









Sentiment analysis is achieved by labeling individual words as positive or negative, among other possible sentiments such as happy, worried, and so on. The sentiment of the sentence or phrase as a whole is determined by a procedure that aggregates the sentiment of individual words.
In this article we’ll demonstrate how to perform sentiment analysis on social media platforms using the CoreNLP library. This article is taken from the book AI Blueprints written by Dr Joshua Eckroth.The book covers several paradigms of AI, including deep learning, natural language processing, planning, and logic programming.
Consider the sentence, I didn’t like a single minute of this film. A simplistic sentiment analysis system would probably label the word like as positive and the other words as neutral, yielding an overall positive sentiment. More advanced systems analyze the “dependency tree” of the sentence to identify which words are modifiers for other words. In this case, didn’t is a modifier for like, so the sentiment of like is reversed due to this modifier. Likewise, a phrase such as It’s definitely not dull, exhibits a similar property, and …not only good but amazing exhibits a further nuance of the English language.
It is clear a simple dictionary of positive and negative words is insufficient for accurate sentiment analysis. The presence of modifiers can change the polarity of a word. Wilson and others’ work on sentiment analysis (Recognizing contextual polarity in phrase-level sentiment analysis, Wilson, Theresa, Janyce Wiebe, and Paul Hoffmann, published in Proceedings of the conference on human language technology and empirical methods in natural language processing, pp. 347-354, 2005) is foundational in the dependency tree approach. They start with a lexicon (that is, collection) of 8,000 words that serve as “subjectivity clues” and are tagged with polarity (positive or negative).
Using just this dictionary, they achieved 48% accuracy in identifying the sentiment of about 3,700 phrases. To improve on this, they adopted a two-step approach. First, they used a statistical model to determine whether a subjectivity clue is used in a neutral or polar context. When used in a neutral context, the word can be ignored as it does not contribute to the overall sentiment. The statistical model for determining whether a word is used in a neutral or polar context uses 28 features, including the nearby words, binary features such as whether the word not appears immediately before, and part-of-speech information such as whether the word is a noun, verb, adjective, and so on.
Next, words that have polarity, that is, those that have not been filtered out by the neutral/polar context identifier, are fed into another statistical model that determines their polarity: positive, negative, both, or neutral. Ten features are used for polarity classification, including the word itself and its polarity from the lexicon, whether or not the word is being negated, and the presence of certain nearby modifiers such as little, lack, and abate. These modifiers themselves have polarity: neutral, negative, and positive, respectively. Their final procedure achieves 65.7% percent accuracy for detecting sentiment. Their approach is implemented in the open source OpinionFinder.
Sentiment analysis using Natural Language Processing
A more modern approach may be found in Stanford’s open source CoreNLP project . CoreNLP supports a wide range of NLP processing such as sentence detection, word detection, part-of-speech tagging, named-entity recognition (finding names of people, places, dates, and so on), and sentiment analysis. Several NLP features, such as sentiment analysis, depend on prior processing including sentence detection, word detection, and part-of-speech tagging. As described in the following text, a sentence’s dependency tree, which shows the subject, object, verbs, adjectives, and prepositions of a sentence, is critical for sentiment analysis. CoreNLP’s sentiment analysis technique has been shown to achieve 85.4% accuracy for detecting positive/negative sentiment of sentences. Their technique is state-of-the-art and has been specifically designed to better handle negation in various places in a sentence, a limitation of simpler sentiment analysis techniques as previously described.
CoreNLP’s sentiment analysis uses a technique known as recursive neural tensor networks (RNTN) (Here, a sentence or phrase is parsed into a binary tree, as seen in Figure 1. Every node is labeled with its part-of-speech: NP (noun phrase), VP (verb phrase), NN (noun), JJ (adjective), and so on. Each leaf node, that is, each word node, has a corresponding word vector. A word vector is an array of about 30 numbers (the actual size depends on a parameter that is determined experimentally). The values of the word vector for each word are learned during training, as is the sentiment of each individual word. Just having word vectors will not be enough since we have already seen how sentiment cannot be accurately determined by looking at words independently of their context.
The next step in the RNTN procedure collapses the tree, one node at a time, by calculating a vector for each node based on its children. The bottom-right node of the figure, the NP node with children own and crashes, will have a vector that is the same size of the word vectors but is computed based on those child word vectors. The computation multiplies each child word vector and sums the results. The exact multipliers to use are learned during training. The RNTN approach, unlike prior but similar tree collapsing techniques, uses a single combiner function for all nodes. Ultimately, the combiner function and the word vectors are learned simultaneously using thousands of example sentences with the known sentiment.
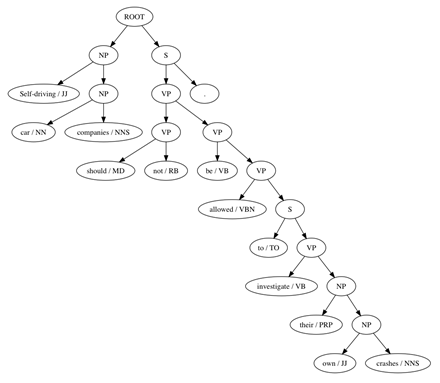
Figure 1: CoreNLP’s dependency tree parse of the sentence, “Self-driving car companies should not be allowed to investigate their own crashes”
The dependency tree from the preceding figure has twelve leaf nodes and twelve combiner nodes. Each leaf node has an associated word vector learned during training. The sentiment of each leaf node is also learned during training. Thus, the word crashes, for example, has a neutral sentiment with 0.631 confidence, while the word not has negative sentiment with 0.974 confidence. The parent node of allowed and the phrase to investigate their own crashes has a negative sentiment, confidence 0.614, even though no word or combiner node among its descendants have anything but neutral sentiment. This demonstrates that the RNTN learned a complex combiner function that operates on the word vectors of its children and not just a simple rule such as, If both children are neutral, then this node is neutral, or if one child is neutral, but one is positive, this node is positive, ….
The sentiment values and confidence of each node in the tree is shown in the output of CoreNLP shown in the following code block. Note that sentiment values are coded:
- 0 = very negative
- 1 = negative
- 2 = neutral
- 3 = positive
- 4 = very positive
(ROOT|sentiment=1|prob=0.606
(NP|sentiment=2|prob=0.484
(JJ|sentiment=2|prob=0.631 Self-driving)
(NP|sentiment=2|prob=0.511
(NN|sentiment=2|prob=0.994 car)
(NNS|sentiment=2|prob=0.631 companies)))
(S|sentiment=1|prob=0.577
(VP|sentiment=2|prob=0.457
(VP|sentiment=2|prob=0.587
(MD|sentiment=2|prob=0.998 should)
(RB|sentiment=1|prob=0.974 not))
(VP|sentiment=1|prob=0.703
(VB|sentiment=2|prob=0.994 be)
(VP|sentiment=1|prob=0.614
(VBN|sentiment=2|prob=0.969 allowed)
(S|sentiment=2|prob=0.724
(TO|sentiment=2|prob=0.990 to)
(VP|sentiment=2|prob=0.557
(VB|sentiment=2|prob=0.887 investigate)
(NP|sentiment=2|prob=0.823
(PRP|sentiment=2|prob=0.997 their)
(NP|sentiment=2|prob=0.873
(JJ|sentiment=2|prob=0.996 own)
(NNS|sentiment=2|prob=0.631 crashes))))))))
(.|sentiment=2|prob=0.997 .)))We see from these sentiment values that allowed to investigate their own crashes is labeled with negative sentiment. We can investigate how CoreNLP handles words such as allowed and not by running through a few variations. These are shown in the following table:
| Sentence | Sentiment | Confidence |
| They investigate their own crashes. | Neutral | 0.506 |
| They are allowed to investigate their own crashes. | Negative | 0.697 |
| They are not allowed to investigate their own crashes. | Negative | 0.672 |
| They are happy to investigate their own crashes. | Positive | 0.717 |
| They are not happy to investigate their own crashes. | Negative | 0.586 |
| They are willing to investigate their own crashes. | Neutral | 0.507 |
| They are not willing to investigate their own crashes. | Negative | 0.599 |
| They are unwilling to investigate their own crashes. | Negative | 0.486 |
| They are not unwilling to investigate their own crashes. | Negative | 0.625 |
Table 1: Variations of a sentence with CoreNLP’s sentiment analysis
It is clear from Table 1 that the phrase investigates their own crashes is not contributing strongly to the sentiment of the whole sentence. The verb, allowed, happy, or willing can dramatically change the sentiment. The modifier not can flip the sentiment, though curiously not unwilling is still considered negative.
We should be particularly careful to study CoreNLP’s sentiment analysis with sentence fragments and other kinds of invalid English that is commonly seen on Twitter. For example, the Twitter API will deliver phrases such as, Ford’s self-driving car network will launch ‘at scale’ in 2021 – Ford hasn’t been shy about… with the … in the actual tweet. CoreNLP labels this sentence as negative with confidence 0.597.
CoreNLP was trained on movie reviews, so news articles, tweets, and Reddit comments may not match the same kind of words and grammar found in movie reviews. We might have a domain mismatch between the training domain and the actual domain. CoreNLP can be trained on a different dataset but doing so requires that thousands (or 10’s or 100’s of thousands) of examples with known sentiment are available. Every node in the dependency tree of every sentence must be labeled with a known sentiment. This is very time-consuming. The authors of CoreNLP used Amazon Mechanical Turk to recruit humans to perform this labeling task.
To summarize, in this article, we have demonstrated how to identify the sentiment, or general mood, of the feedback from customers and the general public on social media platforms (e.g. Twitter). We also performed sentiment analysis using a method based on machine learning using CoreNLP.
Master essential AI blueprints to program real-world business applications from the book AI Blueprints by Dr Joshua Eckroth.
Read Next
How to perform sentiment analysis using Python [Tutorial]









