









Weld is an open-source Rust project for improving the performance of data-intensive applications. It is an interface and runtime that can be integrated into existing frameworks including Spark, TensorFlow, Pandas, and NumPy without changing their user-facing APIs.
The motivation behind Weld
Data analytics applications today often require developers to combine various functions from different libraries and frameworks to accomplish a particular task. For instance, a typical Python ecosystem application selects some data using Spark SQL, transforms it using NumPy and Pandas, and trains a model with TensorFlow.
This improves developers’ productivity as they are taking advantage of functions from high-quality libraries. However, these functions are usually optimized in isolation, which is not enough to achieve the best application performance.
Weld aims to solve this problem by providing an interface and runtime that can optimize across data-intensive libraries and frameworks while preserving their user-facing APIs. In an interview with Federico Carrone, a Tech Lead at LambdaClass, Weld’s main contributor, Shoumik Palkar shared, “The motivation behind Weld is to provide bare-metal performance for applications that rely on existing high-level APIs such as NumPy and Pandas. The main problem it solves is enabling cross-function and cross-library optimizations that other libraries today don’t provide.”
How Weld works
Weld serves as a common runtime that allows libraries from different domains like SQL and machine learning to represent their computations in a common functional intermediate representation (IR). This IR is then optimized by a compiler optimizer and JIT’d to efficient machine code for diverse parallel hardware. It performs a wide range of optimizations on the IR including loop fusion, loop tiling, and vectorization. “Weld’s IR is natively parallel, so programs expressed in it can always be trivially parallelized,” said Palkar.
When Weld was first introduced it was mainly used for cross-library optimizations. However, over time people have started to use it for other applications as well. It can be used to build JITs or new physical execution engines for databases or analytics frameworks, individual libraries, target new kinds of parallel hardware using the IR, and more.
To evaluate Weld’s performance the team integrated it with popular data analytics frameworks including Spark, NumPy, and TensorFlow. This prototype showed up to 30x improvements over the native framework implementations. While cross library optimizations between Pandas and NumPy also improved performance by up to two orders of magnitude.
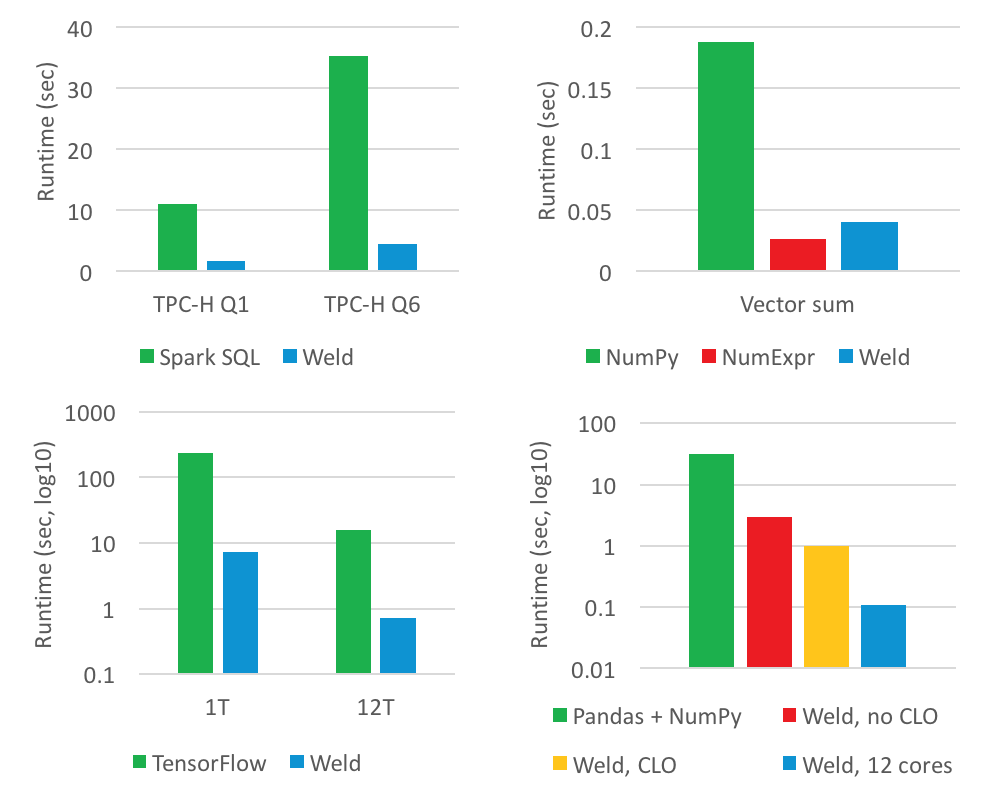
Source: Weld
Why Rust and LLVM were chosen for its implementation
The first iteration of Weld was implemented in Scala because of its algebraic data types, powerful pattern matching, and large ecosystem. However, it did have some shortcomings. Palkar shared in the interview, “We moved away from Scala because it was too difficult to embed a JVM-based language into other runtimes and languages.” It had a managed runtime, clunky build system, and its JIT compilations were quite slow for larger programs.
Because of these shortcomings the team wanted to redesign the JIT compiler, core API, and runtime from the ground up. They were in the search for a language that was fast, safe, didn’t have a managed runtime, provided a rich standard library, functional paradigms, good package manager, and great community background. So, they zeroed-in on Rust that happens to meet all these requirements.
Rust provides a very minimal, no setup required runtime. It can be easily embedded into other languages such as Java and Python. To make development easier, it has high-quality packages, known as crates, and functional paradigms such as pattern matching. Lastly, it is backed by a great Rust Community.
Explaining the reason why they chose LLVM, Palkar said in the interview, “We chose LLVM because its an open-source compiler framework that has wide use and support; we generate LLVM directly instead of C/C++ so we don’t need to rely on the existence of a C compiler, and because it improves compilation times (we don’t need to parse C/C++ code).”
In a discussion on Hacker News many users listed other Weld-like projects that developers may find useful. A user commented, “Also worth checking out OmniSci (formerly MapD), which features an LLVM query compiler to gain large speedups executing SQL on both CPU and GPU.”
Users also talked about Numba, an open-source JIT compiler that translates Python functions to optimized machine code at runtime with the help of the LLVM compiler library. “Very bizarre there is no discussion of numba here, which has been around and used widely for many years, achieves faster speedups than this, and also emits an LLVM IR that is likely a much better starting point for developing a “universal” scientific computing IR than doing yet another thing that further complicates it with fairly needless involvement of Rust,” a user added.
To know more about Weld, check out the full interview on Medium. Also, watch this RustConf 2019 talk by Shoumik Palkar:
Other news in Programming
Darklang available in private beta
GNU community announces ‘Parallel GCC’ for parallelism in real-world compilers
TextMate 2.0, the text editor for macOS releases


