









Oracle has released GraphPipe, an open source tool to simplify and standardize deployment of Machine Learning (ML) models easier. Development of ML models is difficult, but deploying the model for the customers to use is equally difficult. There are constant improvements in the development model but, people often don’t think about deployment. This is were GraphPipe comes into the picture!
What are the key challenges GraphPipe aims to solve?
- No standard way to serve APIs: The lack of standard for model serving APIs limits you to work with whatever the framework gives you. Generally, business application will have an auto generated application just to talk to your deployed model. The deployment situation becomes more difficult when you are using multiple frameworks. You’ll have to write custom code to create ensembles of models from multiple frameworks.
- Building model server is complicated: Out-of-the-box solutions for deployment are very few because deployment gets less attention than training.
- Existing solution not efficient enough: Many of the currently used solutions don’t focus on performance, so for certain use cases they fall short.
Here’s how the current situation looks like:
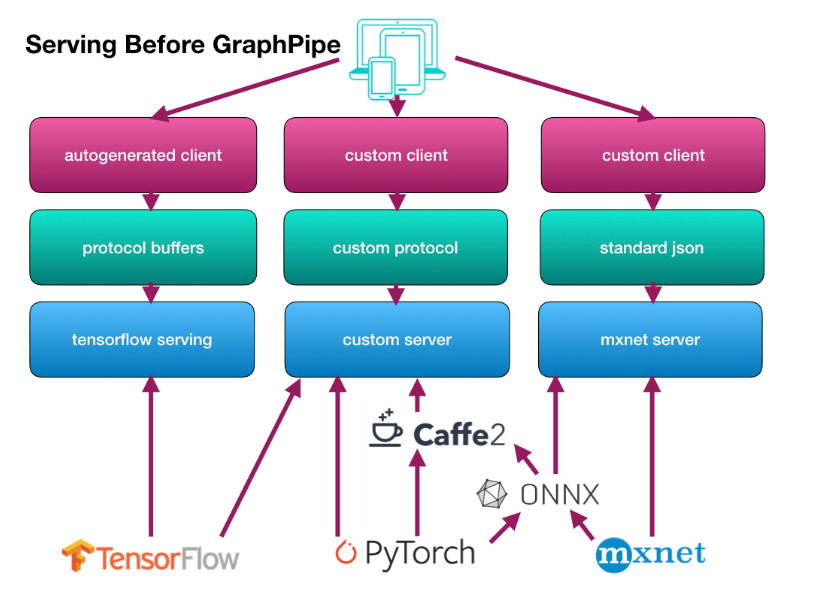
Source: GraphPipe’s User Guide
How GraphPipe solves these problems?
GraphPipe uses flatbuffers as the message format for a predict request. Flatbuffers are like google protocol buffers, with an added benefit of avoiding a memory copy during the deserialization step.
A request message provided by the flatbuffer definition includes:
- Input tensors
- Input names
- Output names
The request message is then accepted by the GraphPipe remote model and returns one tensor per requested output name, along with metadata about the types and shapes of the inputs and outputs it supports.
Here’s how the deployment situation will look like with the use of GraphPipe:
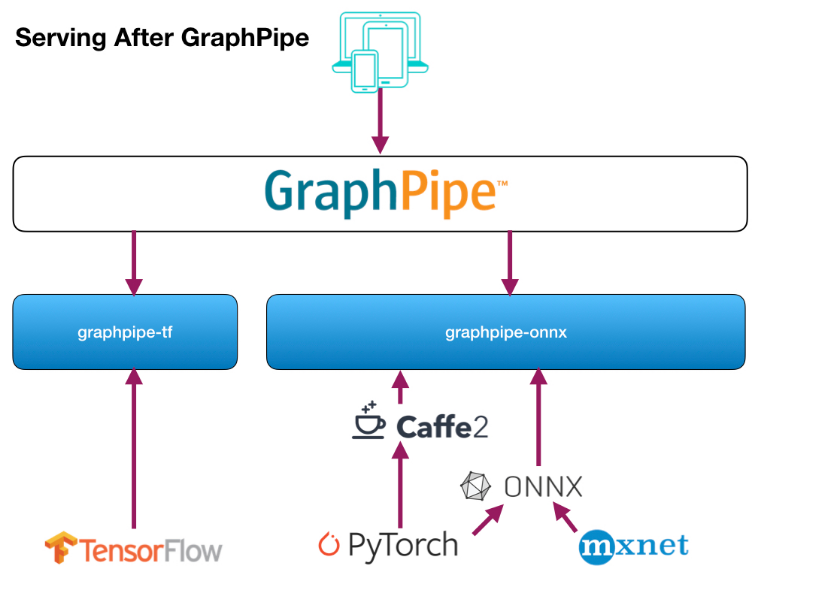
Source: GraphPipe’s User Guide
What are the features it comes with?
- Provides a minimalist machine learning transport specification based on flatbuffers, which is an efficient cross platform serialization library for C++, C#, C, Go, Java, JavaScript, Lobster, Lua, TypeScript, PHP, and Python.
- Comes with simplified implementations of clients and servers that make deploying and querying machine learning models from any framework considerably effortless.
- It’s efficient servers can serve models built in TensorFlow, PyTorch, mxnet, CNTK, or Caffe2.
- Provides efficient client implementations in Go, Python, and Java.
- Includes guidelines for serving models consistently according to the flatbuffer definitions.
You can read plenty of documentation and examples at https://oracle.github.io/graphpipe. The GraphPipe flatbuffer spec can be found on Oracle’s GitHub along with servers that implement the spec for Python and Go.
Read Next
Oracle reveals issues in Object Serialization. Plans to drop it from core Java.
What Google, RedHat, Oracle, and others announced at KubeCon + CloudNativeCon 2018