









Reinforcement learning (RL) agents explore their environments to learn optimal policies by trial and error method. In such environments, one of the critical concerns is the safety of all the agents involved in the experiment. Though, currently, the reinforcement learning agents are mostly executed in simulation, there is a possibility that increased simulation complexities of the real world, will make the safety concerns paramount.
To undertake safe exploration as a critical focus of the reinforcement learning research, a group of OpenAI researchers have proposed a new standardized constrained reinforcement learning (RL) method to incorporate safety specifications into reinforcement learning algorithms to achieve safe exploration.
The major challenge of reinforcement learning is handling the trade-offs between competing objectives, such as task performance and satisfying safety requirements. However, in constrained reinforcement learning, “we don’t have to pick trade-offs—instead, we pick outcomes, and let algorithms figure out the trade-offs that get us the outcomes we want,” states OpenAI. Consequently, the researchers believe “constrained reinforcement learning may turn out to be more useful than normal reinforcement learning for ensuring that agents satisfy safety requirements.”
The field of reinforcement learning has greatly progressed in recent years, however, different implementations use different environments and evaluation procedures. Hence, the researchers believe that there is a deficiency of a standard set of environments for making progress on safe exploration specifically. To this end, the researchers present Safety Gym, a suite of tools for accelerating safe exploration research. Safety Gym is a benchmark suite of 18 high-dimensional continuous control environments for safe exploration, 9 additional environments for debugging task performance separately from safety requirements, and tools for building additional environments.
We're releasing Safety Gym, environments and tools to evaluate reinforcement learning with safety constraints: https://t.co/3fj0at6UVV
Aims to ultimately help agents satisfy real-world safety requirements while training (eg not driving off a cliff, not writing abusive content). pic.twitter.com/VTwS4KoFS1
— OpenAI (@OpenAI) November 21, 2019
How does a Safety Gym prioritize safety exploration in reinforcement learning
Safety Gym consists of two components, out of which first is an environment-builder that allows a user to create a new environment by mixing and matching from a wide range of physics elements, goals, and safety requirements. The other component of Safety Gym is a suite of pre-configured benchmark environment to standardize the measure of progress on the safe exploration problem.
It is implemented as a standalone module that uses the OpenAI Gym interface for instantiating and interacting with reinforcement learning environments. It also uses the MuJoCo physics simulator to construct and forward-simulate each environment.
In line with the proposal of standardizing constrained reinforcement learning, each Safety Gym environment provides a separate objective for task performance and safety. These objectives are conveyed via a reward function and a set of auxiliary cost functions respectively.
Key features of Safety Gym
- Since there exists a gradient of difficulty across benchmark environments, it allows practitioners to quickly perform the simplest tasks before proceeding to the hardest ones.
- Each distribution layer of the Safety Gym benchmark environments is continuous and minimally restricted, thus allowing essentially infinite variations within each environment.
- It is highly extensible. The Safety Gym tools enables easy building of new environments with different layout distributions.
In all Safety Gym environments, an agent perceives the surrounding through a robot’s sensors and interacts with the world through its actuators. It is shipped with three pre-made robots.
Three pre-made robots included in the Safety Gym suite
- Point is a simple robot that is limited to the 2D plane. It uses one actuator for turning and another for moving forward or backward. It has a front-facing small square which helps it with the Push task.
- Car has two independently-driven parallel wheels and a free-rolling rear wheel. For this robot, turning and moving forward or backward require coordinating both of the actuators.
- Doggo is a quadrupedal robot with bilateral symmetry. Each of the four legs has two controls at the hip, and one in the knee which controls the angle. It is designed such that a uniform random policy should keep the robot from falling over and generate some travel.
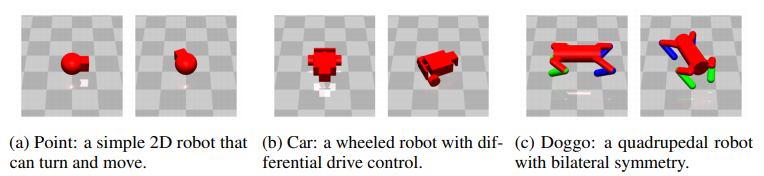
Image source: Research paper
These three environment-builders currently support three main tasks of Goal, Button and Push. All the tasks in Safety Gym are mutually exclusive and can work on only one task at a time. It supports five main kinds of elements relevant to safety requirements like Hazards (dangerous areas to avoid), Vases (Objects to avoid), Pillars (Immobile obstacles), Buttons (Incorrect goals), and Gremlins (Moving objects). All the types of constraint elements pose different challenges for the agent to avoid.
General trends observed during the experiment
After conducting experiments on the unconstrained and constrained reinforcement learning algorithms on the constrained Safety Gym environments, the researchers found that the unconstrained reinforcement learning algorithms are able to score high returns by taking unsafe actions, as measured by the cost function. On the other hand, the constrained reinforcement learning algorithms attain lower levels of return, and correspondingly maintain desired levels of costs.
Also, they found that the standard reinforcement learning is able to control the Doggo robot and can acquire complex locomotion behavior, as indicated by high returns in the environments when trained without constraints. However,despite the success of constrained reinforcement learning when locomotion requirements are absent, and the success of standard reinforcement learning when locomotion is needed, the constrained reinforcement learning algorithms struggled to learn the safe locomotion policies. The researchers also state that additional research is needed to develop constrained reinforcement learning algorithms that can solve more challenging tasks.
Thus the OpenAI researchers propose a standardized constrained reinforcement learning as the main formalism for safe exploration. They also introduce Safety Gym which is the first benchmark of high-dimensional continuous control environments for evaluating the performance of constrained reinforcement learning algorithms. The researchers have also evaluated baseline unconstrained and constrained reinforcement learning algorithms on Safety Gym environments to clarify the current state of the art in safe exploration.
Many have appreciated Safety Gym’s feature of prioritizing ‘safety’ first in AI.
That’s it, thanks! Neither superhero powers nor cheating tricks work in the real, physically constrained world, hence the need to have your Gym as level as possible for our applied experiments. Kudos!!
— Giuseppe Cornacchia (@gicorit) November 21, 2019
Every trade says “safety first”, why should AI say anything else? | OpenAI releases “Safety Gym” for reinforcement learning, with safety at its core. https://t.co/NBj3BHGJzx
— Vikas Rajput (@tupjarsakiv) November 21, 2019
Interested reader can read the research paper for more information on Safety Gym.
Read Next
What does a data science team look like?
NVIDIA releases Kaolin, a PyTorch library to accelerate research in 3D computer vision and AI