









Last week, researchers from the Imperial College in London and Samsung’s AI research center in the UK revealed how deepfakes can be used to generate a singing or talking video portrait by from a still image of a person and an audio clip containing speech.
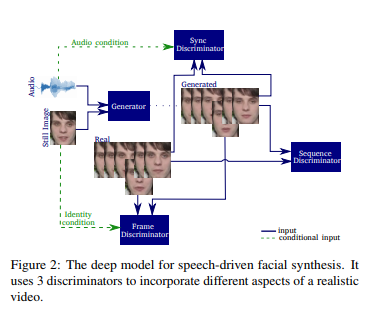
In their paper titled, “Realistic Speech-Driven Facial Animation with GANs”, the researchers have used temporal GAN which uses 3 discriminators focused on achieving detailed frames, audio-visual synchronization, and realistic expressions.
Source: arxiv.org
“The generated videos are evaluated based on sharpness, reconstruction quality, lip-reading accuracy, synchronization as well as their ability to generate natural blinks”, the researchers mention in their paper.
Researchers used the GRID, TCD TIMIT, CREMA-D and LRW datasets.
- The GRID dataset has 33 speakers each uttering 1000 short phrases, containing 6 words randomly chosen from a limited dictionary.
- The TCD TIMIT dataset has 59 speakers uttering approximately 100 phonetically rich sentences each.
- The CREMA-D dataset includes 91 actors coming from a variety of different age groups and races utter 12 sentences.
Each sentence is acted out by the actors multiple times for different emotions and intensities. Researchers have used the recommended data split for the TCD TIMIT dataset but exclude some of the test speakers and use them as a validation set. Researchers performed data augmentation on the training set by mirroring the videos.
Metrics used to assess the quality of generated videos
Researchers evaluated the videos using traditional image reconstruction and sharpness metrics. These metrics can be used to determine frame quality; however, they fail to reflect other important aspects of the video such as audio-visual synchrony and the realism of facial expressions. Hence they have also proposed alternative methods capable of capturing these aspects of the generated videos.
Reconstruction Metrics
This method uses common reconstruction metrics such as the peak signal-to-noise ratio (PSNR) and the structural similarity (SSIM) index to evaluate the generated videos. However, the researchers reveal that “reconstruction metrics will penalize videos for any facial expression
that does not match those in the ground truth videos”.
Sharpness Metrics
The frame sharpness is evaluated using the cumulative probability blur detection (CPBD) measure, which determines blur based on the presence of edges in the image. For this metric as well as for the reconstruction metrics larger values imply better quality.
Content Metrics
The content of the videos is evaluated based on how well the video captures the identity of the target and on the accuracy of the spoken words. The researchers have verified the identity of the speaker using the average content distance (ACD), which measures the average Euclidean distance of the still image representation, obtained using OpenFace from the representation of the generated frames.
The accuracy of the spoken message is measured using the word error rate (WER) achieved by a pre-trained lip-reading model. They used the LipNet model which exceeds the performance of human lip-readers on the GRID dataset. For both content metrics, lower values indicate better accuracy.
Audio-Visual Synchrony Metrics
Synchrony is quantified in Joon Son Chung and Andrew Zisserman’s “Out of time: automated lip sync in the wild”. In this work Chung et al. propose the SyncNet network which calculates the euclidean distance between the audio and video encodings on small (0.2 second) sections of the video.
The audio-visual offset is obtained by using a sliding window approach to find where the distance is minimized. The offset is measured in frames and is positive when the audio leads the video. For audio and video pairs that correspond to the same content, the distance will increase on either side of the point where the minimum distance occurs. However, for uncorrelated audio and video, the distance is expected to be stable.
Based on this fluctuation they further propose using the difference between the minimum and the median of the Euclidean distances as an audio-visual (AV) confidence score which determines the audio-visual correlation. Higher scores indicate a stronger correlation, whereas confidence scores smaller than 0.5 indicate that
Limitations and the possible misuse of Deepfake
The limitation of this new Deepfake method is that it only works for well-aligned frontal faces. “the natural progression of this work will be to produce videos that simulate in wild conditions”, the researchers mention.
While this research appears the next milestone for GANs in generating videos from still photos, it also may be misused for spreading misinformation by morphing video content from any still photograph.
Recently, at the House Intelligence Committee hearing, Top House Democrat Rep. Adam Schiff (D-CA) issued a warning on Thursday that deepfake videos could have a disastrous effect on the 2020 election cycle.
“Now is the time for social media companies to put in place policies to protect users from this kind of misinformation not in 2021 after viral deepfakes have polluted the 2020 elections,” Schiff said. “By then it will be too late.”
The hearing came only a few weeks after a real-life instance of a doctored political video, where the footage was edited to make House Speaker Nancy Pelosi appear drunk, that spread widely on social media. “Every platform responded to the video differently, with YouTube removing the content, Facebook leaving it up while directing users to coverage debunking it, and Twitter simply letting it stand,” The Verge reports.
YouTube took the video down; however, Facebook refused to remove the video. Neil Potts, Public Policy Director of Facebook had stated that if someone posted a doctored video of Zuckerberg, like one of Pelosi, it would stay up.
After this, on June 11, a fake video of Mark Zuckerberg was posted on Instagram, under the username, bill_posters_uk. In the video, Zuckerberg appears to give a threatening speech about the power of Facebook.
A fake video of Mark Zuckerberg giving a sinister speech about the power of Facebook has been posted to Instagram. The company previously said it would not remove this type of video. https://t.co/0kTg4OZE4c
— Motherboard (@motherboard) June 11, 2019
Omer Ben-Ami, one of the founders of Canny says that the video is made to educate the public on the uses of AI and to make them realize the potential of AI. Though Zuckerberg’s video was to retain the educational value of Deepfakes, this shows the potential of how it can be misused.
Although some users say it has interesting applications, many are concerned that the chances of misusing this software are more than putting it into the right use.
Previous methods of detecting deep fakes used 'frame by frame' analysis to detect manipulation.
Using verified videos+AI, this method looks for inconsistencies in facial motion.
If this takes off, you can imagine people will begin to be guarded about real videos of themselves
— Tim Mak (@timkmak) June 20, 2019
A user commented on Reddit, “It has some really cool applications though. For example in your favorite voice acted video game, if all of the characters lips would be in sync with the vocals no matter what language you are playing the game in, without spending tons of money having animators animate the characters for every vocalization.”
To know more about this new Deepfake, read the official research paper.