









Paintings require a special skill only a few have mastered. Paintings present a complex interplay of content and style. Photographs, on the other hand, are a combination of perspectives and light. When the two are combined, the results are spectacular and surprising. This process is called artistic style transfer.
In this tutorial, we will be focusing on leveraging deep learning along with transfer learning for building a neural style transfer system. This article will walk you through the theoretical concepts around neural style transfer, loss functions, and optimization. Besides this, we will use a hands-on approach to implement our own neural style transfer model.
[box type=”shadow” align=”” class=”” width=””]This article is an excerpt from a book written by Dipanjan Sarkar, Raghav Bali, and Tamoghna Ghosh titled Hands-On Transfer Learning with Python. To follow along with the article, you can find the code in the book’s GitHub repository.[/box]
Understanding neural style transfer
Neural style transfer is the process of applying the style of a reference image to a specific target image, such that the original content of the target image remains unchanged. Here, style is defined as colours, patterns, and textures present in the reference image, while content is defined as the overall structure and higher-level components of the image.
Here, the main objective is to retain the content of the original target image, while superimposing or adopting the style of the reference image on the target image. To define this concept mathematically, consider three images: the original content (c), the reference style (s), and the generated image (g). We would need a way to measure how different images c and g might be in terms of their content. Also, the output image should have less difference compared to the style image, in terms of styling features of the output. Formally, the objective function for neural style transfer can be formulated as follows:
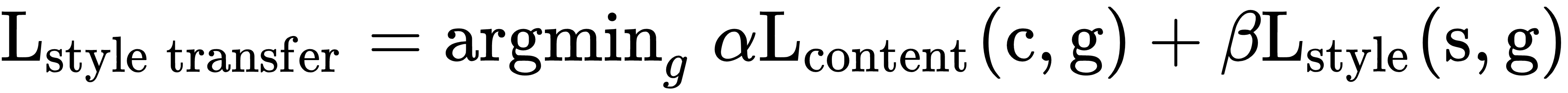
Here, α and β are weights used to control the impact of content and style components on the overall loss. This depiction can be simplified further and represented as follows:
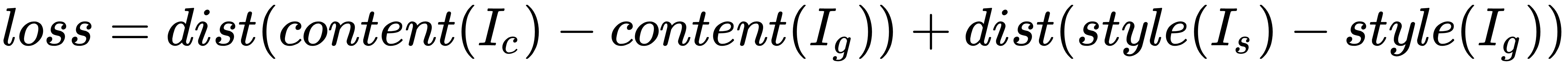
Here, we can define the following components from the preceding formula:
- dist is a norm function; for example, the L2 norm distance
- style(...) is a function to compute representations of style for the reference style and generated images
- content(...) is a function to compute representations of content for the original content and generated images
- Ic, Is, and Ig are the content, style, and generated images respectively
Thus, minimizing this loss causes style(Ig) to be close to style(Is), and also content(Ig) to be close to content(Ic). This helps us in achieving the necessary stipulations for effective style transfer. The loss function we will try to minimize consists of three parts; namely, the content loss, the style loss, and the total variation loss, which we will be talking about soon.
The main steps for performing neural style transfer are depicted as follows:
- Leverage VGG-16 to help compute layer activations for the style, content, and generated image
- Use these activations to define the specific loss functions mentioned earlier
- Finally, use gradient descent to minimize the overall loss
Image preprocessing methodology
The first and foremost step towards implementation of such a network is to preprocess the data or images in this case. The following code snippet shows some quick utilities to preprocess and post-process images for size and channel adjustments:
import numpy as np
from keras.applications import vgg16
from keras.preprocessing.image import load_img, img_to_array
def preprocess_image(image_path, height=None, width=None):
height = 400 if not height else height
width = width if width else int(width * height / height)
img = load_img(image_path, target_size=(height, width))
img = img_to_array(img)
img = np.expand_dims(img, axis=0)
img = vgg16.preprocess_input(img)
return img
def deprocess_image(x):
# Remove zero-center by mean pixel
x[:, :, 0] += 103.939
x[:, :, 1] += 116.779
x[:, :, 2] += 123.68
# 'BGR'->'RGB'
x = x[:, :, ::-1]
x = np.clip(x, 0, 255).astype('uint8')
return xAs we would be writing custom loss functions and manipulation routines, we would need to define certain placeholders. Remember that keras is a high-level library that utilizes tensor manipulation backends (like tensorflow, theano, and CNTK) to perform the heavy lifting. Thus, these placeholders provide high-level abstractions to work with the underlying tensor object. The following snippet prepares placeholders for style, content, and generated images, along with the input tensor for the neural network:
from keras import backend as K
# This is the path to the image you want to transform.
TARGET_IMG = 'lotr.jpg'
# This is the path to the style image.
REFERENCE_STYLE_IMG = 'pattern1.jpg'
width, height = load_img(TARGET_IMG).size
img_height = 480
img_width = int(width * img_height / height)
target_image = K.constant(preprocess_image(TARGET_IMG,
height=img_height,
width=img_width))
style_image = K.constant(preprocess_image(REFERENCE_STYLE_IMG,
height=img_height,
width=img_width))
# Placeholder for our generated image
generated_image = K.placeholder((1, img_height, img_width, 3))
# Combine the 3 images into a single batch
input_tensor = K.concatenate([target_image,
style_image,
generated_image], axis=0)We will load the pre-trained VGG-16 model; that is, without the top fully-connected layers. The only difference here is that we would be providing the size dimensions of the input tensor for the model input. The following snippet helps us build the pre-trained model:
model = vgg16.VGG16(input_tensor=input_tensor,
weights='imagenet',
include_top=False)Building loss functions
In the Understanding neural style transfer section, we discussed that the problem with neural style transfer revolves around loss functions of content and style. In this section, we will define these loss functions.
Content loss
In any CNN-based model, activations from top layers contain more global and abstract information, and bottom layers will contain local information about the image. We would want to leverage the top layers of a CNN for capturing the right representations for the content of an image.
Hence, for the content loss, considering we will be using the pre-trained VGG-16 model, we can define our loss function as the L2 norm (scaled and squared Euclidean distance) between the activations of a top layer (giving feature representations) computed over the target image, and the activations of the same layer computed over the generated image. Assuming we usually get feature representations relevant to the content of images from the top layers of a CNN, the generated image is expected to look similar to the base target image.
The following snippet shows the function to compute the content loss:
def content_loss(base, combination):
return K.sum(K.square(combination - base))Style loss
As per the A Neural Algorithm of Artistic Style, by Gatys et al, we will be leveraging the Gram matrix and computing the same over the feature representations generated by the convolution layers. The Gram matrix computes the inner product between the feature maps produced in any given conv layer. The inner product’s terms are proportional to the co-variances of corresponding feature sets, and hence, captures patterns of correlations between the features of a layer that tends to activate together. These feature correlations help capture relevant aggregate statistics of the patterns of a particular spatial scale, which correspond to the style, texture, and appearance, and not the components and objects present in an image.
The style loss is thus defined as the scaled and squared Frobenius norm (Euclidean norm on a matrix) of the difference between the Gram matrices of the reference style and the generated images. Minimizing this loss helps ensure that the textures found at different spatial scales in the reference style image will be similar in the generated image. Thus, the following snippet defines a style loss function based on a Gram matrix calculation:
def style_loss(style, combination, height, width):
def build_gram_matrix(x):
features = K.batch_flatten(K.permute_dimensions(x, (2, 0, 1)))
gram_matrix = K.dot(features, K.transpose(features))
return gram_matrix
S = build_gram_matrix(style)
C = build_gram_matrix(combination)
channels = 3
size = height * width
return K.sum(K.square(S - C))/(4. * (channels ** 2) * (size ** 2))Total variation loss
It was observed that optimization to reduce only the style and content losses led to highly pixelated and noisy outputs. To cover the same, total variation loss was introduced. The total variation loss is analogous to regularization loss. This is introduced for ensuring spatial continuity and smoothness in the generated image to avoid noisy and overly pixelated results. The same is defined in the function as follows:
def total_variation_loss(x):
a = K.square(
x[:, :img_height - 1, :img_width - 1, :] - x[:, 1:, :img_width
- 1, :])
b = K.square(
x[:, :img_height - 1, :img_width - 1, :] - x[:, :img_height -
1, 1:, :])
return K.sum(K.pow(a + b, 1.25))Overall loss function
Having defined the components of the overall loss function for neural style transfer, the next step is to stitch together these building blocks. Since content and style information is captured by the CNNs at different depths in the network, we need to apply and calculate loss at appropriate layers for each type of loss. We will be taking the conv layers one to five for the style loss and setting appropriate weights for each layer.
Here is the code snippet to build the overall loss function:
# weights for the weighted average loss function
content_weight = 0.05
total_variation_weight = 1e-4
content_layer = 'block4_conv2'
style_layers = ['block1_conv2', 'block2_conv2',
'block3_conv3','block4_conv3', 'block5_conv3']
style_weights = [0.1, 0.15, 0.2, 0.25, 0.3]
# initialize total loss
loss = K.variable(0.)
# add content loss
layer_features = layers[content_layer]
target_image_features = layer_features[0, :, :, :]
combination_features = layer_features[2, :, :, :]
loss += content_weight * content_loss(target_image_features,
combination_features)
# add style loss
for layer_name, sw in zip(style_layers, style_weights):
layer_features = layers[layer_name]
style_reference_features = layer_features[1, :, :, :]
combination_features = layer_features[2, :, :, :]
sl = style_loss(style_reference_features, combination_features,
height=img_height, width=img_width)
loss += (sl*sw)
# add total variation loss
loss += total_variation_weight * total_variation_loss(generated_image)Constructing a custom optimizer
The objective is to iteratively minimize the overall loss with the help of an optimization algorithm. In the paper by Gatys et al., optimization was done using the L-BFGS algorithm, which is an optimization algorithm based on Quasi-Newton methods, which are popularly used for solving non-linear optimization problems and parameter estimation. This method usually converges faster than standard gradient descent.
We build an Evaluator class based on patterns, followed by keras creator François Chollet, to compute both loss and gradient values in one pass instead of independent and separate computations. This will return the loss value when called the first time and will cache the gradients for the next call. Thus, it would be more efficient than computing both independently. The following snippet defines the Evaluator class:
class Evaluator(object):
def __init__(self, height=None, width=None):
self.loss_value = None
self.grads_values = None
self.height = height
self.width = width
def loss(self, x):
assert self.loss_value is None
x = x.reshape((1, self.height, self.width, 3))
outs = fetch_loss_and_grads([x])
loss_value = outs[0]
grad_values = outs[1].flatten().astype('float64')
self.loss_value = loss_value
self.grad_values = grad_values
return self.loss_value
def grads(self, x):
assert self.loss_value is not None
grad_values = np.copy(self.grad_values)
self.loss_value = None
self.grad_values = None
return grad_values
evaluator = Evaluator(height=img_height, width=img_width)Style transfer in action
The final piece of the puzzle is to use all the building blocks and perform style transfer in action! The following snippet outlines how loss and gradients are evaluated. We also write back outputs after regular intervals/iterations (5, 10, and so on) to understand how the process of neural style transfer transforms the images in consideration after a certain number of iterations as depicted in the following snippet:
from scipy.optimize import fmin_l_bfgs_b
from scipy.misc import imsave
from imageio import imwrite
import time
result_prefix = 'st_res_'+TARGET_IMG.split('.')[0]
iterations = 20
# Run scipy-based optimization (L-BFGS) over the pixels of the
# generated image
# so as to minimize the neural style loss.
# This is our initial state: the target image.
# Note that `scipy.optimize.fmin_l_bfgs_b` can only process flat
# vectors.
x = preprocess_image(TARGET_IMG, height=img_height, width=img_width)
x = x.flatten()
for i in range(iterations):
print('Start of iteration', (i+1))
start_time = time.time()
x, min_val, info = fmin_l_bfgs_b(evaluator.loss, x,
fprime=evaluator.grads, maxfun=20)
print('Current loss value:', min_val)
if (i+1) % 5 == 0 or i == 0:
# Save current generated image only every 5 iterations
img = x.copy().reshape((img_height, img_width, 3))
img = deprocess_image(img)
fname = result_prefix + '_iter%d.png' %(i+1)
imwrite(fname, img)
print('Image saved as', fname)
end_time = time.time()
print('Iteration %d completed in %ds' % (i+1, end_time - start_time))It must be pretty evident by now that neural style transfer is a computationally expensive task. For the set of images in consideration, each iteration took between 500-1,000 seconds on an Intel i5 CPU with 8GB RAM (much faster on i7 or Xeon processors though!). The following code snippet shows the speedup we are getting using GPUs on a p2.x instance on AWS, where each iteration takes a mere 25 seconds! The following code snippet also shows the output of some of the iterations. We print the loss and time taken for each iteration, and save the generated image after every five iterations:
Start of iteration 1
Current loss value: 10028529000.0
Image saved as st_res_lotr_iter1.png
Iteration 1 completed in 28s
Start of iteration 2
Current loss value: 5671338500.0
Iteration 2 completed in 24s
Start of iteration 3
Current loss value: 4681865700.0
Iteration 3 completed in 25s
Start of iteration 4
Current loss value: 4249350400.0
.
.
.
Start of iteration 20
Current loss value: 3458219000.0
Image saved as st_res_lotr_iter20.png
Iteration 20 completed in 25sNow you’ll learn how the neural style transfer model has performed style transfer for the content images in consideration. Remember that we performed checkpoint outputs after certain iterations for every pair of style and content images. We utilize matplotlib and skimage to load and understand the style transfer magic performed by our system!
We have used the following image from the very popular Lord of the Rings movie as our content image, and a nice floral pattern-based artwork as our style image:

In the following code snippet, we are loading the generated styled images after various iterations:
from skimage import io
from glob import glob
from matplotlib import pyplot as plt
%matplotlib inline
content_image = io.imread('lotr.jpg')
style_image = io.imread('pattern1.jpg')
iter1 = io.imread('st_res_lotr_iter1.png')
iter5 = io.imread('st_res_lotr_iter5.png')
iter10 = io.imread('st_res_lotr_iter10.png')
iter15 = io.imread('st_res_lotr_iter15.png')
iter20 = io.imread('st_res_lotr_iter20.png')
fig = plt.figure(figsize = (15, 15))
ax1 = fig.add_subplot(6,3, 1)
ax1.imshow(content_image)
t1 = ax1.set_title('Original')
gen_images = [iter1,iter5, iter10, iter15, iter20]
for i, img in enumerate(gen_images):
ax1 = fig.add_subplot(6,3,i+1)
ax1.imshow(content_image)
t1 = ax1.set_title('Iteration {}'.format(i+5))
plt.tight_layout()
fig.subplots_adjust(top=0.95)
t = fig.suptitle('LOTR Scene after Style Transfer')Following is the output showcasing the original image and the generated styled images after every five iterations:

Following is the final styled image at a higher resolution. You can clearly see how the floral pattern textures and styles have slowly started propagating in the original Lord of the Rings movie image, giving it a nice vintage look:

This chapter presented a very novel technique in the deep learning landscape, leveraging the power of deep learning to create art! We covered the core concepts of neural style transfer, how to represent and formulate the problem using an effective loss function, and how to leverage the power of transfer learning and pretrained models like VGG-16 to extract the right feature representations.
If you found this post useful, do check out the book, Hands-On Transfer Learning with Python, which covers deep learning and transfer learning in detail. It also focuses on real-world examples and research problems using TensorFlow, Keras, and the Python ecosystem with hands-on examples.
Read Next
Generative Models in action: How to create a Van Gogh with Neural Artistic Style Transfer
OpenAI launches Spinning Up, a learning resource for potential deep learning practitioners









