where every decision requires initial planning.
Ermon suggests an alternative to imitation could be an Inverse RL (IRL) approachHe also demonstrates the similarities between RL and IRL. For the complete demonstration, you can check out the video.
The main difference between a GAIL and GANs is that in GANs the generator is taking inputs, random noise and maps them to the neural network producing some samples for the detector. However, in GAIL, the generator is more complex as it includes two components, a policy P which you can train and an environment (Black Box simulator) that can’t be controlled. What matters is the distribution over states and actions that you encounter when you navigate the environment using the policy that can be tuned. As the environment is difficult to control, training the GAIL model is harder than the simple GANs model. On the other hand, in a GANs model, training the policy is challenging such that the discriminator goes into the direction of fooling.
However, GAIL is the easier generative modelling task because you don’t have to learn the whole thing end to end and neither do you have to come up with a large neural network that maps noise into behaviours as some part of the input is given by the environment. But it is harder to train because you don’t really know how the black box works.
Ermon further explains how using Generative Adversarial Imitation Learning, one can not only imitate complex behaviors, but also learn interpretable and meaningful representations of complex behavioral data, including visual demonstrations with a method named as InfoGAN, a method, built on top of GAIL.
He also explained a new framework for multi-agent imitation learning for general Markov games by integrating multi-agent RL with a suitable extension of multi-agent inverse RL. This method will generalize Generative Adversarial Imitation Learning (GAIL) in the single agent case. This method will successfully imitate complex behaviors in high-dimensional environments with multiple cooperative or competing agents.
To know more about further demonstrations on GAIL, InfoGAIL, and Multi-agent GAIL, watch the complete video on YouTube.
Knowing the basics isn’t enough, putting them to practice is necessary. If you want to use GANs practically and experiment with them, Generative Adversarial Networks Cookbook by Josh Kalin is your go-to guide. With this cookbook, you will work with use cases involving DCGAN, Pix2Pix, and so on. To understand these complex applications, you will take different real-world data sets and put them to use.




