









Last week, in a study published on JAMA Network Open, researchers revealed that machine learning algorithms trained with physical activity data collected from health tracking devices can be used to re-identify actual people.
This study indicates that the current practices for anonymizing health information are not sufficient enough. Personal health and fitness data collected and stored by fitness wearable devices can be potentially sold to third parties, like employers, insurance providers, and other companies, without the users’ knowledge or consent. Also, health app makers might be able to link users name to their medical record and then sell this information to third-parties. Location information from activity trackers could be used to reveal sensitive military sites. Therefore, there is a need for a deidentification algorithm that aggregates the physical activity data of multiple individuals to ensure privacy for single individuals.
For this study, the researchers analyzed the National Health and Nutrition Examination Survey (NHANES) 2003-2004 and 2005-2006 datasets. These datasets included recordings from physical activity monitors, during both a training run and an actual study mode, for 4,720 adults and 2,427 children.
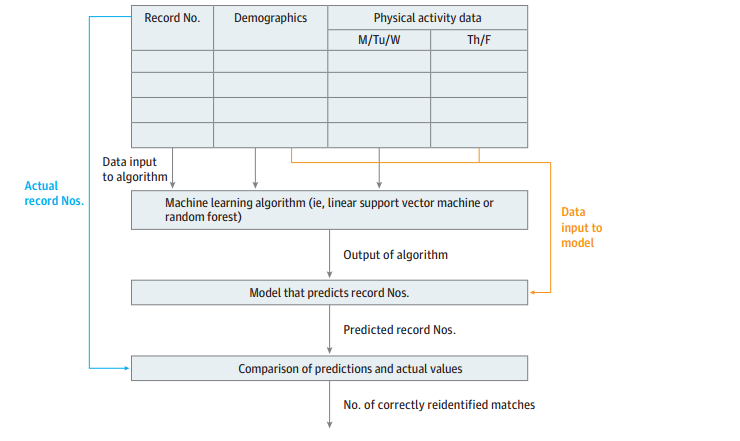
How does the reidentification procedure work?
- The machine learning model was constructed by building a separate multiclass classifier for each combination of demographic attributes. They used two different machine learning algorithms for multiclass classification, namely, linear support vector machine and random forests.
- The models were then tested by feeding in the demographic and physical activity data, but not the record numbers, from the testing data into the models to make predictions of record numbers.
- The accuracy of the models was calculated by counting how many predicted record numbers matched the actual record numbers in the testing data.
The following block diagram depicts the steps of this procedure:
Results of this study
- The random forest algorithm was able to reidentify the demographic and physical activity data of 4478 adults (94.9%) and 2120 children (87.4%) in NHANES 2003-2004 and 4470 adults (93.8%) and 2172 children (85.5%) in NHANES 2005-2006.
- The linear SVM algorithm was able to reidentify the demographic and physical activity data of 4043 adults (85.6%) and 1695 children (69.8%) in NHANES 2003-2004 and 4041 adults (84.8%) and 1705 children (67.2%) in NHANES 2005-2006.
How privacy risks can be reduced?
Per the research paper, the privacy risks posed on individuals by sharing physical data can be reduced by sharing data not only in time but also across individuals of largely different demographics. This is particularly important for governmental organizations such as NHANES that publicly release large national health datasets. Also, currently we do not have strict regulations for organizations that collect and share these sensitive health data. Policymakers should develop regulations to minimize the sharing of activity by device manufacturers.
You can go through the research paper for more details: Feasibility of Reidentifying Individuals in Large National Physical Activity Data Sets From Which Protected Health Information Has Been Removed With Use of Machine Learning.
Read Next
Researchers develop new brain-computer interface that lets paralyzed patients use tablets
Facebook AI researchers investigate how AI agents can develop their own conceptual shared language