









In this article by Siddhartha Chatterjee and Michal Krystyanczuk, author of the book, Python Social Media Analytics, starts with a question to you: Have you seen the movie Social Network? If you have not, it could be a good idea to see it before you read this. If you have, you may have seen the success story around Mark Zuckerberg and his company Facebook. This was possible due to power of the platform in connecting, enabling, sharing, and impacting the lives of almost two billion people on this planet.
The earliest Social Networks existed as far back as 1995; such as Yahoo (Geocities), theglobe.com, and tripod.com. These platforms were mainly to facilitate interaction among people through chat rooms. It was only at the end of the 90s that user profiles became the in thing in social networking platforms, allowing information about people to be discoverable, and therefore, providing a choice to make friends or not. Those embracing this new methodology were Makeoutclub, Friendster, SixDegrees.com, and so on.
MySpace, LinkedIn, and Orkut were thereafter created, and the social networks were on the verge of becoming mainstream. However, the biggest impact happened with the creation of Facebook in 2004; a total game changer for people’s lives, business, and the world. The sophistication and the ease of using the platform made it into mainstream media for individuals and companies to advertise and sell their ideas and products. Hence, we are in the age of social media that has changed the way the world functions.
Since the last few years, there have been new entrants in the social media, which are essentially of different interaction models as compared to Facebook, LinkedIn, or Twitter. These are Pinterest, Instagram, Tinder, and others. Interesting example is Pinterest, which unlike Facebook, is not centered around people but is centered around interests and/or topics. It’s essentially able to structure people based on their interest around these topics. CEO of Pinterest describes it as a catalog of ideas. Forums which are not considered as regular social networks, such as Facebook, Twitter, and others, are also very important social platforms. Unlike in Twitter or Facebook, Forum users are often anonymous in nature, which enables them to make in-depth conversations with communities. Other non-typical social networks are video sharing platforms, such as YouTube and Dailymotion. They are non-typical because they are centered around the user-generated content, and the social nature is generated by the sharing of these content on various social networks and also the discussion it generates around the user commentaries. Social media is gradually changing from platform centric to more experiences and features. In the future, we’ll see more and more traditional content providers and services becoming social in nature through sharing and conversations. The term social media today includes not just social networks but every service that’s social in nature with a wide audience.
Delving into Social Data
The data acquired from social media is called social data. The social data exists in many forms.
The types of social media data can be information around the users of social networks, like name, city, interests, and so on. These types of data that are numeric or quantifiable are known as structured data.
However, since Social Media are platforms for expression, hence, a lot of the data is in the form of texts, images, videos, and such. These sources are rich in information, but not as direct to analyze as structured data described earlier. These types of data are known as unstructured data.
The process of applying rigorous methods to make sense of the social data is called social data analytics. We will go into great depth in social data analytics to demonstrate how we can extract valuable sense and information from these really interesting sources of social data. Since there are almost no restrictions on social media, there are lot of meaningless accounts, content, and interactions. So, the data coming out of these streams is quite noisy and polluted. Hence, a lot of effort is required to separate the information from the noise. Once the data is cleaned and we are focused on the most important and interesting aspects, we then require various statistical and algorithmic methods to make sense out of the filtered data and draw meaningful conclusions.
Understanding the process
Once you are familiar with the topic of social media data, let us proceed to the next phase. The first step is to understand the process involved in exploitation of data present on social networks. A proper execution of the process, with attention to small details, is the key to good results. In many computer science domains, a small error in code will lead to a visible or at least correctable dysfunction, but in data science, it will produce entirely wrong results, which in turn will lead to incorrect conclusions.
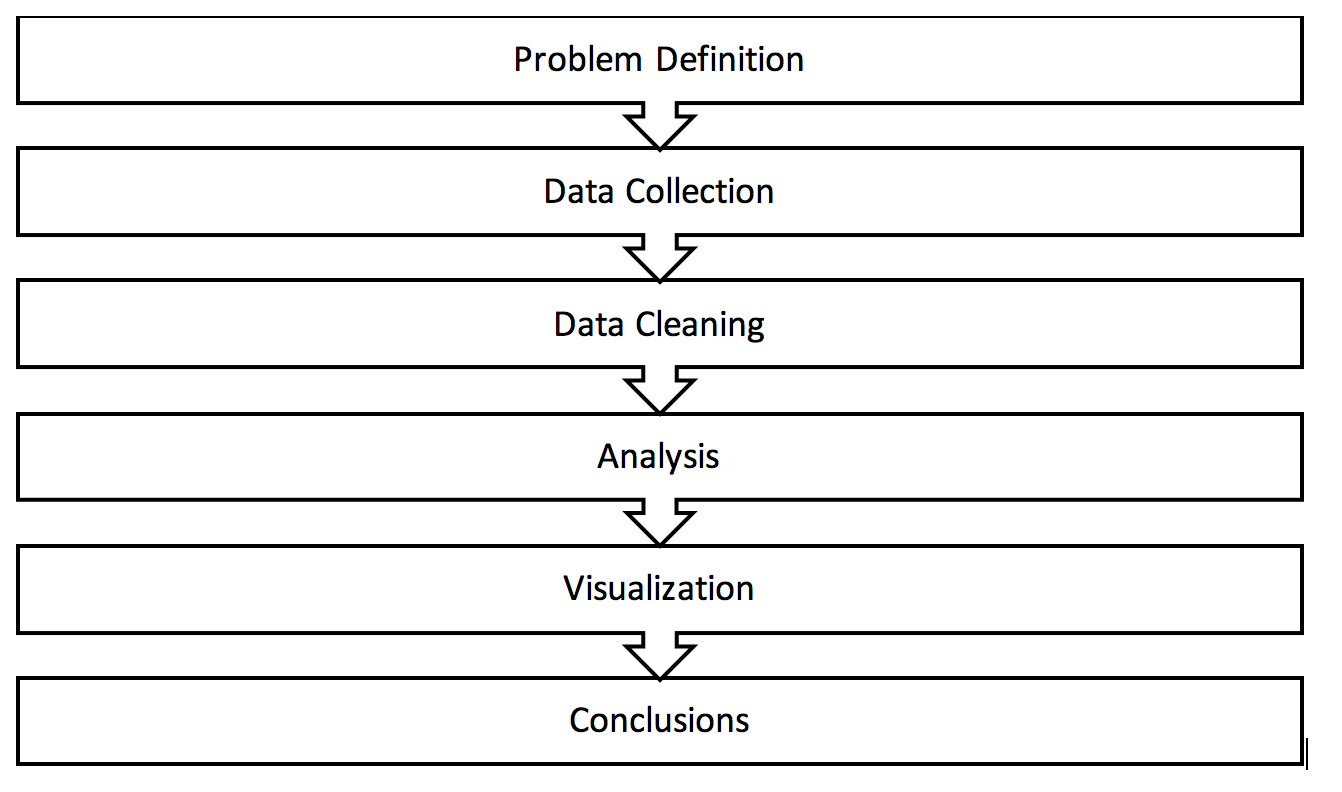
The very first step of data analysis is always problem definition. Understanding the problem is crucial for choosing the right data sources and the methods of analysis. It also helps to realize what kind of information and conclusions we can infer from the data and what is impossible to derive. This part is very often underestimated while it is key to successful data analysis.
Any question that we try to answer in a data science project has to be very precise. Some people tend to ask very generic questions, such as I want to find trends on Twitter. This is not a correct problem definition and an analysis based on such statement can fail in finding relevant trends. By a naïve analysis, we can get repeating Twitter ads and content generated by bots. Moreover, it raises more questions than it answers. In order to approach the problem correctly, we have to ask in the first step: what is a trend? what is an interesting trend for us? and what is the time scope? Once we answer these questions, we can break up the problem in multiple sub problems: I’m looking for the most frequent consumer reactions about my brand on Twitter in English over the last week and I want to know if they were positive or negative. Such a problem definition will lead to a relevant, valuable analysis with insightful conclusions.
The next part of the process consists of getting the right data according to the defined problem. Many social media platforms allow users to collect a lot of information in an automatized way via APIs (Application Programming Interfaces), which is the easiest way to complete the task.
Once the data is stored in a database, we perform the cleaning. This step requires a precise understanding of the project’s goals. In many cases, it will involve very basic tasks such as duplicates removal, for example, retweets on Twitter, or more sophisticated such as spam detection to remove irrelevant comments, language detection to perform linguistic analysis, or other statistical or machine learning approaches that can help to produce a clean dataset.
When the data is ready to be analyzed, we have to choose what kind of analysis and structure the data accordingly. If our goal is to understand the sense of the conversations, then it only requires a simple list of verbatims (textual data), but if we aim to perform analysis on different variables, like number of likes, dates, number of shares, and so on, the data should be combined in a structure such as data frame, where each row corresponds to an observation and each column to a variable.
The choice of the analysis method depends on the objectives of the study and the type of data. It may require statistical or machine learning approach, or a specific approach to time series. Different approaches will be explained on the examples of Facebook, Twitter, YouTube, GitHub, Pinterest, and Forum data.
Once the analysis is done, it’s time to infer conclusions. We can derive conclusions based on the outputs from the models, but one of the most useful tools is visualization technique. Data and output can be presented in many different ways, starting from charts, plots, and diagrams through more complex 2D charts, to multidimensional visualizations.
Project planning
Analysis of content on social media can get very confusing due to difficulty of working on large amount of data and also trying to make sense out of it. For this reason, it’s extremely important to ask the right questions in the beginning to get the right answers. Even though this is an exploratory approach, and getting exact answers may be difficult, the right questions allow you to define the scope, process and the time.
The main questions that we will be working on are the following :
- What does Google post on Facebook ?
- How do people react to Google Posts ? (Likes, Shares and Comments)
- What do Google’s audience say about Google and its ecosystem?
- What are the emotions expressed by Google’s audience ?
With the preceding questions in mind we will proceed to the next steps.
Scope and process
The analysis will consist of analyzing the feed of posts and comments on official Facebook page of Google.
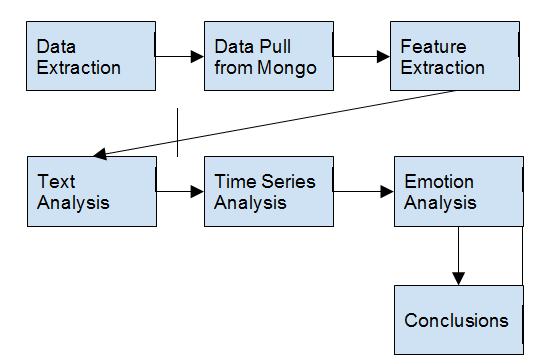
The process of information extraction is organized in a data flow. It starts with data extraction from API, data preprocessing and wrangling and is followed by a series of different analyses.
The analysis becomes actionable only after the last step of results interpretation.
In order to arrive at retrieving the above information we need to do the following :
- Extract all the posts of Google permitted by the Facebook API
- Extract the metadata for each posts : TimeStamp, Number of Likes, Number of Shares, Number of comments.
- Extract the user comments under each post and the metadata
- Process the posts to retrieve the most common keywords, bi-grams, hashtags
- Process the user comments using Alchemy API to retrieve the emotions
- Analyse the above information to derive conclusions
Data type
The main part of information extraction comes from an analysis of textual data (posts and comments). However, in order to add quantitative and temporal dimension, we process numbers (likes, shares) and dates (date of creation).
Summary
The avalanche of Social Network data is a result of communication platforms been developed since the last two decades. These are the platforms that evolved from chat rooms to personal information sharing and finally, social and professional networks. Among many Facebook, Twitter, Instagram, Pinterest and LinkedIn have emerged as the modern day Social Media. These platforms collectively have reach of more than a billon or more of individuals across the world sharing their activities and interaction with each other. Sharing of their data by these media through APIs and other technologies has given rise to a new field called Social Media Analytics. This has multiple applications such as in Marketing, Personalized recommendations, Research and Societal. Modern Data Science techniques such as Machine Learning and Text Mining are widely used for these applications. Python is one of the most widely used programming languages used for these techniques. However, manipulating the unstructured-data from Social Networks requires a lot of precise processing and preparation before coming to the most interesting bits.
Resources for Article:
Further resources on this subject:
- How to integrate social media with your WordPress website [article]
- Social Media for WordPress: VIP Memberships [article]
- Social Media Insight Using Naive Bayes [article]