









In this article by Jasmin Azemović, author of the book SQL Server 2017 for Linux, we will cover basic a overview of SQL server and learn about backup.
Linux, or to be precise GNU/Linux, is one of the best alternatives to Windows; and in many cases, it is the first choice of environment for daily tasks such as system administration, running different kinds of services, or just a tool for desktop application
Linux’s native working interface is the command line. Yes, KDE and GNOME are great graphic user interfaces. From a user’s perspective, clicking is much easier than typing; but this observation is relative. GUI is something that changed the perception of modern IT and computer usage. Some tasks are very difficult without a mouse, but not impossible.
On the other hand, command line is something where you can solve some tasks quicker, more efficiently, and better than in GUI. You don’t believe me? Imagine these situations and try to implement them through your favorite GUI tool:
- In a folder of 1000 files, copy only those the names of which start with A and end with Z, .txt extension
- Rename 100 files at the same time
- Redirect console output to the file
There are many such examples; in each of them, Command Prompt is superior—Linux Bash, even more.
Microsoft SQL Server is considered to be one the most commonly used systems for database management in the world. This popularity has been gained by high degree of stability, security, and business intelligence and integration functionality. Microsoft SQL Server for Linux is a database server that accepts queries from clients, evaluates them and then internally executes them, to deliver results to the client. The client is an application that produces queries, through a database provider and communication protocol sends requests to the server, and retrieves the result for client side processing and/or presentation.
(For more resources related to this topic, see here.)
Overview of SQL Server
When writing queries, it’s important to understand that the interaction between the tool of choice and the database based on client-server architecture, and the processes that are involved. It’s also important to understand which components are available and what functionality they provide.
With a broader understanding of the full product and its components and tools, you’ll be able to make better use of its functionality, and also benefit from using the right tool for specific jobs.
Client-server architecture concepts
In a client-server architecture, the client is described as a user and/or device, and the server as a provider of some kind of service.
 SQL Server client-server communication
SQL Server client-server communication
As you can see in the preceding figure, the client is represented as a machine, but in reality can be anything.
- Custom application (desktop, mobile, web)
- Administration tool (SQL Server Management Studio, dbForge, sqlcmd…)
- Development environment (Visual Studio, KDevelop…)
SQL Server Components
Microsoft SQL Server consists of many different components to serve a variety of organizational needs of their data platform. Some of these are:
- Database Engine is the relational database management system (RDBMS), which hosts databases and processes queries to return results of structured, semi-structured, and non-structured data in online transactional processing solutions (OLTP).
- Analysis Services is the online analytical processing engine (OLAP) as well as the data mining engine. OLAP is a way of building multi-dimensional data structures for fast and dynamic analysis of large amounts of data, allowing users to navigate hierarchies and dimensions to reach granular and aggregated results to achieve a comprehensive understanding of business values. Data mining is a set of tools used to predict and analyse trends in data behaviour and much more.
- Integration Services supports the need to extract data from sources, transform it, and load it in destinations (ETL) by providing a central platform that distributes and adjusts large amounts of data between heterogeneous data destinations.
- Reporting Services is a central platform for delivery of structured data reports and offers a standardized, universal data model for information workers to retrieve data and model reports without the need of understanding the underlying data structures.
- Data Quality Services (DQS) is used to perform a variety data cleaning, correction and data quality tasks, based on knowledge base. DQS is mostly used in ETL process before loading DW.
- R services (advanced analytics) is a new service that actually incorporate powerful R language for advanced statistic analytics. It is part of database engine and you can combine classic SQL code with R scripts.
While writing this book, only one service was actually available in SQL Server for Linux and its database engine. This will change in the future and you can expect more services to be available.
How it works on Linux?
SQL Server is a product with a 30-year-long history of development. We are speaking about millions of lines of code on a single operating system (Windows). The logical question is how Microsoft successfully ports those millions of lines of code to the Linux platform so fast. SQL Server@Linux, officially became public in the autumn of 2016. This process would take years of development and investment. Fortunately, it was not so hard.
From version 2005, SQL Server database engine has a platform layer called SQL Operating system (SOS). It is a setup between SQL Server engine and the Windows operating systems.
The main purpose of SOS is to minimize the number of system calls by letting SQL Server deal with its own resources. It greatly improves performance, stability and debugging process. On the other hand, it is platform dependent and does not provide an abstraction layer. That was the first big problem for even start thinking to make Linux version.
Project Drawbridge is a Microsoft research project created to minimize virtualization resources when a host runs many VM on the same physical machine. The technical explanation goes beyond the scope of this book (https://www.microsoft.com/en-us/research/project/drawbridge/). Drawbridge brings us to the solution of the problem.
Linux solution uses a hybrid approach, which combines SOS and Liberty OS from Drawbridge project to create SQL PAL (SQL Platform Abstraction Layer). This approach creates a set of SOS API calls which does not require Win32 or NT calls and separate them from platform depended code. This is a dramatically reduced process of rewriting SQL Server from its native environment to a Linux platform. This figure gives you a high-level overview of SQL PAL( https://blogs.technet.microsoft.com/dataplatforminsider/2016/12/16/sql-server-on-linux-how-introduction/).
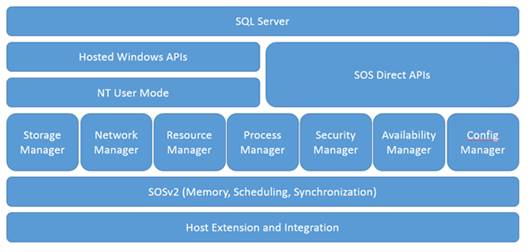 SQL PAL architecture
SQL PAL architecture
Retrieving and filtering data
Databases are one of the cornerstones of modern business companies. Data retrieval is usually made with SELECT statement and is therefore very important that you are familiar with this part of your journey. Retrieved data is often not organized in the way you want them to be, so they require additional formatting. Besides formatting, accessing very large amount of data requires you to take into account the speed and manner of query execution which can have a major impact on system performance
Databases usually consist of many tables where all data are stored. Table names clearly describe entities whose data are stored inside and therefore if you need to create a list of new products or a list of customers who had the most orders, you need to retrieve those data by creating a query. A query is an inquiry into the database by using the SELECT statement which is the first and most fundamental SQL statement that we are going to introduce in this chapter.
SELECT statement consists of a set of clauses that specifies which data will be included into query result set. All clauses of SQL statements are the keywords and because of that will be written in capital letters. Syntactically correct SELECT statement requires a mandatory FROM clause which specifies the source of the data you want to retrieve. Besides mandatory clauses, there are a few optional ones that can be used to filter and organize data:
- INTO enables you to insert data (retrieved by the SELECT clause) into a different table. It is mostly used to create table backup.
- WHERE places conditions on a query and eliminates rows that would be returned by a query without any conditions.
- ORDER BY displays the query result in either ascending or descending alphabetical order.
- GROUP BY provides mechanism for arranging identical data into groups.
- HAVING allows you to create selection criteria at the group level.
SQL Server recovery models
When it comes to the database, backup is something that you should consider and reconsider really carefully. Mistakes can cost you: money, users, data and time and I don’t know which one has bigger consequences. Backup and restore are elements of a much wider picture known by the name of disaster recovery and it is science itself. But, from the database perspective and usual administration task these two operations are the foundation for everything else.
Before you even think about your backups, you need to understand recovery models that SQL Server internally uses while the database is in operational mode. Recovery model is about maintaining data in the event of a server failure. Also, it defines amount of information that SQL Server writes in log file with purpose of recovery.
SQL Server has three database recovery models:
- Simple recovery model
- Full recovery model
- Bulk-logged recovery model
Simple recovery model
This model is typically used for small databases and scenarios were data changes are infrequent. It is limited to restoring the database to the point when the last backup was created. It means that all changes made after the backup are gone. You will need to recreate all changes manually. Major benefit of this model is that it takes small amount of storage space for log file. How to use it and when, depends on business scenarios.
Full recovery model
This model is recommended when recovery from damaged storage is the highest priority and data loss should be minimal. SQL Server uses copies of database and log files to restore database. Database engine logs all changes to the database including bulk operation and most DDL commands.
If the transaction log file is not damaged, SQL Server can recover all data except transaction which are in process at the time of failure (not committed in to database file). All logged transactions give you an opportunity of point in time recovery, which is a really cool feature.
Major limitation of this model is the large size of the log files which leads you to performance and storage issues. Use it only in scenarios where every insert is important and loss of data is not an option.
Bulk-logged recovery model
This model is somewhere in the middle of simple and full. It uses database and log backups to recreate database. Comparing to full recovery model, it uses less log space for: CREATE INDEX and bulk load operations such as SELECT INTO. Let’s look at this example. SELECT INTO can load a table with 1, 000, 000 records with a single statement. The log will only record occurrence of this operations but details. This approach uses less storage space comparing to full recovery model.
Bulk-logged recovery model is good for databases which are used to ETL process and data migrations.
SQL Server has system database model. This database is the template for each new one you create. If you use just CREATE DATABASE statement without any additional parameters it simply copies model database with all properties and metadata. It also inherits default recovery model which is full. So, conclusion is that each new database will be in full recovery mode. This can be changed during and after creation process.
Elements of backup strategy
Good backup strategy is not just about creating a backup. This is a process of many elements and conditions that should be filed to achieve final goal and this is the most efficient backup strategy plan. To create a good strategy, we need to answer the following questions:
- Who can create backups?
- Backup media
- Types of backups
Who can create backups?
Let’s say that SQL Server user needs to be a member of security role which is authorized to execute backup operations. They are members of:
- sysadmin server role
Every user with sysadmin permission can work with backups. Our default sa user is a member of the sysadmin role.
- db_owner database role
Every user who can create databases by default can execute any backup/restore operations.
- db_backupoperator database role
Some time you need just a person(s) to deal with every aspect of backup operation. This is common for large-scale organizations with tens or even hundreds of SQL Server instances. In those environments, backup is not trivial business.
Backup media
An important decision is where to story backup files and how to organize while backup files and devices. SQL Server gives you a large set of combinations to define your own backup media strategy. Before we explain how to store backups, let’s stop for a minute and describe the following terms:
- Backup disk is a hard disk or another storage device that contains backup files. Back file is just ordinary file on the top of file system.
- Media set is a collection of backup media in ordered way and fixed type (example: three type devices, Tape1, Tape2, and Tape3).
- Physical backup device can be a disk file of tape drive. You will need to provide information to SQL Server about your backup device. A backup file that is created before it is used for a backup operation is called a backup device.
 Figure Backup devices
Figure Backup devices
The simplest way to store and handle database backups is by using a back disk and storing them as regular operating system files, usually with the extension .bak. Linux does not care much about extension, but it is good practice to mark those files with something obvious.
This chapter will explain how to use backup disk devices because every reader of this book should have a hard disk with an installation of SQL Server on Linux; hope so! Tapes and media sets are used for large-scale database operations such as enterprise-class business (banks, government institutions and so on).
Disk backup devices can anything such as a simple hard disk drive, SSD disk, hot-swap disk, USB drive and so on. The size of the disk determines the maximum size of the database backup file.
It is recommended that you use a different disk as backup disk. Using this approach, you will separate database data and log disks.
Imagine this. Database files and backup are on the same device. If that device fails, your perfect backup strategy will fall like a tower of cards. Don’t do this. Always separate them. Some serious disaster recovery strategies (backup is only smart part of it) suggest using different geographic locations. This makes sense. A natural disaster or something else of that scale can knock down the business if you can’t restore your system from a secondary location in a reasonably small amount of time.
Summary
Backup and restore is not something that you can leave aside. It requires serious analyzing and planning, and SQL Server gives you powerful backup types and options to create your disaster recovery policy on SQL Server on Linux. Now you can do additional research and expand your knowledge
A database typically contains dozens of tables, and therefore it is extremely important that you master creating queries over multiple tables. This implies the knowledge of the functioning JOIN operators with a combination with elements of string manipulation.
Resources for Article:
Further resources on this subject:
- Review of SQL Server Features for Developers [article]
- Configuring a MySQL linked server on SQL Server 2008 [article]
- Exception Handling in MySQL for Python [article]