









Machine learning experts are increasingly becoming interested in researching on how machine learning can be used to reduce greenhouse gas emissions and help society adapt to a changing climate. For example, Machine Learning can be used to regulate cloud data centres that manage an important asset, ‘Data’ as these data centres typically comprise tens to thousands of interconnected servers and consume a substantial amount of electrical energy.
Researchers from Huawei published a paper in April 2015, estimating that by 2030 data centres will use anywhere between 3% and 13% of global electricity
At the ICT4S 2019 conference held in Lappeenranta, Finland, from June 10-15, researchers from the University of Bristol, UK, introduced their research on a low carbon scheduling policy for the open-source Kubernetes container orchestrator. “Low Carbon Kubernetes Scheduler” can provide demand-side management (DSM) by migrating consumption of electric energy in cloud data centres to countries with the lowest carbon intensity of electricity.
In their paper the researchers highlight, “All major cloud computing companies acknowledge the need to run their data centres as efficiently as possible in order to address economic and environmental concerns, and recognize that ICT consumes an increasing amount of energy”.
Since the end of 2017, Google Cloud Platform runs its data centres entirely on renewable energy. Also, Microsoft has announced that its global operations have been carbon neutral since 2012. However, not all cloud providers have been able to make such an extensive commitment. For example, Oracle Cloud is currently 100% carbon neutral in Europe, but not in other regions.
The Kubernetes Scheduler selects compute nodes based on the real-time carbon intensity of the electric grid in the region they are in. Real-time APIs that report grid carbon intensity is available for an increasing number of regions, but not exhaustively around the planet. In order to effectively demonstrate the schedulers ability to perform global load balancing, the researchers have evaluated the scheduler based on its ability to the metric of solar irradiation.
“While much of the research on DSM focusses on domestic energy consumption there has also been work investigating DSM by cloud data centres”, the paper mentions. Demand side management (DSM) refers to any initiatives that affect how and when electricity is being required by consumers.
Source: CEUR-WS.org
Existing schedulers work with consideration to singular data centres rather than taking a more global view. On the other hand, the Low Carbon Scheduler considers carbon intensity across regions as scaling up and down of a large number of containers that can be done in a matter of seconds.
Each national electric grid contains electricity generated from a variable mix of alternative sources. The carbon intensity of the electricity provided by the grid anywhere in the world is a measure of the amount of greenhouse gas released into the atmosphere from the combustion of fossil fuels for the generation of electricity.
Significant generation sites report the volume of electricity input to the grid in regular intervals to the organizations operating the grid (for example the National Grid in the UK) in real-time via APIs. These APIs typically provide the retrieval of the production volumes and thus allow to calculate the carbon intensity in real-time. The Low carbon scheduler collects the carbon intensity from the available APIs and ranks them to identify the region with the lowest carbon intensity.
[box type=”shadow” align=”” class=”” width=””]For the European Union, such an API is provided by the European Network of Transmission System Operators for Electricity (www.entsoe.eu) and for the UK this is the Balancing Mechanism Reporting Service (www.elexon.co.uk).[/box]
Why Kubernetes for building a low carbon scheduler
Kubernetes can make use of GPUs4 and has also been ported to run on ARM architecture 5. Researchers have also said that Kubernetes has to a large extent won the container orchestration war. It also has support for extendability and plugins which makes it the “most suitable for which to develop a global scheduler and bring about the widest adoption, thereby producing the greatest impact on carbon emission reduction”.
Kubernetes allows schedulers to run in parallel, which means the scheduler will not need to re-implement the pre-existing, and sophisticated, bin-packing strategies present in Kubernetes. It need only to apply a scheduling layer to complement the existing capabilities proffered by Kubernetes. According to the researchers, “Our design, as it operates at a higher level of abstraction, assures that Kubernetes continues to deal with bin-packing at the node level, while the scheduler performs global-level scheduling between data centres”.
The official Kubernetes documentation describes three possible ways of extending the default scheduler (kube-scheduler):
- adding these rules to the scheduler source code and recompiling,
- implementing one’s own scheduler process that runs instead of, or alongside kube-scheduler, or
- implementing a scheduler extender.
Evaluating the performance of the low carbon Kubernetes scheduler
The researchers recorded the carbon intensities for the countries that the major cloud providers operate data centers between 18.2.2019 13:00 UTC and 21.4.2019 9:00 UTC. Following is a table showing countries where the largest public cloud providers operate data centers, as of April 2019.
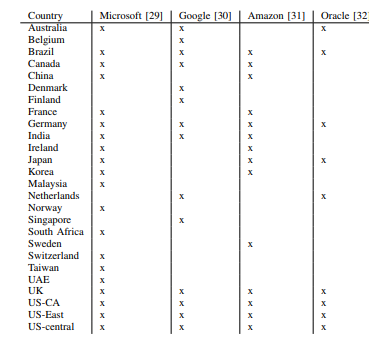
Source: CEUR-WS.org
They further ranked all countries by the carbon intensity of their electricity in 30-minute intervals. Among the total set of 30-minute values, Switzerland had the lowest carbon intensity (ranked first) in 0.57% of the 30-minute intervals, Norway 0.31%, France 0.11% and Sweden in 0.01%.
However, the list of the least carbon intense countries only contains countries in central Europe locations. To justify Kubernetes’ ability or globally distributed deployments the researchers chose to optimize placement to regions with the greatest degree of solar irradiance termed a Heliotropic Scheduler.
This scheduler is termed ‘heliotropic’ in order to differentiate it from a ‘follow-the-sun’ application management policy that relates to meeting customer demand around the world by placing staff and resources in proximity to those locations (thereby making them available to clients at lower latency and at a suitable time of day). A ‘heliotropic’ policy, on the other hand, goes to where sunlight, and by extension solar irradiance, is abundant. They further evaluated the Heliotropic Scheduler implementation by running BOINC jobs on Kubernetes.
BOINC (Berkeley Open Infrastructure for Network Computing) is a software platform for volunteer computing that allows users to contribute computational capacity from their home PCs towards scientific research. Einstein@Home, SETI@home and IBM World Community Grid are some of the most widely supported projects.
Researchers say:
“Even though many cloud providers are contracting for renewable energy with their energy providers, the electricity these data centres take from the grid is generated with release of a varying amount of greenhouse gas emissions into the atmosphere. Our scheduler can contribute to moving demand for more carbon intense electricity to less carbon intense electricity”.
While the paper concludes that wind-dominant, solar-complementary strategy is superior for the integration of renewable energy sources into cloud data centres’ infrastructure, the Low Carbon Scheduler provides a proof-of-concept demonstrating how to reduce carbon intensity in cloud computing.
To know more about this implementation for lowering carbon emissions read the research paper.