In this article by Nick Pentreath, author of the book Machine Learning with Spark, we will delve into a high-level overview of Spark's design, we will introduce the SparkContext object as well as the Spark shell, which we will use to interactively explore the basics of the Spark programming model.
(For more resources related to this topic, see here.)
SparkContext and SparkConf
The starting point of writing any Spark program is SparkContext (or JavaSparkContext in Java). SparkContext is initialized with an instance of a SparkConf object, which contains various Spark cluster-configuration settings (for example, the URL of the master node).
Once initialized, we will use the various methods found in the SparkContext object to create and manipulate distributed datasets and shared variables. The Spark shell (in both Scala and Python, which is unfortunately not supported in Java) takes care of this context initialization for us, but the following lines of code show an example of creating a context running in the local mode in Scala:
val conf = new SparkConf() .setAppName("Test Spark App") .setMaster("local[4]") val sc = new SparkContext(conf)
This creates a context running in the local mode with four threads, with the name of the application set to Test Spark App. If we wish to use default configuration values, we could also call the following simple constructor for our SparkContext object, which works in exactly the same way:
val sc = new SparkContext("local[4]", "Test Spark App")
The Spark shell
Spark supports writing programs interactively using either the Scala or Python REPL (that is, the Read-Eval-Print-Loop, or interactive shell). The shell provides instant feedback as we enter code, as this code is immediately evaluated. In the Scala shell, the return result and type is also displayed after a piece of code is run.
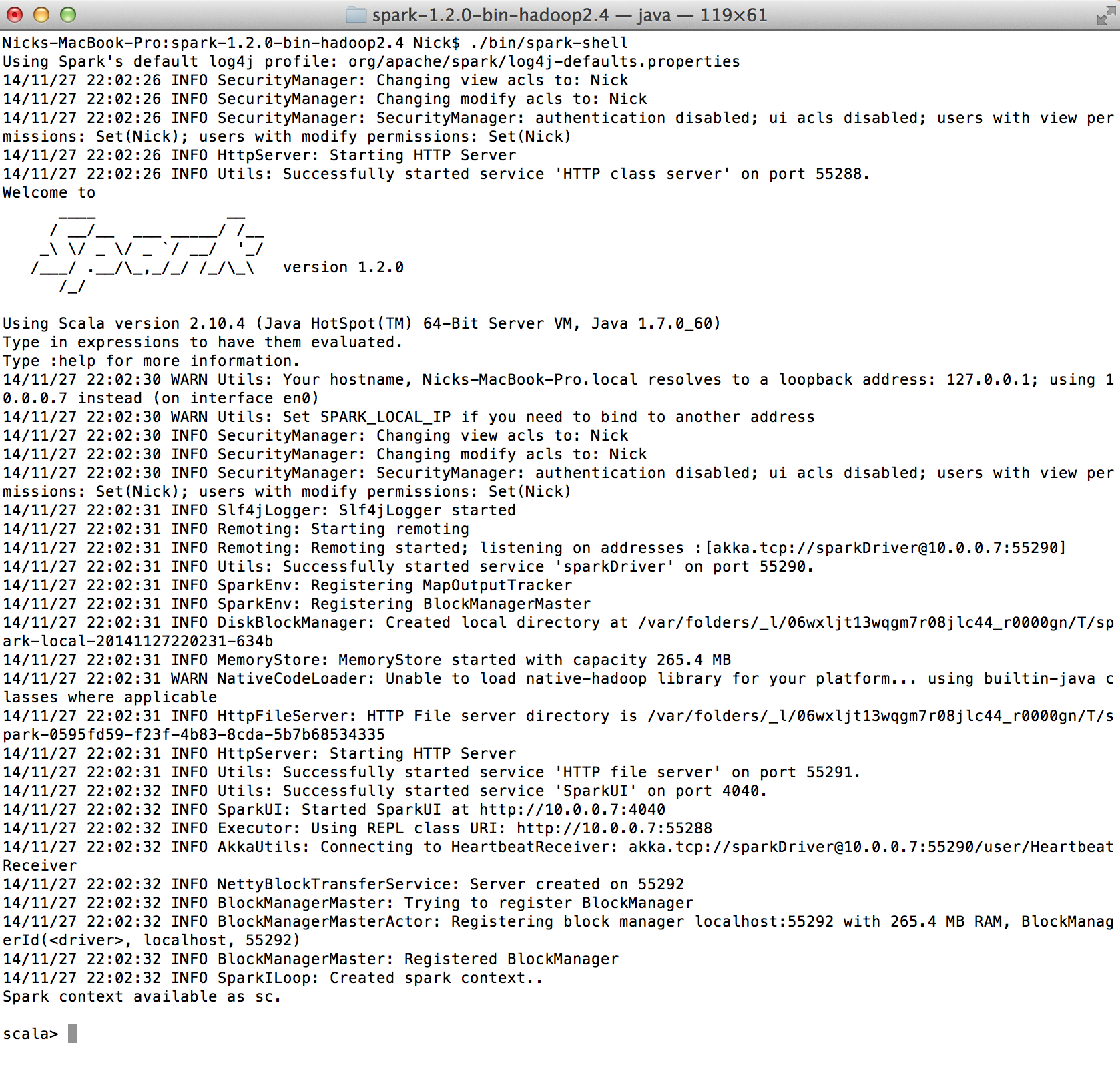
To use the Spark shell with Scala, simply run ./bin/spark-shell from the Spark base directory. This will launch the Scala shell and initialize SparkContext, which is available to us as the Scala value, sc. Your console output should look similar to the following screenshot:
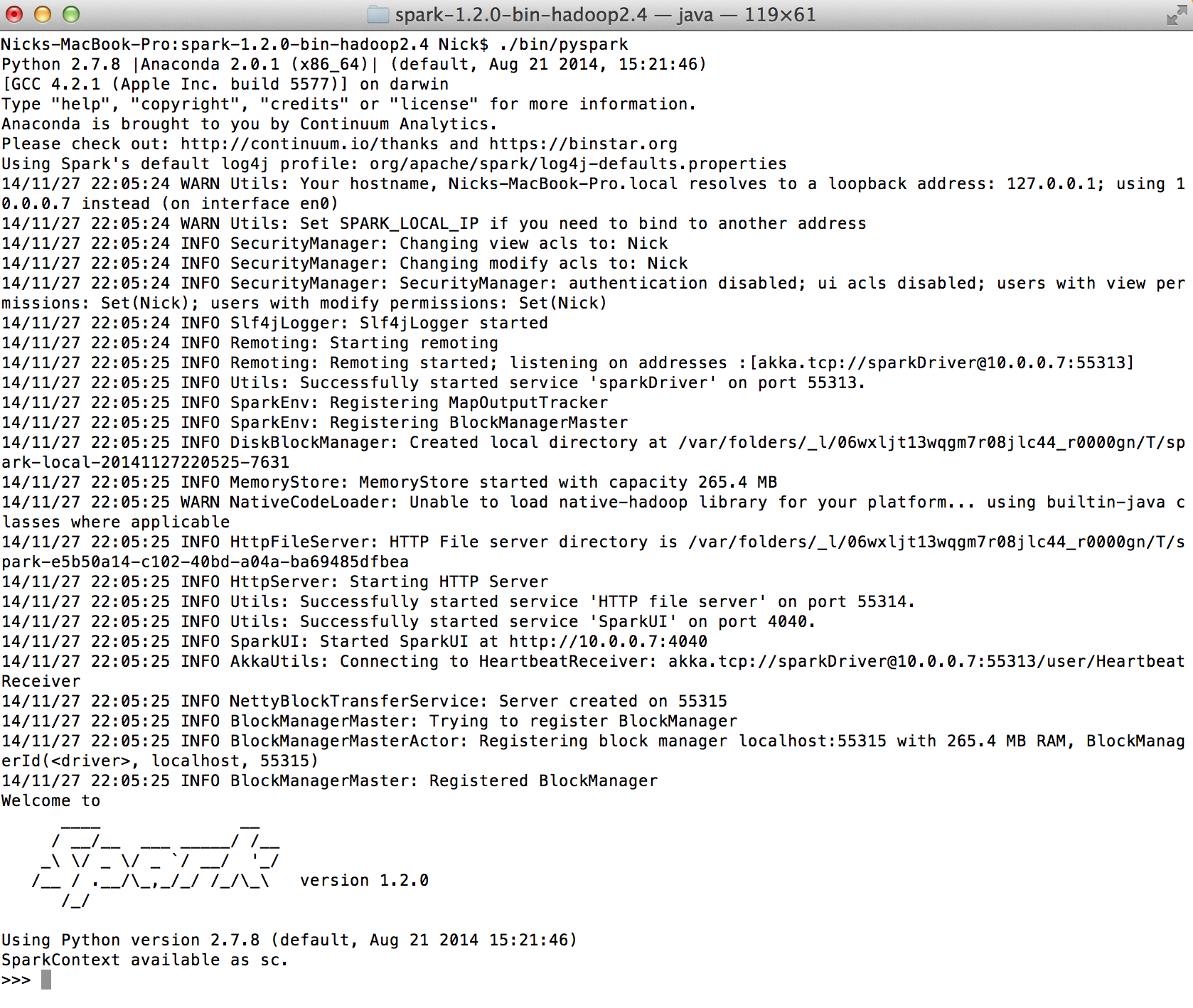
To use the Python shell with Spark, simply run the ./bin/pyspark command. Like the Scala shell, the Python SparkContext object should be available as the Python variable sc. You should see an output similar to the one shown in this screenshot:
Resilient Distributed Datasets
The core of Spark is a concept called the Resilient Distributed Dataset (RDD). An RDD is a collection of "records" (strictly speaking, objects of some type) that is distributed or partitioned across many nodes in a cluster (for the purposes of the Spark local mode, the single multithreaded process can be thought of in the same way). An RDD in Spark is fault-tolerant; this means that if a given node or task fails (for some reason other than erroneous user code, such as hardware failure, loss of communication, and so on), the RDD can be reconstructed automatically on the remaining nodes and the job will still complete.
Creating RDDs
RDDs can be created from existing collections, for example, in the Scala Spark shell that you launched earlier:
val collection = List("a", "b", "c", "d", "e") val rddFromCollection = sc.parallelize(collection)
RDDs can also be created from Hadoop-based input sources, including the local filesystem, HDFS, and Amazon S3. A Hadoop-based RDD can utilize any input format that implements the Hadoop InputFormat interface, including text files, other standard Hadoop formats, HBase, Cassandra, and many more. The following code is an example of creating an RDD from a text file located on the local filesystem:
val rddFromTextFile = sc.textFile("LICENSE")
The preceding textFile method returns an RDD where each record is a String object that represents one line of the text file.
Spark operations
Once we have created an RDD, we have a distributed collection of records that we can manipulate. In Spark's programming model, operations are split into transformations and actions. Generally speaking, a transformation operation applies some function to all the records in the dataset, changing the records in some way. An action typically runs some computation or aggregation operation and returns the result to the driver program where SparkContext is running.
Spark operations are functional in style. For programmers familiar with functional programming in Scala or Python, these operations should seem natural. For those without experience in functional programming, don't worry; the Spark API is relatively easy to learn.
One of the most common transformations that you will use in Spark programs is the map operator. This applies a function to each record of an RDD, thus mapping the input to some new output. For example, the following code fragment takes the RDD we created from a local text file and applies the size function to each record in the RDD. Remember that we created an RDD of Strings. Using map, we can transform each string to an integer, thus returning an RDD of Ints:
val intsFromStringsRDD = rddFromTextFile.map(line => line.size)
You should see output similar to the following line in your shell; this indicates the type of the RDD:
intsFromStringsRDD: org.apache.spark.rdd.RDD[Int] = MappedRDD[5] at map at <console>:14
In the preceding code, we saw the => syntax used. This is the Scala syntax for an anonymous function, which is a function that is not a named method (that is, one defined using the def keyword in Scala or Python, for example).
The line => line.size syntax means that we are applying a function where the input variable is to the left of the => operator, and the output is the result of the code to the right of the => operator. In this case, the input is line, and the output is the result of calling line.size. In Scala, this function that maps a string to an integer is expressed as String => Int. This syntax saves us from having to separately define functions every time we use methods such as map; this is useful when the function is simple and will only be used once, as in this example.
Now, we can apply a common action operation, count, to return the number of records in our RDD:
intsFromStringsRDD.count
The result should look something like the following console output:
14/01/29 23:28:28 INFO SparkContext: Starting job: count at <console>:17 ... 14/01/29 23:28:28 INFO SparkContext: Job finished: count at <console>:17, took 0.019227 s res4: Long = 398
Perhaps we want to find the average length of each line in this text file. We can first use the sum function to add up all the lengths of all the records and then divide the sum by the number of records:
val sumOfRecords = intsFromStringsRDD.sum val numRecords = intsFromStringsRDD.count val aveLengthOfRecord = sumOfRecords / numRecords
The result will be as follows:
aveLengthOfRecord: Double = 52.06030150753769
Spark operations, in most cases, return a new RDD, with the exception of most actions, which return the result of a computation (such as Long for count and Double for sum in the preceding example). This means that we can naturally chain together operations to make our program flow more concise and expressive. For example, the same result as the one in the preceding line of code can be achieved using the following code:
val aveLengthOfRecordChained = rddFromTextFile.map(line => line.size).sum / rddFromTextFile.count
An important point to note is that Spark transformations are lazy. That is, invoking a transformation on an RDD does not immediately trigger a computation. Instead, transformations are chained together and are effectively only computed when an action is called. This allows Spark to be more efficient by only returning results to the driver when necessary so that the majority of operations are performed in parallel on the cluster.
This means that if your Spark program never uses an action operation, it will never trigger an actual computation, and you will not get any results. For example, the following code will simply return a new RDD that represents the chain of transformations:
Unlock access to the largest independent learning library in Tech for FREE!
Get unlimited access to 7500+ expert-authored eBooks and video courses covering every tech area you can think of.
transformedRDD: org.apache.spark.rdd.RDD[Int] = MappedRDD[8] at map at <console>:14
Notice that no actual computation happens and no result is returned. If we now call an action, such as sum, on the resulting RDD, the computation will be triggered:
val computation = transformedRDD.sum
You will now see that a Spark job is run, and it results in the following console output:
... 14/11/27 21:48:21 INFO SparkContext: Job finished: sum at <console>:16, took 0.193513 s computation: Double = 60468.0
One of the most powerful features of Spark is the ability to cache data in memory across a cluster. This is achieved through use of the cache method on an RDD:
rddFromTextFile.cache
Calling cache on an RDD tells Spark that the RDD should be kept in memory. The first time an action is called on the RDD that initiates a computation, the data is read from its source and put into memory. Hence, the first time such an operation is called, the time it takes to run the task is partly dependent on the time it takes to read the data from the input source. However, when the data is accessed the next time (for example, in subsequent queries in analytics or iterations in a machine learning model), the data can be read directly from memory, thus avoiding expensive I/O operations and speeding up the computation, in many cases, by a significant factor.
If we now call the count or sum function on our cached RDD, we will see that the RDD is loaded into memory:
val aveLengthOfRecordChained = rddFromTextFile.map(line => line.size).sum / rddFromTextFile.count
Indeed, in the following output, we see that the dataset was cached in memory on the first call, taking up approximately 62 KB and leaving us with around 270 MB of memory free:
... 14/01/30 06:59:27 INFO MemoryStore: ensureFreeSpace(63454) called with curMem=32960, maxMem=311387750 14/01/30 06:59:27 INFO MemoryStore: Block rdd_2_0 stored as values to memory (estimated size 62.0 KB, free 296.9 MB) 14/01/30 06:59:27 INFO BlockManagerMasterActor$BlockManagerInfo: Added rdd_2_0 in memory on 10.0.0.3:55089 (size: 62.0 KB, free: 296.9 MB) ...
Now, we will call the same function again:
val aveLengthOfRecordChainedFromCached = rddFromTextFile.map(line => line.size).sum / rddFromTextFile.count
We will see from the console output that the cached data is read directly from memory:
... 14/01/30 06:59:34 INFO BlockManager: Found block rdd_2_0 locally ...
Another core feature of Spark is the ability to create two special types of variables: broadcast variables and accumulators.
A broadcast variable is a read-only variable that is made available from the driver program that runs the SparkContext object to the nodes that will execute the computation. This is very useful in applications that need to make the same data available to the worker nodes in an efficient manner, such as machine learning algorithms. Spark makes creating broadcast variables as simple as calling a method on SparkContext as follows:
val broadcastAList = sc.broadcast(List("a", "b", "c", "d", "e"))
The console output shows that the broadcast variable was stored in memory, taking up approximately 488 bytes, and it also shows that we still have 270 MB available to us:
14/01/30 07:13:32 INFO MemoryStore: ensureFreeSpace(488) called with curMem=96414, maxMem=311387750 14/01/30 07:13:32 INFO MemoryStore: Block broadcast_1 stored as values to memory (estimated size 488.0 B, free 296.9 MB) broadCastAList: org.apache.spark.broadcast.Broadcast[List[String]] = Broadcast(1)
A broadcast variable can be accessed from nodes other than the driver program that created it (that is, the worker nodes) by calling value on the variable:
This code creates a new RDD with three records from a collection (in this case, a Scala List) of ("1", "2", "3"). In the map function, it returns a new collection with the relevant record from our new RDD appended to the broadcastAList that is our broadcast variable.
Notice that we used the collect method in the preceding code. This is a Spark action that returns the entire RDD to the driver as a Scala (or Python or Java) collection.
We will often use collect when we wish to apply further processing to our results locally within the driver program.
Note that collect should generally only be used in cases where we really want to return the full result set to the driver and perform further processing. If we try to call collect on a very large dataset, we might run out of memory on the driver and crash our program. It is preferable to perform as much heavy-duty processing on our Spark cluster as possible, preventing the driver from becoming a bottleneck. In many cases, however, collecting results to the driver is necessary, such as during iterations in many machine learning models.
On inspecting the result, we will see that for each of the three records in our new RDD, we now have a record that is our original broadcasted List, with the new element appended to it (that is, there is now either "1", "2", or "3" at the end):
... 14/01/31 10:15:39 INFO SparkContext: Job finished: collect at <console>:15, took 0.025806 s res6: Array[List[Any]] = Array(List(a, b, c, d, e, 1), List(a, b, c, d, e, 2), List(a, b, c, d, e, 3))
An accumulator is also a variable that is broadcasted to the worker nodes. The key difference between a broadcast variable and an accumulator is that while the broadcast variable is read-only, the accumulator can be added to. There are limitations to this, that is, in particular, the addition must be an associative operation so that the global accumulated value can be correctly computed in parallel and returned to the driver program. Each worker node can only access and add to its own local accumulator value, and only the driver program can access the global value. Accumulators are also accessed within the Spark code using the value method.

 United States
United States
 Great Britain
Great Britain
 India
India
 Germany
Germany
 France
France
 Canada
Canada
 Russia
Russia
 Spain
Spain
 Brazil
Brazil
 Australia
Australia
 Singapore
Singapore
 Canary Islands
Canary Islands
 Hungary
Hungary
 Ukraine
Ukraine
 Luxembourg
Luxembourg
 Estonia
Estonia
 Lithuania
Lithuania
 South Korea
South Korea
 Turkey
Turkey
 Switzerland
Switzerland
 Colombia
Colombia
 Taiwan
Taiwan
 Chile
Chile
 Norway
Norway
 Ecuador
Ecuador
 Indonesia
Indonesia
 New Zealand
New Zealand
 Cyprus
Cyprus
 Denmark
Denmark
 Finland
Finland
 Poland
Poland
 Malta
Malta
 Czechia
Czechia
 Austria
Austria
 Sweden
Sweden
 Italy
Italy
 Egypt
Egypt
 Belgium
Belgium
 Portugal
Portugal
 Slovenia
Slovenia
 Ireland
Ireland
 Romania
Romania
 Greece
Greece
 Argentina
Argentina
 Netherlands
Netherlands
 Bulgaria
Bulgaria
 Latvia
Latvia
 South Africa
South Africa
 Malaysia
Malaysia
 Japan
Japan
 Slovakia
Slovakia
 Philippines
Philippines
 Mexico
Mexico
 Thailand
Thailand