A group of researchers, namely, Thu Nguyen-Phuoc, Chuan Li, Lucas Theis, Christian Richardt, and Yong-Liang Yang, published a paper titled ‘HoloGAN: Unsupervised learning of 3D representations from natural images, last week.
In the paper, researchers have proposed a generative adversarial network (GAN), called HoloGAN, for the task of unsupervised learning of 3D representations from natural images. HoloGAN works by adopting strong ‘inductive biases’ about the 3D world.
The paper states that commonly used generative models depend on 2D Kernels to produce images and make assumptions about the 3D world. This is why these models tend to create blurry images in tasks that require a strong 3D understanding. HoloGAN, however, learns a 3D representation of the world and is successful at rendering this representation in a realistic manner. It can be trained using unlabelled 2D images without requiring pose labels, 3D shapes, or multiple views of the same objects.
“Our experiments show that using explicit 3D features enables HoloGAN to disentangle 3D pose and identity, which is further decomposed into shape and appearance, while still being able to generate images with similar or higher visual quality than other generative models”, states the paper.
How does HoloGAN work?
HoloGAN first considers a 3D representation, which is later transformed to a target pose, projected to 2D features, and rendered to generate the final images. HoloGAN then learns perspective projection and rendering of 3D features from scratch with the help of a projection unit.
Finally, to generate new views of the same scene, 3D rigid-body transformations are applied to the known 3D features, and the results are visualized using a neural renderer. This produces sharper results than performing 3D transformations in high-dimensional latent vector space.
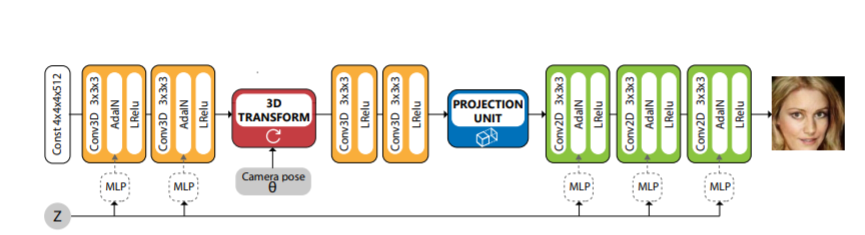
HoloGAN
To learn 3D representations from 2D images without labels, HoloGAN extends the capability of traditional unconditional GANs by introducing a strong inductive bias about the 3D world into the generator network.
During training, random poses from a uniform distribution are sampled and then the 3D features are transformed using these poses before they are rendered into images. Also, a variety of datasets are used to train HoloGAN, namely, Basel Face, CelebA, Cats, Chairs, Cars, and
LSUN bedroom. HoloGAN is trained on a resolution of 64×64 pixels for Cats and Chairs, and 128×128 pixels for Basel Face, CelebA, Cars and LSUN bedroom.
Other than that, HoloGAN generates 3D representations using a learned constant tensor. The random noise vector instead is treated as a “style” controller and gets mapped to affine parameters for adaptive instance normalization (AdaIN) using a multilayer perceptron.
Results and Conclusion
In the paper, researchers prove that HoloGAN can generate images with comparable or greater visual fidelity than other 2D-based GAN models. HoloGAN can also learn to disentangle challenging factors in an image, such as 3D pose, shape, and appearance. The paper also shows that HoloGAN can successfully learn meaningful 3D representations across different datasets with varying levels of complexity.
“We are convinced that explicit deep 3D representations are a crucial step forward for both the interpretability and controllability of GAN models, compared to existing explicit or implicit 3D representations”, reads the paper.
However, researchers state that while HoloGAN is successful at separating pose from identity, its performance largely depends on the variety and distribution of poses included in the training dataset. The paper cites an example of the CelebA and Cats dataset where the model cannot recover elevation as well as azimuth. This is due to the fact that most face images are taken at eye level, thereby, containing limited variation in elevation.
Unlock access to the largest independent learning library in Tech for FREE!
Get unlimited access to 7500+ expert-authored eBooks and video courses covering every tech area you can think of.
Renews at $19.99/month. Cancel anytime
Future work
The paper states that researchers would like to explore learning distribution of poses from the training data in an unsupervised manner for uneven pose distributions. Other directions that can be explored include further disentanglement of objects’, and appearances ( texture and illumination).
Researchers are also looking into combining the HoloGAN with training techniques suchas progressive GANs to produce higher-resolution images.
For more information, check out the official research paper.
DeepMind researchers provide theoretical analysis on recommender system, ‘echo chamber’ and ‘filter bubble effect’
Google AI researchers introduce PlaNet, an AI agent that can learn about the world using only images
Facebook researchers show random methods without any training can outperform modern sentence embeddings models for model classification

 United States
United States
 Great Britain
Great Britain
 India
India
 Germany
Germany
 France
France
 Canada
Canada
 Russia
Russia
 Spain
Spain
 Brazil
Brazil
 Australia
Australia
 Singapore
Singapore
 Canary Islands
Canary Islands
 Hungary
Hungary
 Ukraine
Ukraine
 Luxembourg
Luxembourg
 Estonia
Estonia
 Lithuania
Lithuania
 South Korea
South Korea
 Turkey
Turkey
 Switzerland
Switzerland
 Colombia
Colombia
 Taiwan
Taiwan
 Chile
Chile
 Norway
Norway
 Ecuador
Ecuador
 Indonesia
Indonesia
 New Zealand
New Zealand
 Cyprus
Cyprus
 Denmark
Denmark
 Finland
Finland
 Poland
Poland
 Malta
Malta
 Czechia
Czechia
 Austria
Austria
 Sweden
Sweden
 Italy
Italy
 Egypt
Egypt
 Belgium
Belgium
 Portugal
Portugal
 Slovenia
Slovenia
 Ireland
Ireland
 Romania
Romania
 Greece
Greece
 Argentina
Argentina
 Netherlands
Netherlands
 Bulgaria
Bulgaria
 Latvia
Latvia
 South Africa
South Africa
 Malaysia
Malaysia
 Japan
Japan
 Slovakia
Slovakia
 Philippines
Philippines
 Mexico
Mexico
 Thailand
Thailand














