









Apache Spark team has revealed a new venture during a keynote at Spark AI Summit called Project Hydrogen. This new project focuses on eliminating the obstacles faced by organizations from using Spark with various deep learning frameworks such as TensorFlow and MxNet.
The rise of Apache Spark is quite evident from the fact it is one of the highly accepted platforms for big data processing even outperforming other big data frameworks like Hadoop. It has shown a significant growth in the big data field. Due to its excellent functionalities and services, Apache Spark is one of the most used big data unified framework for carrying out data processing, SQL querying, real-time streaming analytics, and machine learning. If you want to understand why Apache Spark is gaining popularity, you can check out our interview with Romeo Kienzler, Chief Data Scientist in the IBM Watson IoT worldwide team.
What are the current limitations of Apache Spark?
Apache Spark works fine when you want to work in the big data field. However, the power of Spark’s single framework breaks down when one tries to use other third-party distributed machine learning or deep learning frameworks. Apache Spark has its own machine learning library called Spark MLlib, which provides noteworthy machine learning functionalities. However looking at the rate of development and research in the machine learning and artificial intelligence domain, data scientists and machine learning practitioners want to explore the power of leading deep learning frameworks such as TensorFlow, Keras, MxNet, Caffe2, and more.
The problem is, Apache Spark and deep learning frameworks don’t play well together. With growing requirement and advanced tasks, Spark users do want to combine Spark together with those frameworks in order to handle complex functionalities. However, the main problem is the incompatibility between the way how Spark scheduler works and other machine learning frameworks works.
Do we have any in-house solutions?
Basically, there are two possible options for combining Spark with other deep learning frameworks,
Option 1
We will need to use two different clusters to carry out individual work.
 Source: Databricks – Spark AI Summit 2018
Source: Databricks – Spark AI Summit 2018
As you can see in the preceding image, we have two clusters. All the data processing work which includes data prep, data cleansing and more can be performed in the Spark cluster, the final result is shared to a storage repository (HDFS or S3). The second cluster which is running the distributed machine learning framework can read the data stored in the repository,
This architecture no more follows a unified nature. One of the core challenges faced is handling these two disparate systems separately since you need to understand how each system work. Each cluster might follow different debugging schemes, different log files, thus making it very difficult to operate.
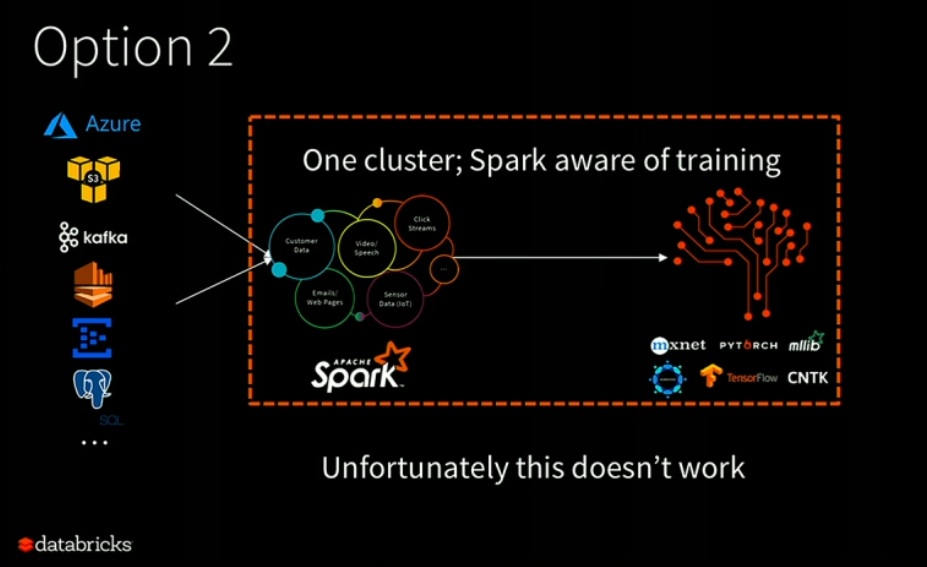
Option 2
Some users have tried to tackle all the challenges faced in option 1 such as operational difficulties, debugging, testing challenges and more by implementing option 2. As you can see in the following image, here we have one cluster that runs both Spark and distributed machine learning frameworks. However, the result is not so convincing.
The main problem with this approach is the inconsistency between how both systems work. There is a great difference between how Spark tasks are scheduled and how deep learning tasks are scheduled. In Spark environment, each job is divided into a number of subtasks that are independent of each other. However, deep learning frameworks use different scheduling schemes. Based on the job, they either use MPI or their own custom RPCs for doing communication. Here they assume complete coordination and dependency among their set of tasks.
Source: Databricks – Spark AI Summit 2018
You can see clear signs of this approach when the tasks fail. For example, as shown in the following figure, in the Spark model, when any task fails, the Spark scheduler simply restarts the single task, and thus the entire job is fully recovered. However, in case of deep learning frameworks, because of complete dependency if any of the tasks fails all the tasks need to be launched again.

Source: Databricks – Spark AI Summit 2018
The Solution: Project Hydrogen
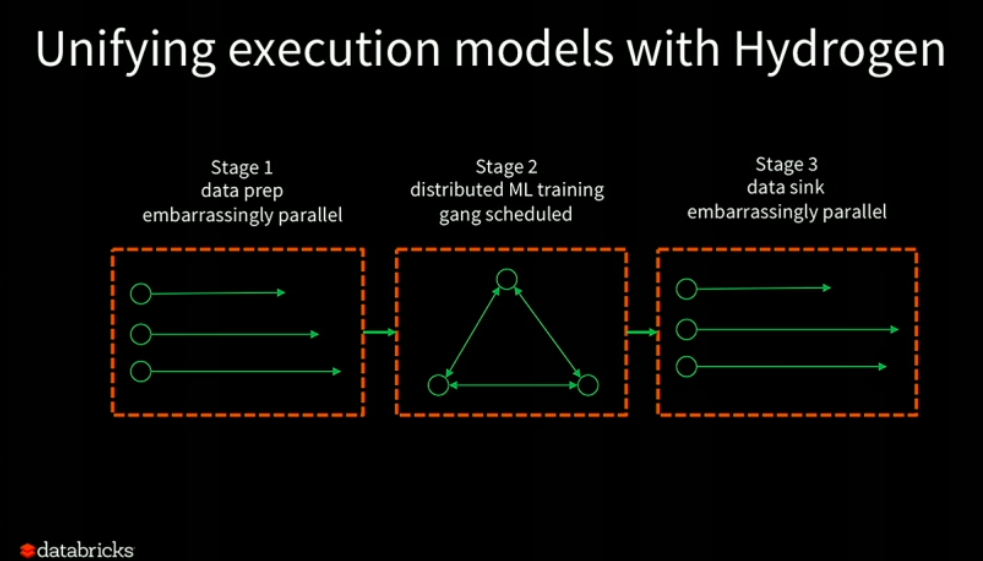
Project Hydrogen aims to solve all the challenges faced while using Spark and other deep learning frameworks together. It is positioned as a potential solution allowing all the data scientists to plug Spark with other deep learning frameworks. This project uses a new scheduling primitive called Gang scheduler. This primitive addresses the dependencies challenge introduced by the deep learning schedulers as shown in option 2.
Source: Databricks – Spark AI Summit 2018
In gang scheduling, it has to schedule all or nothing which means it schedule all the tasks in one go or none of the tasks are scheduled at all. This measure will successfully handle the disparity between how both systems work.
What’s next?
Project Hydrogen API is not ready yet. We can expect them to be added to the core Apache Spark project later this year. The primary goal of this project is to embrace all distributed machine learning frameworks in the Spark ecosystem. Thus allowing every other framework to run as smoothly as Apache Spark’s machine learning library MLlib.
Along with Spark support for deep learning frameworks, they are also working on speeding up the data exchanges, which often becomes a potential bottleneck while doing machine learning and deep learning tasks. In order to comfortably use FPGA or GPUs in your latest clusters, Spark is working closely with accelerators.