









Last week, a few researchers from the MIT CSAIL and Google AI published their research study of reconstructing a facial image of a person from a short audio recording of that person speaking, in their paper titled, “Speech2Face: Learning the Face Behind a Voice”.
The researchers designed and trained a neural network which uses millions of natural Internet/YouTube videos of people speaking. During training, they demonstrated that the model learns voice-face correlations that allows it to produce images that capture various physical attributes of the speakers such as age, gender, and ethnicity. The entire training was done in a self-supervised manner, by utilizing the natural co-occurrence of faces and speech in Internet videos, without the need to model attributes explicitly.
They said they further evaluated and numerically quantified how their Speech2Face reconstructs, obtains results directly from audio, and how it resembles the true face images of the speakers. For this, they tested their model both qualitatively and quantitatively on the AVSpeech dataset and the VoxCeleb dataset.
The Speech2Face model
The researchers utilized the VGG-Face model, a face recognition model pre-trained on a large-scale face dataset called DeepFace and extracted a 4096-D face feature from the penultimate layer (fc7) of the network. These face features were shown to contain enough information to reconstruct the corresponding face images while being robust to many of the aforementioned variations.
The Speech2Face pipeline consists of two main components:
1) a voice encoder, which takes a complex spectrogram of speech as input, and predicts a low-dimensional face feature that would correspond to the associated face; and
2) a face decoder, which takes as input the face feature and produces an image of the face in a canonical form (frontal-facing and with neutral expression).
During training, the face decoder is fixed, and only the voice encoder is trained which further predicts the face feature.
How were the facial features evaluated?
To quantify how well different facial attributes are being captured in Speech2Face reconstructions, the researchers tested different aspects of the model.
Demographic attributes
Researchers used Face++, a leading commercial service for computing facial attributes. They evaluated and compared age, gender, and ethnicity, by running the Face++ classifiers on the original images and our Speech2Face reconstructions.
The Face++ classifiers return either “male” or “female” for gender, a continuous number for age, and one of the four values, “Asian”, “black”, “India”, or “white”, for ethnicity.
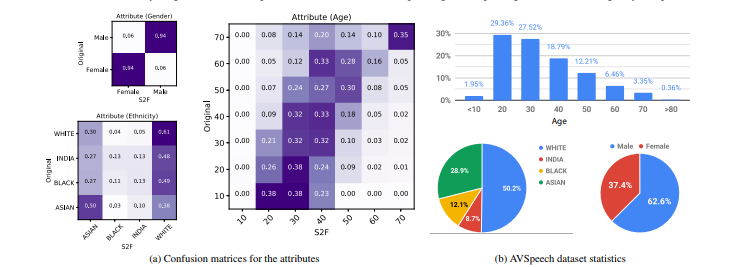
Source: Arxiv.org
Craniofacial attributes

Source: Arxiv.org
The researchers evaluated craniofacial measurements commonly used in the literature, for capturing ratios and distances in the face. They computed the correlation between F2F and the corresponding S2F reconstructions.
Face landmarks were computed using the DEST library. As can be seen, there is statistically significant (i.e., p < 0.001) positive correlation for several measurements. In particular, the highest correlation is measured for the nasal index (0.38) and nose width (0.35), the features indicative of nose structures that may affect a speaker’s voice.
Feature similarity
The researchers further test how well a person can be recognized from on the face features predicted from speech. They, first directly measured the cosine distance between the predicted features and the true ones obtained from the original face image of the speaker.
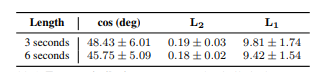
The table above shows the average error over 5,000 test images, for the predictions using 3s and 6s audio segments. The use of longer audio clips exhibits consistent improvement in all error metrics; this further evidences the qualitative improvement observed in the image below.

They further evaluated how accurately they could retrieve the true speaker from a database of face images. To do so, they took the speech of a person to predict the feature using the Speech2Face model and query it by computing its distances to the face features of all face images in the database.
Ethical considerations with Speech2Face model
Researchers said that the training data used is a collection of educational videos from YouTube and that it does not represent equally the entire world population. Hence, the model may be affected by the uneven distribution of data.
They have also highlighted that “ if a certain language does not appear in the training data, our reconstructions will not capture well the facial attributes that may be correlated with that language”.
“In our experimental section, we mention inferred demographic categories such as “White” and “Asian”. These are categories defined and used by a commercial face attribute classifier and were only used for evaluation in this paper. Our model is not supplied with and does not make use of this information at any stage”, the paper mentions.
They also warn that any further investigation or practical use of this technology would be carefully tested to ensure that the training data is representative of the intended user population. “If that is not the case, more representative data should be broadly collected”, the researchers state.
Limitations of the Speech2Face model
In order to test the stability of the Speech2Face reconstruction, the researchers used faces from different speech segments of the same person, taken from different parts within the same video, and from a different video. The reconstructed face images were consistent within and between the videos.

They further probed the model with an Asian male example speaking the same sentence in English and Chinese to qualitatively test the effect of language and accent. While having the same reconstructed face in both cases would be ideal, the model inferred different faces based on the spoken language.

In other examples, the model was able to successfully factor out the language, reconstructing a face with Asian features even though the girl was speaking in English with no apparent accent.
“In general, we observed mixed behaviors and a more thorough examination is needed to determine to which extent the model relies on language. More generally, the ability to capture the latent attributes from speech, such as age, gender, and ethnicity, depends on several factors such as accent, spoken language, or voice pitch. Clearly, in some cases, these vocal attributes would not match the person’s appearance”, the researchers state in the paper.
Speech2Cartoon: Converting generated image into cartoon faces
The face images reconstructed from speech may also be used for generating personalized cartoons of speakers from their voices. The researchers have used Gboard, the keyboard app available on Android phones, which is also capable of analyzing a selfie image to produce a cartoon-like version of the face.

Such cartoon re-rendering of the face may be useful as a visual representation of a person during a phone or a video conferencing call when the person’s identity is unknown or the person prefers not to share his/her picture. The reconstructed faces may also be used directly, to assign faces to machine-generated voices used in home devices and virtual assistants.
MIT CSAIL – I see what you are doing. This is uncool.
This paper and it's results, both needed more ethical consideration (https://t.co/bukc7lxMG1) than saying 'reveal statistical correlations'.
This is ethnic profiling, at scale
Paper Link: https://t.co/yn0hAdIkt9
— Nirant (@NirantK) May 27, 2019
A user on HackerNews commented, “This paper is a neat idea, and the results are interesting, but not in the way I’d expected. I had hoped it would the domain of how much person-specific information this can deduce from a voice, e.g. lip aperture, overbite, size of the vocal tract, openness of the nares. This is interesting from a speech perception standpoint. Instead, it’s interesting more in the domain of how much social information it can deduce from a voice. This appears to be a relatively efficient classifier for gender, race, and age, taking voice as input.”
“I’m sure this isn’t the first time it’s been done, but it’s pretty neat to see it in action, and it’s a worthwhile reminder: If a neural net is this good at inferring social, racial, and gender information from audio, humans are even better. And the idea of speech as a social construct becomes even more relevant”, he further added.
This recent study is interesting considering the fact that it is taking AI to another level wherein we are able to predict the face just by using audio recordings and even without the need for a DNA. However, there can be certain repercussions, especially when it comes to security. One can easily misuse such technology by impersonating someone else and can cause trouble. It would be interesting to see how this study turns out to be in the near future.
To more about the Speech2Face model in detail, head over to the research paper.
Read Next
OpenAI introduces MuseNet: A deep neural network for generating musical compositions