Yesterday, the team at Explosion announced a new version of the Natural Language Processing library, spaCy v2.2, highlighting that this version is much leaner, cleaner and even more user-friendly.
spaCy v2.2 includes new model packages and features for training, evaluation, and serialization. This version also includes a lot many bug fixes, improved debugging and error handling, and greatly reduced the size of the library on disk.
What’s new in spaCy v2.2
Added more languages and improvements in existing pretrained models
This spaCy version introduces pretrained models for two additional languages: Norwegian and Lithuanian. The accuracy of both these languages is likely to improve in subsequent releases, as the current models make use of neither pretrained word vectors nor the spacy pretrain command. The team looks forward to adding more languages soon.
The pretrained Dutch NER model now includes a new dataset making it much more useful. The new dataset provides OntoNotes 5 annotations over the LaSSy corpus. This allows the researchers to replace the semi-automatic Wikipedia NER model with one trained on gold-standard entities of 20 categories.
Source: explosion.ai
New CLI features for training
spaCy v2.2 now includes various usability improvements to the training and data development workflow, especially for text categorization. The developers have made improvements in the error messages, updated the documentation, and made the evaluation metrics more detailed – for example, the evaluation now provides per-entity-type and per-text-category accuracy statistics by default.
To make training even easier, the developers have also introduced a new debug-data command, to validate user training and development data, get useful stats, and find problems like invalid entity annotations, cyclic dependencies, low data labels and more.
Reduced disk foot-print and improvements in language resource handling
As spaCy has supported more languages, the disk footprint has crept steadily upwards, especially when support was added for lookup-based lemmatization tables. These tables were stored as Python files, and in some cases became quite large. The spaCy team has switched these lookup tables over to gzipped JSON and moved them out to a separate package, spacy-lookups-data, that can be installed alongside spaCy if needed. Depending on the system, your spaCy installation should now be 5-10× smaller.
Also, large language resources are now powered by a consistent LookupsAPI that you can also take advantage of when writing custom components. Custom components often need lookup tables that are available to the Doc, Token or Spanobjects. The natural place for this is in the shared Vocab. Now custom components can place data there too, using the new lookups API.
New DocBin class to efficiently serialize Doc collections
The new DocBin class makes it easy to serialize and deserialize a collection of Doc objects together and is much more efficient than calling Doc.to_bytes on each individual Doc object. You can also control what data gets saved, and you can merge pallets together for easy map/reduce-style processing.
Up to 10 times faster phrase matching
spaCy’s previous PhraseMatcher algorithm could easily scale to large query sets. However, it wasn't necessarily that fast when fewer queries were used – making its performance characteristics a bit unintuitive. The spaCy v2.2 replaces the PhraseMatcher with a more straight-forward trie-based algorithm. Because the search is performed over tokens instead of characters, matching is very fast – even before the implementation was optimized using Cython data structures. When a few queries are used, the new implementation is almost 20× faster – and it's still almost 5× faster when 10,000 queries are used.
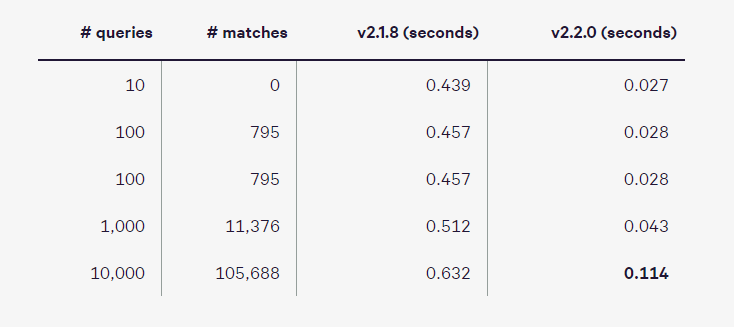
Benchmarks for searching over 10,000 Wikipedia articles
Source: explosion.ai
Few bug fixes in spaCy v2.2
- Reduced package size on disk by moving and compressing large dictionaries.
Unlock access to the largest independent learning library in Tech for FREE!
Get unlimited access to 7500+ expert-authored eBooks and video courses covering every tech area you can think of.
Renews at $19.99/month. Cancel anytime
- Updated lemma and vector information after splitting a token.
- This version automatically skips duplicates in Doc.retokenize.
- Allows customizing entity HTML template in displaCy.
- Ensures training doesn't crash with empty batches.
To know about the other bug fixes in detail, read the release notes on GitHub
Many are excited to try the new version of SpaCy. A user on Hacker News commented, “Nice! I'm excited! I've been working on a heavy NLP project with Spanish and been having some issues and so this will be nice to test out and see if it helps!”
To know more about spaCy v2.2 in detail, read the official post.
Dr Joshua Eckroth on performing Sentiment Analysis on social media platforms using CoreNLP
Generating automated image captions using NLP and computer vision [Tutorial]
Facebook open-sources PyText, a PyTorch based NLP modeling framework

 United States
United States
 Great Britain
Great Britain
 India
India
 Germany
Germany
 France
France
 Canada
Canada
 Russia
Russia
 Spain
Spain
 Brazil
Brazil
 Australia
Australia
 Singapore
Singapore
 Canary Islands
Canary Islands
 Hungary
Hungary
 Ukraine
Ukraine
 Luxembourg
Luxembourg
 Estonia
Estonia
 Lithuania
Lithuania
 South Korea
South Korea
 Turkey
Turkey
 Switzerland
Switzerland
 Colombia
Colombia
 Taiwan
Taiwan
 Chile
Chile
 Norway
Norway
 Ecuador
Ecuador
 Indonesia
Indonesia
 New Zealand
New Zealand
 Cyprus
Cyprus
 Denmark
Denmark
 Finland
Finland
 Poland
Poland
 Malta
Malta
 Czechia
Czechia
 Austria
Austria
 Sweden
Sweden
 Italy
Italy
 Egypt
Egypt
 Belgium
Belgium
 Portugal
Portugal
 Slovenia
Slovenia
 Ireland
Ireland
 Romania
Romania
 Greece
Greece
 Argentina
Argentina
 Netherlands
Netherlands
 Bulgaria
Bulgaria
 Latvia
Latvia
 South Africa
South Africa
 Malaysia
Malaysia
 Japan
Japan
 Slovakia
Slovakia
 Philippines
Philippines
 Mexico
Mexico
 Thailand
Thailand














