Let's first see how we can create documents in MongoDB. As we have briefly seen, MongoDB deals with collections and documents instead of tables and rows.
Time for action – creating our first document
Suppose we want to create the book object having the following schema:
On the Mongo CLI, we can add this book object to our collection using the following command:
> db.books.insert(book)
Suppose we also add the shelf collection (for example, the floor, the row, the column the shelf is in, the book indexes it maintains, and so on that are part of the shelf object), which has the following structure:
Remember, it's quite possible that a few years down the line, some shelf instances may become obsolete and we might want to maintain their record. Maybe we could have another shelf instance containing only books that are to be recycled or donated. What can we do? We can approach this as follows:
The SQL way: Add additional columns to the table and ensure that there is a default value set in them. This adds a lot of redundancy to the data. This also reduces the performance a little and considerably increases the storage. Sad but true!
The NoSQL way: Add the additional fields whenever you want. The following are the MongoDB schemaless object model instances:
You will notice that the second object has more fields, namely comments and state. When fetching objects, it's fine if you get extra data. That is the beauty of NoSQL. When the first document is fetched (the one with the name Fiction), it will not contain the state and comments fields but the second document (the one with the name Romance) will have them. Are you worried what will happen if we try to access non-existing data from an object, for example, accessing comments from the first object fetched? This can be logically resolved—we can check the existence of a key, or default to a value in case it's not there, or ignore its absence. This is typically done anyway in code when we access objects. Notice that when the schema changed we did not have to add fields in every object with default values like we do when using a SQL database. So there is no redundant information in our database. This ensures that the storage is minimal and in turn the object information fetched will have concise data. So there was no redundancy and no compromise on storage or performance. But wait! There's more.
NoSQL scores over SQL databases
The way many-to-many relations are managed tells us how we can do more with MongoDB that just cannot be simply done in a relational database. The following is an example:
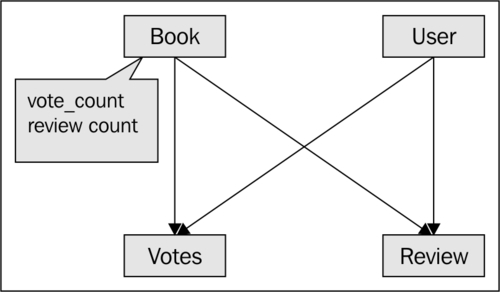
Each book can have reviews and votes given by customers. We should be able to see these reviews and votes and also maintain a list of top voted books.
If we had to do this in a relational database, this would be somewhat like the relationship diagram shown as follows: (get scared now!)
The vote_count and review_count fields are inside the books table that would need to be updated every time a user votes up/down a book or writes a review. So, to fetch a book along with its votes and reviews, we would need to fire three queries to fetch the information:
SELECT * from book where id = 3;
SELECT * from reviews where book_id = 3;
SELECT * from votes where book_id = 3;
We could also use a join for this:
SELECT * FROM books JOIN reviews ON reviews.book_id = books.id JOIN votes
ON votes.book_id = books.id;
In MongoDB, we can do this directly using embedded documents or relational documents.
Using MongoDB embedded documents
Embedded documents, as the name suggests, are documents that are embedded in other documents. This is one of the features of MongoDB and this cannot be done in relational databases. Ever heard of a table embedded inside another table?
Instead of four tables and a complex many-to-many relationship, we can say that reviews and votes are part of a book. So, when we fetch a book, the reviews and the votes automatically come along with the book.
Embedded documents are analogous to chapters inside a book. Chapters cannot be read unless you open the book. Similarly embedded documents cannot be accessed unless you access the document.
For the UML savvy, embedded documents are similar to the contains or composition relationship.
Time for action – embedding reviews and votes
In MongoDB, the embedded object physically resides inside the parent. So if we had to maintain reviews and votes we could model the object as follows:
We now have reviews and votes inside the book. They cannot exist on their own. Did you notice that they look similar to JSON hashes and arrays? Indeed, they are an array of hashes. Embedded documents are just like hashes inside another object.
There is a subtle difference between hashes and embedded objects as we shall see later on in the book.
Have a go hero – adding more embedded objects to the book
Try to add more embedded objects such as orders inside the book document. It works!
This does indeed look simple, doesn't it? By fetching a single object, we are able to get the review and vote count along with the data.
Use embedded documents only if you really have to! Embedded documents increase the size of the object. So, if we have a large number of embedded documents, it could adversely impact performance. Even to get the name of the book, the reviews and the votes are fetched.
Using MongoDB document relationships
Just like we have embedded documents, we can also set up relationships between different documents.
Time for action – creating document relations
The following is another way to create the same relationship between books, users, reviews, and votes. This is more like the SQL way.
book: {
_id: ObjectId("4e81b95ffed0eb0c23000002"),
name: "Oliver Twist",
author: "Charles Dickens",
publisher: "Dover Publications",
published_on: "December 30, 2002",
category: ['Classics', 'Drama']
}
Every document that is created in MongoDB has an object ID associated
with it. In the next chapter, we shall soon learn about object IDs in
MongoDB. By using these object IDs we can easily identify different
documents. They can be considered as primary keys.
So, we can also create the reviews collection and the votes collection as follows:
users: [
{
_id: ObjectId("8d83b612fed0eb0bee000702"),
name: "Gautam"
},
{
_id : ObjectId("ab93b612fed0eb0bee000883"),
name: "Harry"
}
]
reviews: [
{
_id: ObjectId("5e85b612fed0eb0bee000001"),
user_id: ObjectId("8d83b612fed0eb0bee000702"),
book_id: ObjectId("4e81b95ffed0eb0c23000002"),
comment: "Very interesting read"
},
{
_id: ObjectId("4585b612fed0eb0bee000003"),
user_id : ObjectId("ab93b612fed0eb0bee000883"),
book_id: ObjectId("4e81b95ffed0eb0c23000002"),
comment: "Who is Oliver Twist?"
}
]
votes: [
{
_id: ObjectId("6e95b612fed0eb0bee000123"),
user_id : ObjectId("8d83b612fed0eb0bee000702"),
book_id: ObjectId("4e81b95ffed0eb0c23000002"),
},
{
_id: ObjectId("4585b612fed0eb0bee000003"),
user_id : ObjectId("ab93b612fed0eb0bee000883"),
}
]
What just happened?
Hmm!! Not very interesting, is it? It doesn't even seem right. That's because it isn't the right choice in this context. It's very important to know how to choose between nesting documents and relating them.
In your object model, if you will never search by the nested document (that is, look up for the parent from the child), embed it.
Just in case you are not sure about whether you would need to search by an embedded document, don't worry too much – it does not mean that you cannot search among embedded objects. You can use Map/Reduce to gather the information.
Comparing MongoDB versus SQL syntax
This is a good time to sit back and evaluate the similarities and dissimilarities between the MongoDB syntax and the SQL syntax. Let's map them together:
SQL commands
NoSQL (MongoDB) equivalent
SELECT * FROM books
Unlock access to the largest independent learning library in Tech for FREE!
Get unlimited access to 7500+ expert-authored eBooks and video courses covering every tech area you can think of.
Renews at $19.99/month. Cancel anytime
db.books.find()
SELECT * FROM books WHERE id = 3;
db.books.find( { id : 3 } )
SELECT * FROM books WHERE name LIKE 'Oliver%'
db.books.find( { name : /^Oliver/ } )
SELECT * FROM books WHERE name like '%Oliver%'
db.books.find( { name : /Oliver/ } )
SELECT * FROM books WHERE publisher = 'Dover Publications' AND published_date = "2011-8-01"
Some more notable comparisons between MongoDB and relational databases are:
MongoDB does not support joins. Instead it fires multiple queries or uses Map/Reduce. We shall soon see why the NoSQL faction does not favor joins.
SQL has stored procedures. MongoDB supports JavaScript functions.
MongoDB has indexes similar to SQL.
MongoDB also supports Map/Reduce functionality.
MongoDB supports atomic updates like SQL databases.
Embedded or related objects are used sometimes instead of a SQL join.
MongoDB collections are analogous to SQL tables.
MongoDB documents are analogous to SQL rows.
Using Map/Reduce instead of join
We have seen this mentioned a few times earlier—it's worth jumping into it, at least briefly.
Map/Reduce is a concept that was introduced by Google in 2004. It's a way of distributed task processing. We "map" tasks to works and then "reduce" the results.
Understanding functional programming
Functional programming is a programming paradigm that has its roots from lambda calculus. If that sounds intimidating, remember that JavaScript could be considered a functional language. The following is a snippet of functional programming:
$(document).ready( function () {
$('#element').click( function () {
# do something here
});
$('#element2').change( function () {
# do something here
})
});
We can have functions inside functions. Higher-level languages (such as Java and Ruby) support anonymous functions and closures but are still procedural functions. Functional programs rely on results of a function being chained to other functions.
Building the map function
The map function processes a chunk of data. Data that is fed to this function could be accessed across a distributed filesystem, multiple databases, the Internet, or even any mathematical computation series!
function map(void) -> void
The map function "emits" information that is collected by the "mystical super gigantic computer program" and feeds that to the reducer functions as input. MongoDB as a database supports this paradigm making it "the all powerful" (of course I am joking, but it does indeed make MongoDB very powerful).
Time for action – writing the map function for calculating vote statistics
Let's assume we have a document structure as follows:
The emit function emits the data. Notice that the data is emitted as a (key, value) structure.
Key: This is the parameter over which we want to gather information. Typically it would be some primary key, or some key that helps identify the information.
For the SQL savvy, typically the key is the field we use in the GROUP BY clause.
Value: This is a JSON object. This can have multiple values and this is the data that is processed by the reduce function.
We can call emit more than once in the map function. This would mean we are processing data multiple times for the same object.
Building the reduce function
The reduce functions are the consumer functions that process the information emitted from the map functions and emit the results to be aggregated. For each emitted data from the map function, a reduce function emits the result. MongoDB collects and collates the results. This makes the system of collection and processing as a massive parallel processing system giving the all mighty power to MongoDB.
The reduce functions have the following signature:
function reduce(key, values_array) -> value
Time for action – writing the reduce function to process emitted information
This could be the reduce function for the previous example:
function(key, values) {
var result = {votes: 0}
values.forEach(function(value) {
result.votes += value.votes;
});
return result;
}
What just happened?
reduce takes an array of values – so it is important to process an array every time. There are various options to Map/Reduce that help us process data.
Let's analyze this function in more detail:
function(key, values) {
var result = {votes: 0}
values.forEach(function(value) {
result.votes += value.votes;
});
return result;
}
The variable result has a structure similar to what was emitted from the map function. This is important, as we want the results from every document in the same format. If we need to process more results, we can use the finalize function (more on that later). The result function has the following structure:
function(key, values) {
var result = {votes: 0}
values.forEach(function(value) {
result.votes += value.votes;
});
return result;
}
The values are always passed as arrays. It's important that we iterate the array, as there could be multiple values emitted from different map functions with the same key. So, we processed the array to ensure that we don't overwrite the results and collate them.

 United States
United States
 Great Britain
Great Britain
 India
India
 Germany
Germany
 France
France
 Canada
Canada
 Russia
Russia
 Spain
Spain
 Brazil
Brazil
 Australia
Australia
 Singapore
Singapore
 Canary Islands
Canary Islands
 Hungary
Hungary
 Ukraine
Ukraine
 Luxembourg
Luxembourg
 Estonia
Estonia
 Lithuania
Lithuania
 South Korea
South Korea
 Turkey
Turkey
 Switzerland
Switzerland
 Colombia
Colombia
 Taiwan
Taiwan
 Chile
Chile
 Norway
Norway
 Ecuador
Ecuador
 Indonesia
Indonesia
 New Zealand
New Zealand
 Cyprus
Cyprus
 Denmark
Denmark
 Finland
Finland
 Poland
Poland
 Malta
Malta
 Czechia
Czechia
 Austria
Austria
 Sweden
Sweden
 Italy
Italy
 Egypt
Egypt
 Belgium
Belgium
 Portugal
Portugal
 Slovenia
Slovenia
 Ireland
Ireland
 Romania
Romania
 Greece
Greece
 Argentina
Argentina
 Netherlands
Netherlands
 Bulgaria
Bulgaria
 Latvia
Latvia
 South Africa
South Africa
 Malaysia
Malaysia
 Japan
Japan
 Slovakia
Slovakia
 Philippines
Philippines
 Mexico
Mexico
 Thailand
Thailand