









A formal definition of machine learning proposed by computer scientist Tom M. Mitchell states that a machine learns whenever it is able to utilize an experience such that its performance improves on similar experiences in the future. Although this definition is intuitive, it completely ignores the process of exactly how experience can be translated into future action—and of course, learning is always easier said than done!
While human brains are naturally capable of learning from birth, the conditions necessary for computers to learn must be made explicit. For this reason, although it is not strictly necessary to understand the theoretical basis of learning, this foundation helps to understand, distinguish, and implement machine learning algorithms.
This article is taken from the book Machine learning with R – Second Edition, written by Brett Lantz.
Regardless of whether the learner is a human or machine, the basic learning process is similar. It can be divided into four interrelated components:
- Data storage utilizes observation, memory, and recall to provide a factual basis for further reasoning.
- Abstraction involves the translation of stored data into broader representations and concepts.
- Generalization uses abstracted data to create knowledge and inferences that drive action in new contexts.
- Evaluation provides a feedback mechanism to measure the utility of learned knowledge and inform potential improvements.
The following figure illustrates the steps in the learning process:
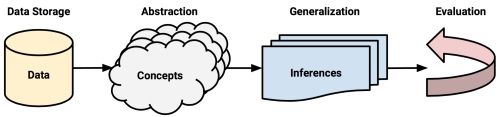
Keep in mind that although the learning process has been conceptualized as four distinct components, they are merely organized this way for illustrative purposes. In reality, the entire learning process is inextricably linked. In human beings, the process occurs subconsciously. We recollect, deduce, induct, and intuit with the confines of our mind’s eye, and because this process is hidden, any differences from person to person are attributed to a vague notion of subjectivity. In contrast, with computers these processes are explicit, and because the entire process is transparent, the learned knowledge can be examined, transferred, and utilized for future action.
Data storage for advanced reasoning
All learning must begin with data. Humans and computers alike utilize data storage as a foundation for more advanced reasoning. In a human being, this consists of a brain that uses electrochemical signals in a network of biological cells to store and process observations for short- and long-term future recall. Computers have similar capabilities of short- and long-term recall using hard disk drives, flash memory, and random access memory (RAM) in combination with a central processing unit (CPU).
It may seem obvious to say so, but the ability to store and retrieve data alone is not sufficient for learning. Without a higher level of understanding, knowledge is limited exclusively to recall, meaning exclusively what is seen before and nothing else. The data is merely ones and zeros on a disk. They are stored memories with no broader meaning.
To better understand the nuances of this idea, it may help to think about the last time you studied for a difficult test, perhaps for a university final exam or a career certification. Did you wish for an eidetic (photographic) memory? If so, you may be disappointed to learn that perfect recall is unlikely to be of much assistance. Even if you could memorize material perfectly, your rote learning is of no use, unless you know in advance the exact questions and answers that will appear in the exam. Otherwise, you would be stuck in an attempt to memorize answers to every question that could conceivably be asked. Obviously, this is an unsustainable strategy.
Instead, a better approach is to spend time selectively, memorizing a small set of representative ideas while developing strategies on how the ideas relate and how to use the stored information. In this way, large ideas can be understood without needing to memorize them by rote.
Abstraction of stored data
This work of assigning meaning to stored data occurs during the abstraction process, in which raw data comes to have a more abstract meaning. This type of connection, say between an object and its representation, is exemplified by the famous René Magritte painting The Treachery of Images:

Source: http://collections.lacma.org/node/239578
The painting depicts a tobacco pipe with the caption Ceci n’est pas une pipe (“this is not a pipe”). The point Magritte was illustrating is that a representation of a pipe is not truly a pipe. Yet, in spite of the fact that the pipe is not real, anybody viewing the painting easily recognizes it as a pipe. This suggests that the observer’s mind is able to connect the picture of a pipe to the idea of a pipe, to a memory of a physical pipe that could be held in the hand. Abstracted connections like these are the basis of knowledge representation, the formation of logical structures that assist in turning raw sensory information into a meaningful insight.
During a machine’s process of knowledge representation, the computer summarizes stored raw data using a model, an explicit description of the patterns within the data. Just like Magritte’s pipe, the model representation takes on a life beyond the raw data. It represents an idea greater than the sum of its parts.
There are many different types of models. You may be already familiar with some. Examples include:
- Mathematical equations
- Relational diagrams such as trees and graphs
- Logical if/else rules
- Groupings of data known as clusters
The choice of model is typically not left up to the machine. Instead, the learning task and data on hand inform model selection.
The process of fitting a model to a dataset is known as training. When the model has been trained, the data is transformed into an abstract form that summarizes the original information.
It is important to note that a learned model does not itself provide new data, yet it does result in new knowledge. How can this be? The answer is that imposing an assumed structure on the underlying data gives insight into the unseen by supposing a concept about how data elements are related. Take for instance the discovery of gravity. By fitting equations to observational data, Sir Isaac Newton inferred the concept of gravity. But the force we now know as gravity was always present. It simply wasn’t recognized until Newton recognized it as an abstract concept that relates some data to others—specifically, by becoming the g term in a model that explains observations of falling objects.
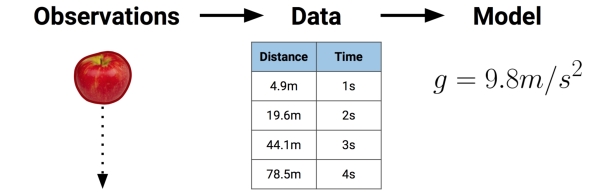
Most models may not result in the development of theories that shake up scientific thought for centuries. Still, your model might result in the discovery of previously unseen relationships among data. A model trained on genomic data might find several genes that, when combined, are responsible for the onset of diabetes; banks might discover a seemingly innocuous type of transaction that systematically appears prior to fraudulent activity; and psychologists might identify a combination of personality characteristics indicating a new disorder. These underlying patterns were always present, but by simply presenting information in a different format, a new idea is conceptualized.
Generalization for future action
The learning process is not complete until the learner is able to use its abstracted knowledge for future action. However, among the countless underlying patterns that might be identified during the abstraction process and the myriad ways to model these patterns, some will be more useful than others. Unless the production of abstractions is limited, the learner will be unable to proceed. It would be stuck where it started—with a large pool of information, but no actionable insight.
The term generalization describes the process of turning abstracted knowledge into a form that can be utilized for future action, on tasks that are similar, but not identical, to those it has seen before. Generalization is a somewhat vague process that is a bit difficult to describe. Traditionally, it has been imagined as a search through the entire set of models (that is, theories or inferences) that could be abstracted during training. In other words, if you can imagine a hypothetical set containing every possible theory that could be established from the data, generalization involves the reduction of this set into a manageable number of important findings.
In generalization, the learner is tasked with limiting the patterns it discovers to only those that will be most relevant to its future tasks. Generally, it is not feasible to reduce the number of patterns by examining them one-by-one and ranking them by future utility. Instead, machine learning algorithms generally employ shortcuts that reduce the search space more quickly. Toward this end, the algorithm will employ heuristics, which are educated guesses about where to find the most useful inferences.
Heuristics are routinely used by human beings to quickly generalize experience to new scenarios. If you have ever utilized your gut instinct to make a snap decision prior to fully evaluating your circumstances, you were intuitively using mental heuristics.
The incredible human ability to make quick decisions often relies not on computer-like logic, but rather on heuristics guided by emotions. Sometimes, this can result in illogical conclusions. For example, more people express fear of airline travel versus automobile travel, despite automobiles being statistically more dangerous. This can be explained by the availability heuristic, which is the tendency of people to estimate the likelihood of an event by how easily its examples can be recalled. Accidents involving air travel are highly publicized. Being traumatic events, they are likely to be recalled very easily, whereas car accidents barely warrant a mention in the newspaper.
The folly of misapplied heuristics is not limited to human beings. The heuristics employed by machine learning algorithms also sometimes result in erroneous conclusions. The algorithm is said to have a bias if the conclusions are systematically erroneous, or wrong in a predictable manner.
For example, suppose that a machine learning algorithm learned to identify faces by finding two dark circles representing eyes, positioned above a straight line indicating a mouth. The algorithm might then have trouble with, or be biased against, faces that do not conform to its model. Faces with glasses, turned at an angle, looking sideways, or with various skin tones might not be detected by the algorithm. Similarly, it could be biased toward faces with certain skin tones, face shapes, or other characteristics that do not conform to its understanding of the world.
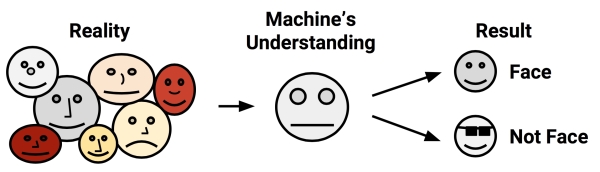
In modern usage, the word bias has come to carry quite negative connotations. Various forms of media frequently claim to be free from bias, and claim to report the facts objectively, untainted by emotion. Still, consider for a moment the possibility that a little bias might be useful. Without a bit of arbitrariness, might it be a bit difficult to decide among several competing choices, each with distinct strengths and weaknesses? Indeed, some recent studies in the field of psychology have suggested that individuals born with damage to portions of the brain responsible for emotion are ineffectual in decision making, and might spend hours debating simple decisions such as what color shirt to wear or where to eat lunch. Paradoxically, bias is what blinds us from some information while also allowing us to utilize other information for action. It is how machine learning algorithms choose among the countless ways to understand a set of data.
Evaluate the learner’s success
Bias is a necessary evil associated with the abstraction and generalization processes inherent in any learning task. In order to drive action in the face of limitless possibility, each learner must be biased in a particular way. Consequently, each learner has its weaknesses and there is no single learning algorithm to rule them all. Therefore, the final step in the generalization process is to evaluate or measure the learner’s success in spite of its biases and use this information to inform additional training if needed.
Generally, evaluation occurs after a model has been trained on an initial training dataset. Then, the model is evaluated on a new test dataset in order to judge how well its characterization of the training data generalizes to new, unseen data. It’s worth noting that it is exceedingly rare for a model to perfectly generalize to every unforeseen case.
In parts, models fail to perfectly generalize due to the problem of noise, a term that describes unexplained or unexplainable variations in data. Noisy data is caused by seemingly random events, such as:
- Measurement error due to imprecise sensors that sometimes add or subtract a bit from the readings
- Issues with human subjects, such as survey respondents reporting random answers to survey questions, in order to finish more quickly
- Data quality problems, including missing, null, truncated, incorrectly coded, or corrupted values
- Phenomena that are so complex or so little understood that they impact the data in ways that appear to be unsystematic
Trying to model noise is the basis of a problem called overfitting. Because most noisy data is unexplainable by definition, attempting to explain the noise will result in erroneous conclusions that do not generalize well to new cases. Efforts to explain the noise will also typically result in more complex models that will miss the true pattern that the learner tries to identify. A model that seems to perform well during training, but does poorly during evaluation, is said to be overfitted to the training dataset, as it does not generalize well to the test dataset.
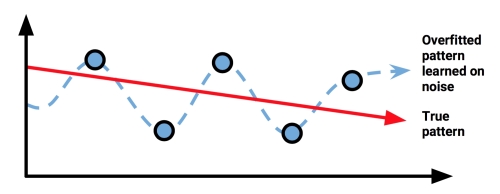
Solutions to the problem of overfitting are specific to particular machine learning approaches. For now, the important point is to be aware of the issue. How well the models are able to handle noisy data is an important source of distinction among them.
We saw that machine learning process is similar to how humans learn in their daily lives.To
To discover how to build machine learning algorithms, prepare data, and dig deep into data prediction techniques with R, check out this book Machine learning with R – Second edition.
Read Next:
A Machine learning roadmap for Web Developers
Why TensorFlow always tops machine learning and artificial intelligence tool surveys
Intelligent Edge Analytics: 7 ways machine learning is driving edge computing adoption in 2018




