









With the release of Alexa Auto Software Development Kit (SDK) the integration of Alexa into in-vehicle infotainment systems will become easier for the developers. Currently, the SDK assumes that automotive systems will have access to the cloud all the time, but it would be better if Alexa-enabled vehicles have some core functions even when they’re offline. This means that we need to reduce the size of the underlying machine-learning models, so they can fit in local memory.
In this year’s Interspeech, Grant Strimel with his colleagues will present a new technique for compressing machine-learning models that could reduce their memory footprints by 94% while leaving their performance almost unchanged.
What is the aim behind statistical model compression?
Amazon Alexa and Google Assistant support skills built by external developers. These skills have Natural Language Understanding (NLU) models that extend the functionality of the main NLU models. Because there are numerous skills, their NLU models are loaded on demand only when they are needed to process a request. If the skill’s NLU model is large, loading them into memory adds significant latency to utterance recognition. To provide quick NLU response and good customer experience, small-footprint NLU models are important.
Also, cloud-based NLU is unsuitable for local system deployment without appropriate compression because it has large memory footprints. To solve this, Grant and his colleagues have designed an algorithm which take large statistical NLU models and produce models which are equally predictive but have smaller memory footprint.
What are the techniques introduced?
Alexa’s NLU systems use several different types of machine learning models, but they all share some common traits. One common trait that Alexa’s NLU systems share is, extracting features (strings of text with particular predictive value) from input utterances.
Another common trait is that each feature has a set of associated weights, which determines how large a role it should play in different types of computation. These weights of millions of features are stored, making the ML models memory intensive.
Two techniques are proposed to perform statistical model compression:
Quantization
The first technique for compressing an ML model is to quantize the feature weights:
- Take the total range of weights
- Divide the range into equal intervals
- Finally, round each weight off to the nearest boundary value for its interval
Currently, 256 intervals are used, allowing the representation of every weight in the model with a single byte of data, with minimal effect on the network’s accuracy. The additional benefit is that the low weights are discarded because they are rounded off to zero.
Perfect Hashing
In this technique we use hashing to perform mapping a particular feature to the memory locations of the corresponding weight. For example, play ‘Yesterday,’ by the Beatles,” we want our system to pull up the weights associated with the feature “the Beatles” — not the weights associated with “Adele”, “Elton John”, and the rest.
To perform such mappings we will use hashing. A hash function is a function, which maps arbitrary sized inputs and maps them with fixed sized outputs and also have no predictable relationship to the inputs. One side effect of hashing is that it sometimes produces collisions, which means, two inputs that hash to the same output.
The collision problem is addressed through perfect hashing:
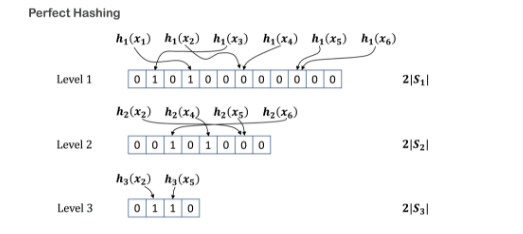
- We first assume that we have access to a family of conventional hash functions, all of which produce random hashes. For this we use the hash function MurmurHash, which can be seeded with a succession of different values.
- We represent the input strings to be hashed by N. We begin with an array of N 0’s and apply our first hash function called Hash1. We change a 0 in the array to a 1 for every string that yields a unique hash value.
- Next, a new array of 0’s is built for only the strings that yielded collisions under Hash1. We apply a different hash function to those strings. Similar to step 2, we toggle the 0’s to collision-free hashes.
- This process is repeated until every input string has a corresponding 1 in some array.
- All these arrays are then combined into one giant array. The position of a 1 in this giant array indicates the unique memory location assigned to the corresponding string.
- When the trained input receives an unseen input string, it will apply Hash1 to each of the input’s substrings and, if it finds a 1 in the first array, it goes to the associated address. If it finds a 0, it applies Hash2 and repeats the process.
This process does causes a slight performance problem, but it’s a penalty that’s only paid when a collision occurs.
To know more about the statistical model compression you can visit the Amazon Alexa page and also check out the technical paper by the researchers.
Read Next
Amazon Alexa and AWS helping NASA improve their efficiency