PHP Web 2.0 Mashup Projects: Your Own Video Jukebox: Part 2
Read more
PHP Web 2.0 Mashup Projects: Your Own Video Jukebox: Part 2
Packt
1140 min read
2010-02-19 00:00:00
0 Likes
0 Comments
Parsing With PEAR
If we were to start mashing up right now, between XSPF, YouTube's XML response, and RSS, we would have to create three different parsers to handle all three response formats. We would have to comb through the documentation and create flexible parsers for all three formats. If the XML response for any of these formats changes, we would also be responsible for changing our parser code. This isn't a difficult task, but we should be aware that someone else has already done the work for us. Someone else has already dissected the XML code. To save time, we can leverage this work for our mashup.
We used PEAR, earlier in Chapter 1 to help with XML-RPC parsing. For this project, we will once again use PEAR to save us the trouble of writing parsers for the three XML formats we will encounter.
For this project, we will take a look at three packages for our mashup. File_XSPF is a package for extracting and setting up XSPF playlists. Services_YouTube is a Web Services package that was created specifically for handling the YouTube API for us. Finally, XML_RSS is a package for working with RSS feeds.
For this project, it works out well that there are three specific packages that fits our XML and RSS formats. If you need to work with an XML format that does not have a specific PEAR package, you can use the XML_Unserializer package. This package will take a XML and return it as a string.
Is PEAR Right For You? Before we start installing PEAR packages, we should take a look if it is even feasible to use them for a project. PEAR packages are installed with a command line package manager that is included with every core installation of PHP. In order for you to install PEAR packages, you need to have administrative access to the server. If you are in a shared hosting environment and your hosting company is stingy, or if you are in a strict corporate environment where getting a server change is more hassle than it is worth, PEAR installation may not be allowed. You could get around this by downloading the PEAR files and installing them in your web documents directory. However, you will then have to manage package dependencies and package updates by yourself. This hassle may be more trouble than it's worth, and you may be better off writing your own code to handle the functionality. On the other hand, PEAR packages are often a great time saver. The purpose of the packages is to either simplify tedious tasks, or interface with complex systems. The PEAR developer has done the difficult work for you already. Moreover, as they are written in PHP and not C, like a PHP extension would be, a competent PHP developer should be able to read the code for documentation if it is lacking. Finally, one key benefit of many packages, including the ones we will be looking at, is that they are object-oriented representations of whatever they are interfacing. Values can be extracted by simply calling an object's properties, and complex connections can be ignited by a simple function call. This helps keep our code cleaner and modular. Whether the benefits of PEAR outweigh the potential obstacles depends on your specific situation.
Package Installation and Usage
Just like when we installed the XML-RPC package, we will use the install binary to install our three packages. If you recall, installing a package, simply type install into the command line followed by the name of the package. In this case, though, we need to set a few more flags to force the installer to grab dependencies and code in beta status.
To install File_XSPF, switch to the root user of the machine and use this command:
This command will download the package. The -alldeps flag tells PEAR to also check for required dependencies and install them if necessary. The progress and outcome of the downloads will be reported.
Usually, you will not need the –f flag. By default, PEAR downloads the latest stable release of a package. The –f flag, force, forces PEAR to download the most current version, regardless of its release state. As of this writing, File_XSPF and Services_YouTube do not have stable releases, only beta and alpha respectively. Therefore, we must use –f to grab and install this package. Otherwise, PEAR will complain that the latest version is not available. If the package you want to download is in release state, you will not need the –f flag.
This is the case of XML_RSS, which has a stable version available.
After this, sending a list-all command to PEAR will show the three new packages along with the packages you had before.
PEAR packages are basically self-contained PHP files that PEAR installs into your PHP includes directory. The includes directory is a directive in your php.ini file. Navigate to this directory to see the PEAR packages' source files. To use a PEAR package, you will need to include the package's source file in the top of your code. Consult the package's documentation on how to include the main package file. For example, File_XSPF is activated by including a file named XSPF.php. PEAR places XSPF.php in a directory named File, and that directory is inside your includes directory.
<?php require_once 'File/XSPF.php'; //File_XSPF is now available.
The package is simple to use. The heart of the package is an object called XSPF. You instantiate and use this object to interact with a playlist. It has methods to retrieve and modify values from a playlist, as well as utility methods to load a playlist into memory, write a playlist from memory to a file, and convert an XSPF file to other formats.
Getting information from a playlist consists of two straightforward steps. First, the location of the XSPF file is passed to the XSPF object's parse method. This loads the file into memory. After the file is loaded, you can use the object's various getter methods to extract values from the list. Most of the XSPF getter methods are related to getting metadata about the playlist itself. To get information about the tracks in the playlist, use the getTracks method. This method will return an array of XSPF_Track objects. Each track in the playlist is represented as an XSPF_Track object in this array. You can then use the XSPF_Track object's methods to grab information about the individual tracks.
We can grab a playlist from Last.fm to illustrate how this works. The web service has a playlist of a member's most played songs. Named Top Tracks, the playlist is located at http://ws.audioscrobbler.com/1.0/user/USERNAME/toptracks.xspf, where USERNAME is the name of the Last.fm user that you want to query.
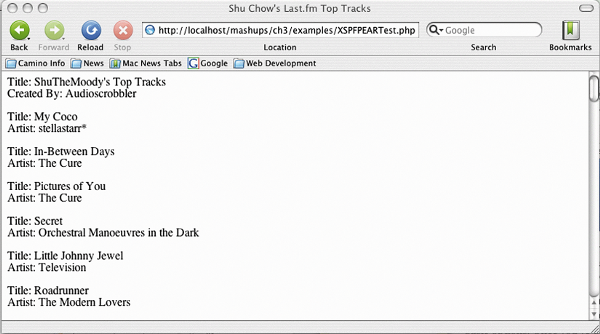
This page is named XSPFPEARTest.php in the examples. It uses File_XSPF to display my top tracks playlist from Last.fm.
<?php require_once 'File/XSPF.php'; $xspfObj =& new File_XSPF(); //Load the playlist into the XSPF object. $xspfObj->parseFile('http://ws.audioscrobbler.com/1.0/user/ ShuTheMoody/toptracks.xspf'); //Get all tracks in the playlist. $tracks = $xspfObj->getTracks(); ?>
This first section creates the XSPF object and loads the playlist. First, we bring in the File_XSPF package into the script. Then, we instantiate the object. The parseFile method is used to load an XSPF file list across a network. This ties the playlist to the XSPF object. We then use the getTracks method to transform the songs on the playlist into XSPF_Track objects.
<html> <head> <title>Shu Chow's Last.fm Top Tracks</title> </head> <body> Title: <?= $xspfObj->getTitle() ?><br /> Created By: <?= $xspfObj->getCreator() ?>
Next, we prepare to display the playlist. Before we do that, we extract some information about the playlist. The XSPF object's getTitle method returns the XSPF file's title element. getCreator returns the creator element of the file.
Finally, we loop through the tracks array. We assign the array's elements, which are XSPF_Track objects, into the $track variable. XSPF_Track also has getTitle and getCreator methods. Unlike XSPF's methods of the same names, getTitle returns the title of the track, and getCreator returns the track's artist.
Running this file in your web browser will return a list populated with data from Last.fm.
Services_YouTube
Services_YouTube works in a manner very similar to File_XSPF. Like File_XSPF, it is an object-oriented abstraction layer on top of a more complicated system. In this case, the system is the YouTube API.
Many of the methods deal with getting members' information like their profile and videos they've uploaded. A smaller, but very important subset is used to query YouTube for videos. We will use this subset in our mashup. To get a list of videos that have been tagged with a specific tag, use the object's listByTag method.
listByTag will query the YouTube service and store the XML response in memory. It is does not return an array of video objects we can directly manage, but with one additional function call, we can achieve this. From there, we can loop through an array of videos similar to what we did for XSPF tracks.
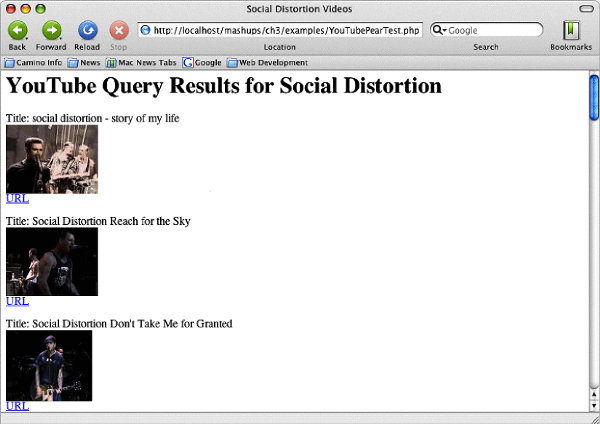
The example file YouTubePearTest.php illustrates this process.
First, we load the Services_YouTube file into our script. As YouTube's web service requires a Developer ID, we store that information into a local variable. After that, we place the tag we want to search for in another local variable named $tag. In this example, we are going to check out which videos YouTube has for the one of the greatest bands of all time, Social Distortion. Service_YouTube's constructor takes this Developer ID and uses it whenever it queries the YouTube web service. The constructor can take an array of options as a parameter. One of the options is to use a local cache of the queries. It is considered good practice to use a cache, as to not slam the YouTube server and run up your requests quota.
Another option is to specify either REST or XML-RPC as the protocol via the driver key in the options array. By default, Services_YouTube uses REST. Unless you have a burning requirement to use XML-RPC, you can leave it as is.
Once instantiated, you can call listByTag to get the response from YouTube. listByTag takes only one parameter—the tag of our desire.
Services_YouTube now has the results from YouTube. We can begin the display of the results.
Unlock access to the largest independent learning library in Tech for FREE!
Get unlimited access to 7500+ expert-authored eBooks and video courses covering every tech area you can think of.
Renews at $19.99/month. Cancel anytime
<html> <head> <title>Social Distortion Videos</title> </head> <body> <h1>YouTube Query Results for Social Distortion</h1>
Next, we will loop through the videos. In order to get an array of video objects, we first need to parse the XML response. We do that using Services_YouTube's xpath method, which will use the powerful XPATH query language to go through the XML and convert it into PHP objects. We pass the XPATH query into the method, which will give us an array of useful objects. We will take a closer look at XPATH and XPATH queries later in another project. For now, trust that the query //video will return an array of video objects that we can examine.
Within the loop, we display each video's title, a thumbnail image of the video, and a hyperlink to the video itself.
Running this query in our web browser will give us a results page of videos that match the search term we submitted.
XML_RSS
Like the other PEAR extensions, XML_RSS changes something very complex, RSS, into something very simple and easy to use, PHP objects. The complete documentation for this package is at http://pear.php.net/package/XML_RSS/docs/XML_RSS.
There is a small difference to the basic philosophy of XML_RSS compared to Services_YouTube and File_XSPF. The latter two packages take information from whatever we're interested in, and place them into PHP object properties.
For example, File_XSPF takes track names into a Track object, and you use a getTitle() getter method to get the title of the track. In Services_YouTube, it's the same principle, but the properties are public, and so there are no getter methods. You access the video's properties directly in the video object.
In XML_RSS, the values we're interested in are stored in associative arrays. The available methods in this package get the arrays, then you manipulate them directly. It's a small difference, but you should be aware of it in case you want to look at the code. It also means that you will have to check the documentation of the package to see which array keys are available to you.
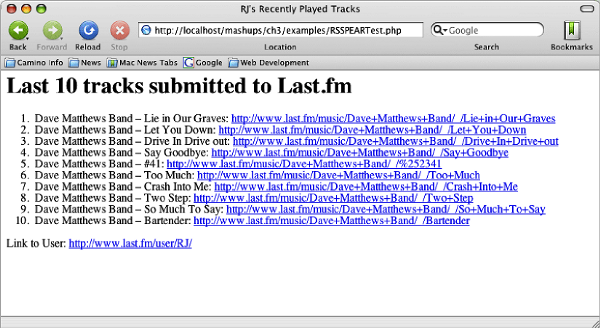
Let's take a look at how this works in an example. The file is named RSSPEARTest.php in the example code. One of Audioscrobbler's feeds gives us an RSS file of songs that a user recently played. The feed isn't always populated because after a few hours, songs that are played aren't considered recent. In other words, songs will eventually drop off the feed simply because they are too old. Therefore, it's best to use this feed on a heavy user of Last.fm.
RJ is a good example to use. He seems to always be listening to something. We'll grab his feed from Audioscrobbler:
<?php include ("XML/RSS.php"); $rss =& new XML_RSS("http://ws.audioscrobbler.com/1.0/user/RJ/ recenttracks.rss"); $rss->parse();
We start off by including the module and creating an XML_RSS object. XML_RSS is where all of the array get methods reside, and is the heart of this package. It's constructor method takes one variable—the path to the RSS file. At instantiation, the package loads the RSS file into memory.
parse() is the method that actually does the RSS parsing. After this, the get methods will return data about the feed. Needless to say, parse() must be called before you do anything constructive with the file.
$channelInfo = $rss->getChannelInfo(); ?>
The package's getChannelInfo() method returns an array that holds information about the metadata, the channel, of the file. This array holds the title, description, and link elements of the RSS file. Each of these elements is stored in the array with the same key name as the element.
<?= "<?xml version="1.0" encoding="UTF-8" ?>" ?>
The data that comes back will be UTF-8 encoded. Therefore, we need to force the page into UTF-8 encoding mode. This line outputs the XML declaration into the top of the web page in order to insure proper rendering. Putting a regular <?xml declaration will trigger the PHP engine to parse the declaration. However, PHP will not recognize the code and halt the page with an error.
Here we begin the actual output of the page. We start by using the array returned from getChannelInfo() to output the title and description elements of the feed.
Next, we start outputting the items in the RSS file. We use getItems() to grab information about the items in the RSS. The return is an array that we loop through with a foreach statement. Here, we are extracting the item's title and link elements. We show the title, and then create a hyperlink to the song's page on Last.fm. The description and pubDate elements in the RSS are also available to us in getItems's returned array.
Link to User: <a href="<?= $channelInfo['link'] ?>"><?= $channelInfo['link'] ?></a> </body> </html>
Finally, we use the channel's link property to create a hyperlink to the user's Last.fm page before we close off the page's body and html tags.
Using More Elements In this example, the available elements in the channel and item arrays are a bit limited. getChannelInfo() returns an array that only has the title, description, and link properties. The array from getItems() only has title, description, link, and pubDate properties. This is because we are using the latest release version of XML_RSS. At the time of writing this book, it is version 0.9.2. The later versions of XML_RSS, currently in beta, handle many more elements. Elements in RSS 2.0 like category and authors are available. To upgrade to a beta version of XML_RSS, use the command PEAR upgrade –f XML_RSS in the command line. The –f flag is the same flag we used to force the beta and alpha installations of Service_YouTube and File_XSPF. Alternatively, you can install the beta version of XML_RSS at the beginning using the same –f flag.
If we run this page on our web browser, we can see the successful results of our hit.
At this point, we know how to use the Audioscrobbler feeds to get information. The majority of the feeds are either XSPF or RSS format. We know generally how the YouTube API works. Most importantly, we know how to use the respective PEAR packages to extract information from each web service. It's time to start coding our application.
Mashing Up
If you haven't already, you should, at the very least, create a YouTube account and sign up for a developer key. You should also create a Last.fm account, install the client software, and start listening to some music on your computer. This will personalize the video jukebox to your music tastes. All examples here will assume that you are using your own YouTube key. I will use my own Last.fm account for the examples. As the feeds are open and free, you can use the same feeds if you choose not to create a Last.fm account.
Mashup Architecture
There are obviously many ways in which we can set up our application. However, we're going to keep functionality fairly simple.
The interface will be a framed web page. The top pane is the navigation pane. It will be for the song selection. The bottom section is the content pane and will display and play the video.
In the navigation pane, we will create a select menu with all of our songs. The value, and label, for each option will be the artist name followed by a dash, followed by the name of the song (For example, "April Smith—Bright White Jackets"). Providing both pieces of information will help YouTube narrow down the selection.
When the user selects a song and pushes a "Go" button, the application will load the content page into the content pane. This form will pass the artist and song information to the content page via a GET parameter. The content page will use this GET parameter to query YouTube. The page will pull up the first, most relevant result from its list of videos and display it.
Main Page
The main page is named jukebox.html in the example code. This is our frameset page. It will be quite simple. All it will do is define the frameset that we will use.
This code defines our page. It is two frame rows. The navigation section, named Navigation, is 10% of the height, and the content, named Content, is the remaining 90%. When first loaded, the mashup will load the list of songs in the navigation page and nothing else.

 United States
United States
 Great Britain
Great Britain
 India
India
 Germany
Germany
 France
France
 Canada
Canada
 Russia
Russia
 Spain
Spain
 Brazil
Brazil
 Australia
Australia
 Singapore
Singapore
 Canary Islands
Canary Islands
 Hungary
Hungary
 Ukraine
Ukraine
 Luxembourg
Luxembourg
 Estonia
Estonia
 Lithuania
Lithuania
 South Korea
South Korea
 Turkey
Turkey
 Switzerland
Switzerland
 Colombia
Colombia
 Taiwan
Taiwan
 Chile
Chile
 Norway
Norway
 Ecuador
Ecuador
 Indonesia
Indonesia
 New Zealand
New Zealand
 Cyprus
Cyprus
 Denmark
Denmark
 Finland
Finland
 Poland
Poland
 Malta
Malta
 Czechia
Czechia
 Austria
Austria
 Sweden
Sweden
 Italy
Italy
 Egypt
Egypt
 Belgium
Belgium
 Portugal
Portugal
 Slovenia
Slovenia
 Ireland
Ireland
 Romania
Romania
 Greece
Greece
 Argentina
Argentina
 Netherlands
Netherlands
 Bulgaria
Bulgaria
 Latvia
Latvia
 South Africa
South Africa
 Malaysia
Malaysia
 Japan
Japan
 Slovakia
Slovakia
 Philippines
Philippines
 Mexico
Mexico
 Thailand
Thailand