









Introduction
One of the most important features of relational database management systems—MySQL being no exception—is the use of indexes to allow rapid and efficient access to the enormous amounts of data they keep safe for us. In this article, we will provide some useful recipes for you to get the most out of your databases.
Infinite storage, infinite expectations
We have got accustomed to nearly infinite storage space at our disposal—storing everything from music to movies to high resolution medical imagery, detailed geographical information,or just plain old business data. While we take it for granted that we hardly ever run out of space, we also expect to be able to locate and retrieve every bit of information we save in an instant. There are examples everywhere in our lives—business and personal:
- Your pocket music player’s library can easily contain tens of thousands of songs and yet can be browsed effortlessly by artist name or album title, or show you last week’s top 10 rock songs.
- Search engines provide thousands of results in milliseconds for any arbitrary search term or combination.
- A line of business application can render your sales numbers charted and displayed on a map, grouped by sales district in real-time.
These are a few simple examples, yet for each of them huge amounts of data must be combed to quickly provide just the right subset to satisfy each request. Even with the immense speed of modern hardware, this is not a trivial task to do and requires some clever techniques.
Speed by redundancy
Indexes are based on the principle that searching in sorted data sets is way faster than searching in unsorted collections of records. So when MySQL is told to create an index on one or more columns, it copies these columns’ contents and stores them in a sorted manner. The remaining columns are replaced by a reference to the original table with the unsorted data.
This combines two benefits—providing fast retrieval while maintaining reasonably efficient storage requirements. So, without wasting too much space this approach enables you to create several of those indexes (or indices, both are correct) at a relatively low cost.
However, there is a drawback to this as well: while reading data, indexes allow for immense speeds, especially in large databases; however, they do slow down writing operations. In the course of INSERTs, UPDATEs, and DELETEs, all indexes need to be updated in addition to the data table itself. This can place significant additional load on the server, slowing down all operations.
For this reason, keeping the number of indexes as low as possible is paramount, especially for the largest tables where they are most important. In this article, you’ll find some recipes that will help you to decide how to define indexes and show you some pitfalls to avoid.
Storage engine differences
We will not go into much detail here about the differences between the MyISAM and the InnoDB storage engines offered by MySQL. However, regarding indexes there are some important differences to know between MySQL’s two most important storage engines. They influence some decisions you will have to make.
MyISAM
In the figure below you can see a simplified schema of how indexes work with the MyISAM storage engine. Their most important property can be summed up as “all indexes are created equal”. This means that there is no technical difference between the primary and secondary keys.
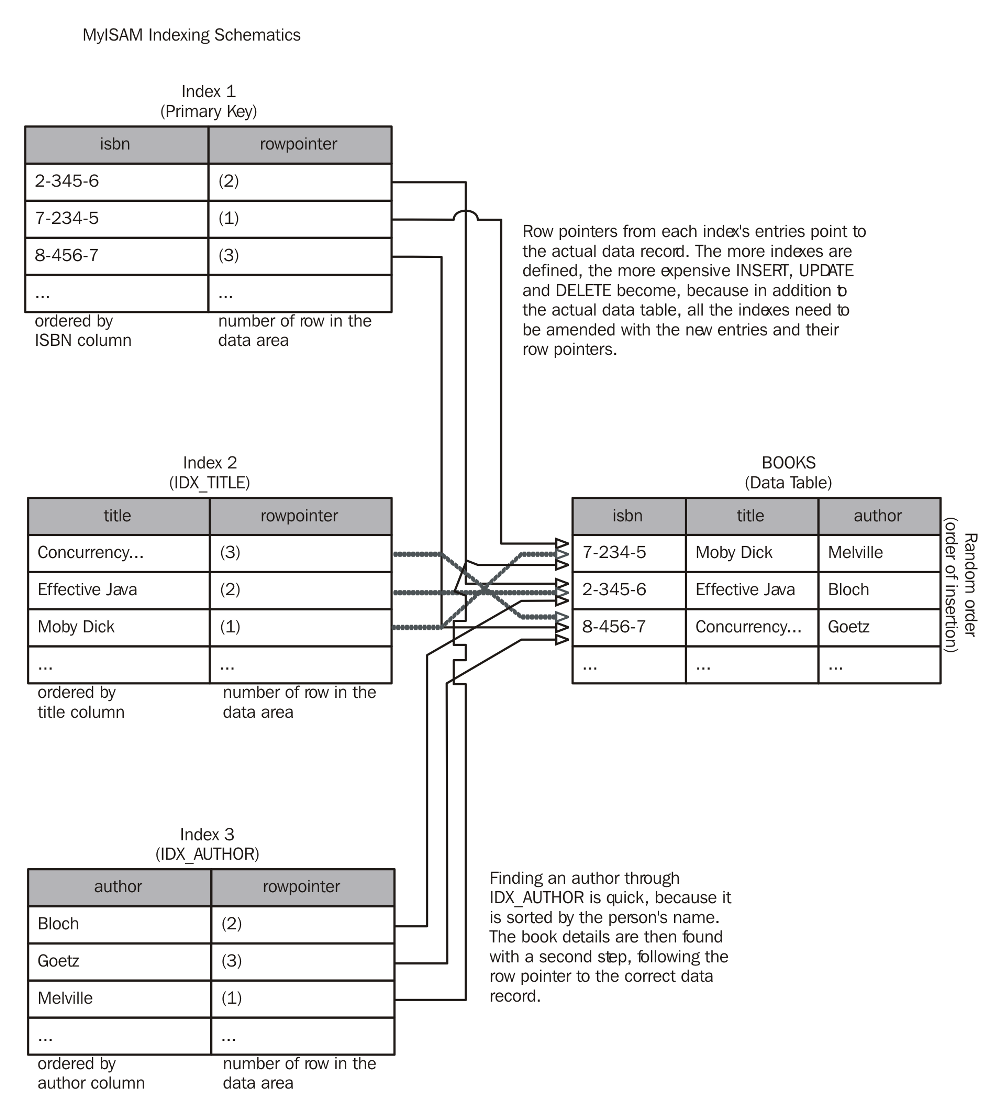
The diagram shows a single (theoretical) data table called books. It has three columns named isbn, title, and author. This is a very simple schema, but it is sufficient for explanation purposes. The exact definition can be found in the Adding indexes to tables recipe in this article. For now, it is not important.
MyISAM tables store information in the order it is inserted. In the example, there are three records representing a single book each. The ISBN number is declared as the primary key for this table. As you can see, the records are not ordered in the table itself—the ISBN numbers are out of what would be their lexical order. Let’s assume they have been inserted by someone in this order.
Now, have a look at the first index—the PRIMARY KEY. The index is sorted by the isbn column. Associated with each index entry is a row pointer that leads to the actual data record in the books table. When looking up a specific ISBN number in the primary key index, the database server follows the row pointer to retrieve the remaining data fields. The same holds true for the other two indexes IDX_TITLE and IDX_AUTHOR, which are sorted by the respective fields and also contain a row pointer each.
Looking up a book’s details by any one of the three possible search criteria is a two-part operation: first, find the index record, and then follow the row pointer to get the rest of the data.
With this technique you can insert data very quickly because the actual data records are simply appended to the table. Only the relatively small index records need to be kept in order, meaning much less data has to be shuffled around on the disk.
There are drawbacks to this approach as well. Even in cases where you only ever want to look up data by a single search column, there will be two accesses to the storage subsystem—one for the index, another for the data.
InnoDB
However, InnoDB is different. Its index system is a little more complicated, but it has some advantages:
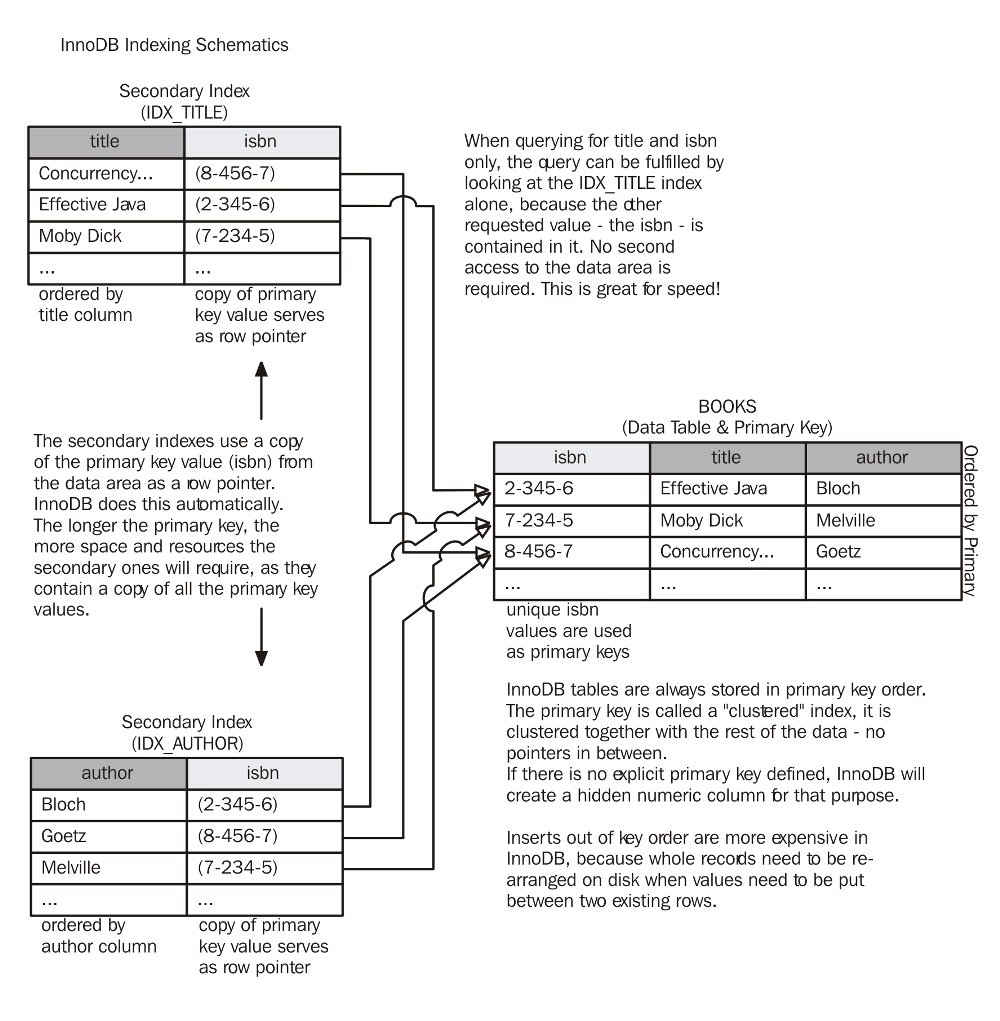
Primary (clustered) indexes
Whereas in MyISAM all indexes are structured identically, InnoDB makes a distinction between the primary key and additional secondary ones.
The primary index in InnoDB is a clustered index. This means that one or more columns of each record make up a unique key that identifies this exact record. In contrast to other indexes, a clustered index’s main property is that it itself is part of the data instead of being stored in a different location. Both data and index are clustered together.
An index is only serving its purpose if it is stored in a sorted fashion. As a result, whenever you insert data or modify the key column(s), it needs to be put in the correct location according to the sort order. For a clustered index, the whole record with all its data has to be relocated.
That is why bulk data insertion into InnoDB tables is best performed in correct primary key order to minimize the amount of disk I/O needed to keep the records in index order. Moreover, the clustered index should be defined so that it is hardly ever changed for existing rows, as that too would mean relocating full records to different sectors on the disk.
Of course, there are significant advantages to this approach. One of the most important aspects of a clustered key is that it actually is a part of the data. This means that when accessing data through a primary key lookup, there is no need for a two-part operation as with MyISAM indexes. The location of the index is at the same time the location of the data itself—there is no need for following a row pointer to get the rest of the column data, saving an expensive disk access.
Secondary indexes
Consider if you were to search for a book by title to find out the ISBN number. An index on the name column is required to prevent the database from scanning through the whole (ISBN-sorted) table. In contrast to MyISAM, the InnoDB storage engine creates secondary indexes differently.
Instead of record pointers, it uses a copy of the whole primary key for each record to establish the connection to the actual data contents.
In the previous figure, have a look at the IDX_TITLE index. Instead of a simple pointer to the corresponding record in the data table, you can see the ISBN number duplicated as well. This is because the isbn column is the primary key of the books table. The same goes for the other indexes in the figure—they all contain the book ISBN number as well. You do not need to (and should not) specify this yourself when creating and indexing on InnoDB tables, it all happens automatically under the covers.
Lookups by secondary index are similar to MyISAM index lookups. In the first step, the index record that matches your search term is located. Then secondly, the remaining data is retrieved from the data table by means of another access—this time by primary key.
As you might have figured, the second access is optional, depending on what information you request in your query. Consider a query looking for the ISBN numbers of all known issues of Moby Dick:
SELECT isbn FROM books WHERE title LIKE 'Moby Dick%';
Issued against a presumably large library database, it will most certainly result in an index lookup on the IDX_TITLE key. Once the index records are found, there is no need for another lookup to the actual data pages on disk because the ISBN number is already present in the index. Even though you cannot see the column in the index definition, MySQL will skip the second seek saving valuable I/O operations.
But there is a drawback to this as well. MyISAM’s row pointers are comparatively small. The primary key of an InnoDB table can be much bigger—the longer the key, the more the data that is stored redundantly.
In the end, it can often be quite difficult to decide on the optimal balance between increased space requirements and maintenance costs on index updates. But do not worry; we are going to provide help on that in this article as well.
General requirements for the recipes in this article
All the recipes in this article revolve around changing the database schema. In order to add indexes or remove them, you will need access to a user account that has an effective INDEX privilege or the ALTER privilege on the tables you are going to modify.
While the INDEX privilege allows for use of the CREATE INDEX command, ALTER is required for the ALTER TABLE ADD INDEX syntax. The MySQL manual states that the former is mapped to the latter automatically. However, an important difference exists: CREATE INDEX can only be used to add a single index at a time, while ALTER TABLE ADD INDEX can be used to add more than one index to a table in a single go.
This is especially relevant for InnoDB tables because up to MySQL version 5.1 every change to the definition of a table internally performs a copy of the whole table. While for small databases this might not be of any concern, it quickly becomes infeasible for large tables due to the high load copying may put on the server. With more recent versions this might have changed, but make sure to consult your version’s manual.
In the recipes throughout this article, we will consistently use the ALTER TABLE ADD INDEX syntax to modify tables, assuming you have the appropriate privileges. If you do not, you will have to rewrite the statements to use the CREATE INDEX syntax.
Adding indexes to tables
Over time requirements for a software product usually change and affect the underlying database as well. Often the need for new types of queries arises, which makes it necessary to add one or more new indexes to perform these new queries fast enough.
In this recipe, we will add two new indexes to an existing table called books in the library schema. One will cover the author column, the other the title column. The schema and table can be created like this:
mysql> CREATE DATABASE library;
mysql> USE library;
mysql> CREATE TABLE books (
isbn char(13) NOT NULL,
author varchar(64) default NULL,
title varchar(64) NOT NULL,
PRIMARY KEY (isbn)
) ENGINE=InnoDB;
Getting ready
Connect to the database server with your administrative account.


