In this article by Hans-Jürgen Schönig, author of the book PostgreSQL Administration Essentials, you will be guided through PostgreSQL indexing, and you will learn how to fix performance issues and find performance bottlenecks. Understanding indexing will be vital to your success as a DBA—you cannot count on software engineers to get this right straightaway. It will be you, the DBA, who will face problems caused by bad indexing in the field. For the sake of your beloved sleep at night, this article is about PostgreSQL indexing.
(For more resources related to this topic, see here.)
Using simple binary trees
In this section, you will learn about simple binary trees and how the PostgreSQL optimizer treats the trees. Once you understand the basic decisions taken by the optimizer, you can move on to more complex index types.
Preparing the data
Indexing does not change user experience too much, unless you have a reasonable amount of data in your database—the more data you have, the more indexing can help to boost things. Therefore, we have to create some simple sets of data to get us started. Here is a simple way to populate a table:
test=# CREATE TABLE t_test (id serial, name text); CREATE TABLE test=# INSERT INTO t_test (name) SELECT 'hans' FROM generate_series(1, 2000000); INSERT 0 2000000 test=# INSERT INTO t_test (name) SELECT 'paul' FROM generate_series(1, 2000000); INSERT 0 2000000
In our example, we created a table consisting of two columns. The first column is simply an automatically created integer value. The second column contains the name.
Once the table is created, we start to populate it. It's nice and easy to generate a set of numbers using the generate_series function. In our example, we simply generate two million numbers. Note that these numbers will not be put into the table; we will still fetch the numbers from the sequence using generate_series to create two million hans and rows featuring paul, shown as follows:
test=# SELECT * FROM t_test LIMIT 3; id | name ----+------ 1 | hans 2 | hans 3 | hans (3 rows)
Once we create a sufficient amount of data, we can run a simple test. The goal is to simply count the rows we have inserted. The main issue here is: how can we find out how long it takes to execute this type of query? The timing command will do the job for you:
test=# timing Timing is on.
As you can see, timing will add the total runtime to the result. This makes it quite easy for you to see if a query turns out to be a problem or not:
test=# SELECT count(*) FROM t_test; count --------- 4000000 (1 row) Time: 316.628 ms
As you can see in the preceding code, the time required is approximately 300 milliseconds. This might not sound like a lot, but it actually is. 300 ms means that we can roughly execute three queries per CPU per second. On an 8-Core box, this would translate to roughly 25 queries per second. For many applications, this will be enough; but do you really want to buy an 8-Core box to handle just 25 concurrent users, and do you want your entire box to work just on this simple query? Probably not!
Understanding the concept of execution plans
It is impossible to understand the use of indexes without understanding the concept of execution plans. Whenever you execute a query in PostgreSQL, it generally goes through four central steps, described as follows:
Parser: PostgreSQL will check the syntax of the statement.
Rewrite system: PostgreSQL will rewrite the query (for example, rules and views are handled by the rewrite system).
Optimizer or planner: PostgreSQL will come up with a smart plan to execute the query as efficiently as possible. At this step, the system will decide whether or not to use indexes.
Executor: Finally, the execution plan is taken by the executor and the result is generated.
Being able to understand and read execution plans is an essential task of every DBA. To extract the plan from the system, all you need to do is use the explain command, shown as follows:
test=# explain SELECT count(*) FROM t_test; QUERY PLAN ------------------------------------------------------ Aggregate (cost=71622.00..71622.01 rows=1 width=0) -> Seq Scan on t_test (cost=0.00..61622.00 rows=4000000 width=0) (2 rows) Time: 0.370 ms
In our case, it took us less than a millisecond to calculate the execution plan. Once you have the plan, you can read it from right to left. In our case, PostgreSQL will perform a sequential scan and aggregate the data returned by the sequential scan. It is important to mention that each step is assigned to a certain number of costs. The total cost for the sequential scan is 61,622 penalty points (more details about penalty points will be outlined a little later). The overall cost of the query is 71,622.01. What are costs?
Well, costs are just an arbitrary number calculated by the system based on some rules. The higher the costs, the slower a query is expected to be. Always keep in mind that these costs are just a way for PostgreSQL to estimate things—they are in no way a reliable number related to anything in the real world (such as time or amount of I/O needed).
In addition to the costs, PostgreSQL estimates that the sequential scan will yield around four million rows. It also expects the aggregation to return just a single row. These two estimates happen to be precise, but it is not always so.
Calculating costs
When in training, people often ask how PostgreSQL does its cost calculations. Consider a simple example like the one we have next. It works in a pretty simple way. Generally, there are two types of costs: I/O costs and CPU costs.
To come up with I/O costs, we have to figure out the size of the table we are dealing with first:
The pg_relation_size command is a fast way to see how large a table is. Of course, reading a large number (many digits) is somewhat hard, so it is possible to fetch the size of the table in a much prettier format. In our example, the size is roughly 170 MB.
Let's move on now. In PostgreSQL, a table consists of 8,000 blocks. If we divide the size of the table by 8,192 bytes, we will end up with exactly 21,622 blocks. This is how PostgreSQL estimates I/O costs of a sequential scan. If a table is read completely, each block will receive exactly one penalty point, or any number defined by seq_page_cost:
test=# SHOW seq_page_cost; seq_page_cost --------------- 1 (1 row)
To count this number, we have to send four million rows through the CPU (cpu_tuple_cost), and we also have to count these 4 million rows (cpu_operator_cost). So, the calculation looks like this:
For the sequential scan: 21622*1 + 4000000*0.01 (cpu_tuple_cost) = 61622
For the aggregation: 61622 + 4000000*0.0025 (cpu_operator_cost) = 71622
This is exactly the number that we see in the plan.
Drawing important conclusions
Of course, you will never do this by hand. However, there are some important conclusions to be drawn:
The cost model in PostgreSQL is a simplification of the real world
The costs can hardly be translated to real execution times
The cost of reading from a slow disk is the same as the cost of reading from a fast disk
It is hard to take caching into account
If the optimizer comes up with a bad plan, it is possible to adapt the costs either globally in postgresql.conf, or by changing the session variables, shown as follows:
test=# SET seq_page_cost TO 10; SET
This statement inflated the costs at will. It can be a handy way to fix the missed estimates, leading to bad performance and, therefore, to poor execution times.
This is what the query plan will look like using the inflated costs:
test=# explain SELECT count(*) FROM t_test; QUERY PLAN ------------------------------------------------------- Aggregate (cost=266220.00..266220.01 rows=1 width=0) -> Seq Scan on t_test (cost=0.00..256220.00 rows=4000000 width=0) (2 rows)
It is important to understand the PostgreSQL code model in detail because many people have completely wrong ideas about what is going on inside the PostgreSQL optimizer. Offering a basic explanation will hopefully shed some light on this important topic and allow administrators a deeper understanding of the system.
Creating indexes
After this introduction, we can deploy our first index. As we stated before, runtimes of several hundred milliseconds for simple queries are not acceptable. To fight these unusually high execution times, we can turn to CREATE INDEX, shown as follows:
test=# h CREATE INDEX Command: CREATE INDEX Description: define a new index Syntax: CREATE [ UNIQUE ] INDEX [ CONCURRENTLY ] [ name ] ON table_name [ USING method ] ( { column_name | ( expression ) } [ COLLATE collation ] [ opclass ] [ ASC | DESC ] [ NULLS { FIRST | LAST } ] [, ...] ) [ WITH ( storage_parameter = value [, ... ] ) ] [ TABLESPACE tablespace_name ] [ WHERE predicate ]
In the most simplistic case, we can create a normal B-tree index on the ID column and see what happens:
test=# CREATE INDEX idx_id ON t_test (id); CREATE INDEX Time: 3996.909 ms
B-tree indexes are the default index structure in PostgreSQL. Internally, they are also called B+ tree, as described by Lehman-Yao.
On this box (AMD, 4 Ghz), we can build the B-tree index in around 4 seconds, without any database side tweaks. Once the index is in place, the SELECT command will be executed at lightning speed:
test=# SELECT * FROM t_test WHERE id = 423423; id | name --------+------ 423423 | hans (1 row) Time: 0.384 ms
The query executes in less than a millisecond. Keep in mind that this already includes displaying the data, and the query is a lot faster internally.
Analyzing the performance of a query
How do we know that the query is actually a lot faster? In the previous section, you saw EXPLAIN in action already. However, there is a little more to know about this command.
You can add some instructions to EXPLAIN to make it a lot more verbose, as shown here:
test=# h EXPLAIN Command: EXPLAIN Description: show the execution plan of a statement Syntax: EXPLAIN [ ( option [, ...] ) ] statement EXPLAIN [ ANALYZE ] [ VERBOSE ] statement
In the preceding code, the term option can be one of the following:
ANALYZE [ boolean ] VERBOSE [ boolean ] COSTS [ boolean ] BUFFERS [ boolean ] TIMING [ boolean ] FORMAT { TEXT | XML | JSON | YAML }
Consider the following example:
test=# EXPLAIN (ANALYZE TRUE, VERBOSE true, COSTS TRUE, TIMING true) SELECT * FROM t_test WHERE id = 423423; QUERY PLAN ------------------------------------------------------ Index Scan using idx_id on public.t_test (cost=0.43..8.45 rows=1 width=9) (actual time=0.016..0.018 rows=1 loops=1) Output: id, name Index Cond: (t_test.id = 423423) Total runtime: 0.042 ms (4 rows) Time: 0.536 ms
The ANALYZE function does a special form of execution. It is a good way to figure out which part of the query burned most of the time. Again, we can read things inside out. In addition to the estimated costs of the query, we can also see the real execution time. In our case, the index scan takes 0.018 milliseconds. Fast, isn't it? Given these timings, you can see that displaying the result actually takes a huge fraction of the time.
The beauty of EXPLAIN ANALYZE is that it shows costs and execution times for every step of the process. This is important for you to familiarize yourself with this kind of output because when a programmer hits your desk complaining about bad performance, it is necessary to dig into this kind of stuff quickly. In many cases, the secret to performance is hidden in the execution plan, revealing a missing index or so.
It is recommended to pay special attention to situations where the number of expected rows seriously differs from the number of rows really processed. Keep in mind that the planner is usually right, but not always. Be cautious in case of large differences (especially if this input is fed into a nested loop).
Whenever a query feels slow, we always recommend to take a look at the plan first. In many cases, you will find missing indexes.
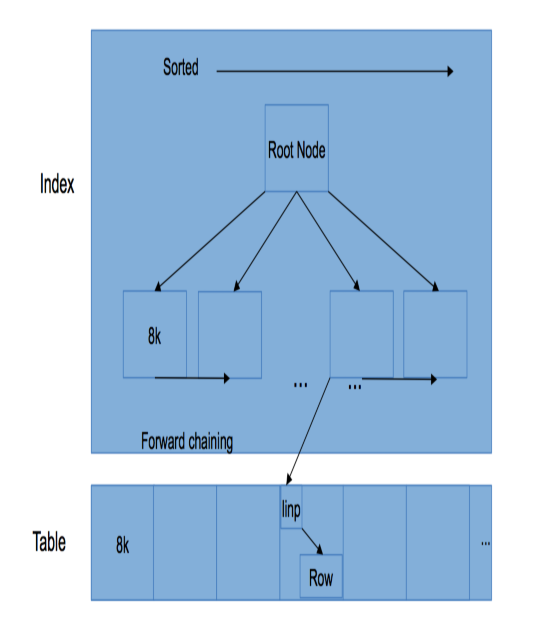
The internal structure of a B-tree index
Before we dig further into the B-tree indexes, we can briefly discuss what an index actually looks like under the hood.
Understanding the B-tree internals
Consider the following image that shows how things work:
In PostgreSQL, we use the so-called Lehman-Yao B-trees (check out http://www.cs.cmu.edu/~dga/15-712/F07/papers/Lehman81.pdf). The main advantage of the B-trees is that they can handle concurrency very nicely. It is possible that hundreds or thousands of concurrent users modify the tree at the same time. Unfortunately, there is not enough room in this book to explain precisely how this works.
The two most important issues of this tree are the facts that I/O is done in 8,000 chunks and that the tree is actually a sorted structure. This allows PostgreSQL to apply a ton of optimizations.
Providing a sorted order
As we stated before, a B-tree provides the system with sorted output. This can come in quite handy. Here is a simple query to make use of the fact that a B-tree provides the system with sorted output:
test=# explain SELECT * FROM t_test ORDER BY id LIMIT 3; QUERY PLAN ------------------------------------------------------ Limit (cost=0.43..0.67 rows=3 width=9) -> Index Scan using idx_id on t_test (cost=0.43..320094.43 rows=4000000 width=9) (2 rows)
In this case, we are looking for the three smallest values. PostgreSQL will read the index from left to right and stop as soon as enough rows have been returned.
This is a very common scenario. Many people think that indexes are only about searching, but this is not true. B-trees are also present to help out with sorting.
Why do you, the DBA, care about this stuff? Remember that this is a typical use case where a software developer comes to your desk, pounds on the table, and complains. A simple index can fix the problem.
Combined indexes
Combined indexes are one more source of trouble if they are not used properly. A combined index is an index covering more than one column.
Let's drop the existing index and create a combined index (make sure your seq_page_cost variable is set back to default to make the following examples work):
test=# DROP INDEX idx_combined; DROP INDEX test=# CREATE INDEX idx_combined ON t_test (name, id); CREATE INDEX
We defined a composite index consisting of two columns. Remember that we put the name before the ID.
A simple query will return the following execution plan:
test=# explain analyze SELECT * FROM t_test WHERE id = 10; QUERY PLAN ------------------------------------------------- Seq Scan on t_test (cost=0.00..71622.00 rows=1 width=9) (actual time=181.502..351.439 rows=1 loops=1) Filter: (id = 10) Rows Removed by Filter: 3999999 Total runtime: 351.481 ms (4 rows)
There is no proper index for this, so the system will fall back to a sequential scan. Why is there no proper index? Well, try to look up for first names only in the telephone book. This is not going to work because a telephone book is sorted by location, last name, and first name. The same applies to our index. A B-tree works basically on the same principles as an ordinary paper phone book. It is only useful if you look up the first couple of values, or simply all of them. Here is an example:
test=# explain analyze SELECT * FROM t_test WHERE id = 10 AND name = 'joe'; QUERY PLAN ------------------------------------------------------ Index Only Scan using idx_combined on t_test (cost=0.43..6.20 rows=1 width=9) (actual time=0.068..0.068 rows=0 loops=1) Index Cond: ((name = 'joe'::text) AND (id = 10)) Heap Fetches: 0 Total runtime: 0.108 ms (4 rows)
In this case, the combined index comes up with a high speed result of 0.1 ms, which is not bad.
After this small example, we can turn to an issue that's a little bit more complex. Let's change the costs of a sequential scan to 100-times normal:
test=# SET seq_page_cost TO 100; SET
Don't let yourself be fooled into believing that an index is always good:
test=# explain analyze SELECT * FROM t_test WHERE id = 10; QUERY PLAN ------------------------------------------------------ Index Only Scan using idx_combined on t_test (cost=0.43..91620.44 rows=1 width=9) (actual time=0.362..177.952 rows=1 loops=1) Index Cond: (id = 10) Heap Fetches: 1 Total runtime: 177.983 ms (4 rows)
Just look at the execution times. We are almost as slow as a sequential scan here. Why does PostgreSQL use the index at all? Well, let's assume we have a very broad table. In this case, sequentially scanning the table is expensive. Even if we have to read the entire index, it can be cheaper than having to read the entire table, at least if there is enough hope to reduce the amount of data by using the index somehow. So, in case you see an index scan, also take a look at the execution times and the number of rows used. The index might not be perfect, but it's just an attempt by PostgreSQL to avoid the worse to come.
Keep in mind that there is no general rule (for example, more than 25 percent of data will result in a sequential scan) for sequential scans. The plans depend on a couple of internal issues, such as physical disk layout (correlation) and so on.
Partial indexes
Up to now, an index covered the entire table. This is not always necessarily the case. There are also partial indexes. When is a partial index useful? Consider the following example:
test=# CREATE TABLE t_invoice ( id serial, d date, amount numeric, paid boolean); CREATE TABLE test=# CREATE INDEX idx_partial ON t_invoice (paid) WHERE paid = false; CREATE INDEX
In our case, we create a table storing invoices. We can safely assume that the majority of the invoices are nicely paid. However, we expect a minority to be pending, so we want to search for them. A partial index will do the job in a highly space efficient way. Space is important because saving on space has a couple of nice side effects, such as cache efficiency and so on.
Dealing with different types of indexes
Let's move on to an important issue: not everything can be sorted easily and in a useful way. Have you ever tried to sort circles? If the question seems odd, just try to do it. It will not be easy and will be highly controversial, so how do we do it best? Would we sort by size or coordinates? Under any circumstances, using a B-tree to store circles, points, or polygons might not be a good idea at all. A B-tree does not do what you want it to do because a B-tree depends on some kind of sorting order.
To provide end users with maximum flexibility and power, PostgreSQL provides more than just one index type. Each index type supports certain algorithms used for different purposes. The following list of index types is available in PostgreSQL (as of Version 9.4.1):
btree: These are the high-concurrency B-trees
gist: This is an index type for geometric searches (GIS data) and for KNN-search
gin: This is an index type optimized for Full-Text Search (FTS)
sp-gist: This is a space-partitioned gist
As we mentioned before, each type of index serves different purposes. We highly encourage you to dig into this extremely important topic to make sure that you can help software developers whenever necessary.
Unfortunately, we don't have enough room in this book to discuss all the index types in greater depth. If you are interested in finding out more, we recommend checking out information on my website at http://www.postgresql-support.de/slides/2013_dublin_indexing.pdf.
Now that we have covered the basics and some selected advanced topics of indexing, we want to shift our attention to a major and highly important administrative task: hunting down missing indexes.
When talking about missing indexes, there is one essential query I have found to be highly valuable. The query is given as follows:
test=# x Expanded display (expanded) is on. test=# SELECT relname, seq_scan, seq_tup_read, idx_scan, idx_tup_fetch, seq_tup_read / seq_scan FROM pg_stat_user_tables WHERE seq_scan > 0 ORDER BY seq_tup_read DESC; -[ RECORD 1 ]-+--------- relname | t_user seq_scan | 824350 seq_tup_read | 2970269443530 idx_scan | 0 idx_tup_fetch | 0 ?column? | 3603165
The pg_stat_user_tables option contains statistical information about tables and their access patterns. In this example, we found a classic problem. The t_user table has been scanned close to 1 million times. During these sequential scans, we processed close to 3 trillion rows. Do you think this is unusual? It's not nearly as unusual as you might think.
Unlock access to the largest independent learning library in Tech for FREE!
Get unlimited access to 7500+ expert-authored eBooks and video courses covering every tech area you can think of.
Renews at $19.99/month. Cancel anytime
In the last column, we divided seq_tup_read through seq_scan. Basically, this is a simple way to figure out how many rows a typical sequential scan has used to finish. In our case, 3.6 million rows had to be read. Do you remember our initial example? We managed to read 4 million rows in a couple of hundred milliseconds. So, it is absolutely realistic that nobody noticed the performance bottleneck before. However, just consider burning, say, 300 ms for every query thousands of times. This can easily create a heavy load on a totally unnecessary scale. In fact, a missing index is the key factor when it comes to bad performance.
Let's take a look at the table description now:
test=# d t_user Table "public.t_user" Column | Type | Modifiers ----------+---------+------------------------------- id | integer | not null default nextval('t_user_id_seq'::regclass) email | text | passwd | text | Indexes: "t_user_pkey" PRIMARY KEY, btree (id)
This is really a classic example. It is hard to tell how often I have seen this kind of example in the field. The table was probably called customer or userbase. The basic principle of the problem was always the same: we got an index on the primary key, but the primary key was never checked during the authentication process. When you log in to Facebook, Amazon, Google, and so on, you will not use your internal ID, you will rather use your e-mail address. Therefore, it should be indexed.
The rules here are simple: we are searching for queries that needed many expensive scans. We don't mind sequential scans as long as they only read a handful of rows or as long as they show up rarely (caused by backups, for example). We need to keep expensive scans in mind, however ("expensive" in terms of "many rows needed").
Here is an example code snippet that should not bother us at all:
The table has been read 8 million times, but in an average, only 12 rows have been returned. Even if we have 1 million indexes defined, PostgreSQL will not use them because the table is simply too small.
It is pretty hard to tell which columns might need an index from inside PostgreSQL. However, taking a look at the tables and thinking about them for a minute will, in most cases, solve the riddle. In many cases, things are pretty obvious anyway, and developers will be able to provide you with a reasonable answer.
As you can see, finding missing indexes is not hard, and we strongly recommend checking this system table once in a while to figure out whether your system works nicely.
There are a couple of tools, such as pgbadger, out there that can help us to monitor systems. It is recommended that you make use of such tools.
There is not only light, there is also some shadow. Indexes are not always good. They can also cause considerable overhead during writes. Keep in mind that when you insert, modify, or delete data, you have to touch the indexes as well. The overhead of useless indexes should never be underestimated. Therefore, it makes sense to not just look for missing indexes, but also for spare indexes that don't serve a purpose anymore.
Detecting slow queries
Now that we have seen how to hunt down tables that might need an index, we can move on to the next example and try to figure out the queries that cause most of the load on your system. Sometimes, the slowest query is not the one causing a problem; it is a bunch of small queries, which are executed over and over again. In this section, you will learn how to track down such queries.
To track down slow operations, we can rely on a module called pg_stat_statements. This module is available as part of the PostgreSQL contrib section. Installing a module from this section is really easy. Connect to PostgreSQL as a superuser, and execute the following instruction (if contrib packages have been installed):
In this view, we can see the queries we are interested in, the total execution time (total_time), the number of calls, and the number of rows returned. Then, we will get some information about the I/O behavior (more on caching later) of the query as well as information about temporary data being read and written. Finally, the last two columns will tell us how much time we actually spent on I/O. The final two fields are active when track_timing in postgresql.conf has been enabled and will give vital insights into potential reasons for disk wait and disk-related speed problems. The blk_* prefix will tell us how much time a certain query has spent reading and writing to the operating system.
Let's see what happens when we want to query the view:
test=# SELECT * FROM pg_stat_statements; ERROR: pg_stat_statements must be loaded via shared_preload_libraries
The system will tell us that we have to enable this module; otherwise, data won't be collected.
All we have to do to make this work is to add the following line to postgresql.conf:
shared_preload_libraries = 'pg_stat_statements'
Then, we have to restart the server to enable it. We highly recommend adding this module to the configuration straightaway to make sure that a restart can be avoided and that this data is always around.
Don't worry too much about the performance overhead of this module. Tests have shown that the impact on performance is so low that it is even too hard to measure. Therefore, it might be a good idea to have this module activated all the time.
If you have configured things properly, finding the most time-consuming queries should be simple:
SELECT * FROM pg_stat_statements ORDER BY total_time DESC;
The important part here is that PostgreSQL can nicely group queries. For instance:
SELECT * FROM foo WHERE bar = 1; SELECT * FROM foo WHERE bar = 2;
PostgreSQL will detect that this is just one type of query and replace the two numbers in the WHERE clause with a placeholder indicating that a parameter was used here.
Of course, you can also sort by any other criteria: highest I/O time, highest number of calls, or whatever. The pg_stat_statement function has it all, and things are available in a way that makes the data very easy and efficient to use.
How to reset statistics
Sometimes, it is necessary to reset the statistics. If you are about to track down a problem, resetting can be very beneficial. Here is how it works:
The pg_stat_reset command will reset the entire system statistics (for example, pg_stat_user_tables). The second call will wipe out pg_stat_statements.
Adjusting memory parameters
After we find the slow queries, we can do something about them. The first step is always to fix indexing and make sure that sane requests are sent to the database. If you are requesting stupid things from PostgreSQL, you can expect trouble. Once the basic steps have been performed, we can move on to the PostgreSQL memory parameters, which need some tuning.
Optimizing shared buffers
One of the most essential memory parameters is shared_buffers. What are shared buffers? Let's assume we are about to read a table consisting of 8,000 blocks. PostgreSQL will check if the buffer is already in cache (shared_buffers), and if it is not, it will ask the underlying operating system to provide the database with the missing 8,000 blocks. If we are lucky, the operating system has a cached copy of the block. If we are not so lucky, the operating system has to go to the disk system and fetch the data (worst case). So, the more data we have in cache, the more efficient we will be.
Setting shared_buffers to the right value is more art than science. The general guideline is that shared_buffers should consume 25 percent of memory, but not more than 16 GB. Very large shared buffer settings are known to cause suboptimal performance in some cases. It is also not recommended to starve the filesystem cache too much on behalf of the database system. Mentioning the guidelines does not mean that it is eternal law—you really have to see this as a guideline you can use to get started. Different settings might be better for your workload. Remember, if there was an eternal law, there would be no setting, but some autotuning magic. However, a contrib module called pg_buffercache can give some insights into what is in cache at the moment. It can be used as a basis to get started on understanding what is going on inside the PostgreSQL shared buffer.
Changing shared_buffers can be done in postgresql.conf, shown as follows:
shared_buffers = 4GB
In our example, shared buffers have been set to 4GB. A database restart is needed to activate the new value.
In PostgreSQL 9.4, some changes were introduced. Traditionally, PostgreSQL used a classical System V shared memory to handle the shared buffers. Starting with PostgreSQL 9.3, mapped memory was added, and finally, it was in PostgreSQL 9.4 that a config variable was introduced to configure the memory technique PostgreSQL will use, shown as follows:
dynamic_shared_memory_type = posix # the default is the first option # supported by the operating system: # posix # sysv # windows # mmap # use none to disable dynamic shared memory
The default value on the most common operating systems is basically fine. However, feel free to experiment with the settings and see what happens performance wise.
Considering huge pages
When a process uses RAM, the CPU marks this memory as used by this process. For efficiency reasons, the CPU usually allocates RAM by chunks of 4,000 bytes. These chunks are called pages. The process address space is virtual, and the CPU and operating system have to remember which process belongs to which page. The more pages you have, the more time it takes to find where the memory is mapped. When a process uses 1 GB of memory, it means that 262.144 blocks have to be looked up.
Most modern CPU architectures support bigger pages, and these pages are called huge pages (on Linux).
To tell PostgreSQL that this mechanism can be used, the following config variable can be changed in postgresql.conf:
huge_pages = try # on, off, or try
Of course, your Linux system has to know about the use of huge pages. Therefore, you can do some tweaking, as follows:
In our case, the size of the huge pages is 2 MB. So, if there is 1 GB of memory, 512 huge pages are needed.
The number of huge pages can be configured and activated by setting nr_hugepages in the proc filesystem. Consider the following example:
echo 512 > /proc/sys/vm/nr_hugepages
Alternatively, we can use the sysctl command or change things in /etc/sysctl.conf:
sysctl -w vm.nr_hugepages=512
Huge pages can have a significant impact on performance.
Tweaking work_mem
There is more to PostgreSQL memory configuration than just shared buffers. The work_mem parameter is widely used for operations such as sorting, aggregating, and so on.
Let's illustrate the way work_mem works with a short, easy-to-understand example. Let's assume it is an election day and three parties have taken part in the elections.
The data is as follows:
test=# CREATE TABLE t_election (id serial, party text); test=# INSERT INTO t_election (party) SELECT 'socialists' FROM generate_series(1, 439784); test=# INSERT INTO t_election (party) SELECT 'conservatives' FROM generate_series(1, 802132); test=# INSERT INTO t_election (party) SELECT 'liberals' FROM generate_series(1, 654033);
We add some data to the table and try to count how many votes each party has:
test=# explain analyze SELECT party, count(*) FROM t_election GROUP BY 1; QUERY PLAN ------------------------------------------------------ HashAggregate (cost=39461.24..39461.26 rows=3 width=11) (actual time=609.456..609.456 rows=3 loops=1) Group Key: party -> Seq Scan on t_election (cost=0.00..29981.49 rows=1895949 width=11) (actual time=0.007..192.934 rows=1895949 loops=1) Planning time: 0.058 ms Execution time: 609.481 ms (5 rows)
First of all, the system will perform a sequential scan and read all the data. This data is passed on to a so-called HashAggregate. For each party, PostgreSQL will calculate a hash key and increment counters as the query moves through the tables. At the end of the operation, we will have a chunk of memory with three values and three counters. Very nice! As you can see, the explain analyze statement does not take more than 600 ms.
Note that the real execution time of the query will be a lot faster. The explain analyze statement does have some serious overhead. Still, it will give you valuable insights into the inner workings of the query.
Let's try to repeat this same example, but this time, we want to group by the ID. Here is the execution plan:
test=# explain analyze SELECT id, count(*) FROM t_election GROUP BY 1; QUERY PLAN ------------------------------------------------------ GroupAggregate (cost=253601.23..286780.33 rows=1895949 width=4) (actual time=1073.769..1811.619 rows=1895949 loops=1) Group Key: id -> Sort (cost=253601.23..258341.10 rows=1895949 width=4) (actual time=1073.763..1288.432 rows=1895949 loops=1) Sort Key: id Sort Method: external sort Disk: 25960kB -> Seq Scan on t_election (cost=0.00..29981.49 rows=1895949 width=4) (actual time=0.013..235.046 rows=1895949 loops=1) Planning time: 0.086 ms Execution time: 1928.573 ms (8 rows)
The execution time rises by almost 2 seconds and, more importantly, the plan changes. In this scenario, there is no way to stuff all the 1.9 million hash keys into a chunk of memory because we are limited by work_mem. Therefore, PostgreSQL has to find an alternative plan. It will sort the data and run GroupAggregate. How does it work? If you have a sorted list of data, you can count all equal values, send them off to the client, and move on to the next value. The main advantage is that we don't have to keep the entire result set in memory at once. With GroupAggregate, we can basically return aggregations of infinite sizes. The downside is that large aggregates exceeding memory will create temporary files leading to potential disk I/O.
Keep in mind that we are talking about the size of the result set and not about the size of the underlying data.
Let's try the same thing with more work_mem:
test=# SET work_mem TO '1 GB'; SET test=# explain analyze SELECT id, count(*) FROM t_election GROUP BY 1; QUERY PLAN ------------------------------------------------------ HashAggregate (cost=39461.24..58420.73 rows=1895949 width=4) (actual time=857.554..1343.375 rows=1895949 loops=1) Group Key: id -> Seq Scan on t_election (cost=0.00..29981.49 rows=1895949 width=4) (actual time=0.010..201.012 rows=1895949 loops=1) Planning time: 0.113 ms Execution time: 1478.820 ms (5 rows)
In this case, we adapted work_mem for the current session. Don't worry, changing work_mem locally does not change the parameter for other database connections. If you want to change things globally, you have to do so by changing things in postgresql.conf. Alternatively, 9.4 offers a command called ALTER SYSTEM SET work_mem TO '1 GB'. Once SELECT pg_reload_conf() has been called, the config parameter is changed as well.
What you see in this example is that the execution time is around half a second lower than before. PostgreSQL switches back to the more efficient plan.
However, there is more; work_mem is also in charge of efficient sorting:
test=# explain analyze SELECT * FROM t_election ORDER BY id DESC; QUERY PLAN ------------------------------------------------------ Sort (cost=227676.73..232416.60 rows=1895949 width=15) (actual time=695.004..872.698 rows=1895949 loops=1) Sort Key: id Sort Method: quicksort Memory: 163092kB -> Seq Scan on t_election (cost=0.00..29981.49 rows=1895949 width=15) (actual time=0.013..188.876 rows=1895949 loops=1) Planning time: 0.042 ms Execution time: 995.327 ms (6 rows)
In our example, PostgreSQL can sort the entire dataset in memory. Earlier, we had to perform a so-called "external sort Disk", which is way slower because temporary results have to be written to disk.
The work_mem command is used for some other operations as well. However, sorting and aggregation are the most common use cases.
Keep in mind that work_mem should not be abused, and work_mem can be allocated to every sorting or grouping operation. So, more than just one work_mem amount of memory might be allocated by a single query.
Improving maintenance_work_mem
To control the memory consumption of administrative tasks, PostgreSQL offers a parameter called maintenance_work_mem. It is used to handle index creations as well as VACUUM.
Usually, creating an index (B-tree) is mostly related to sorting, and the idea of maintenance_work_mem is to speed things up. However, things are not as simple as they might seem. People might assume that increasing the parameter will always speed things up, but this is not necessarily true; in fact, smaller values might even be beneficial. We conducted some research to solve this riddle. The in-depth results of this research can be found at http://www.cybertec.at/adjusting-maintenance_work_mem/.
However, indexes are not the only beneficiaries. The maintenance_work_mem command is also here to help VACUUM clean out indexes. If maintenance_work_mem is too low, you might see VACUUM scanning tables repeatedly because dead items cannot be stored in memory during VACUUM. This is something that should basically be avoided.
Just like all other memory parameters, maintenance_work_mem can be set per session, or it can be set globally in postgresql.conf.
Adjusting effective_cache_size
The number of shared_buffers assigned to PostgreSQL is not the only cache in the system. The operating system will also cache data and do a great job of improving speed. To make sure that the PostgreSQL optimizer knows what to expect from the operation system, effective_cache_size has been introduced. The idea is to tell PostgreSQL how much cache there is going to be around (shared buffers + operating system side cache). The optimizer can then adjust its costs and estimates to reflect this knowledge.
It is recommended to always set this parameter; otherwise, the planner might come up with suboptimal plans.
Summary
In this article, you learned how to detect basic performance bottlenecks. In addition to this, we covered the very basics of the PostgreSQL optimizer and indexes. At the end of the article, some important memory parameters were presented.

 United States
United States
 Great Britain
Great Britain
 India
India
 Germany
Germany
 France
France
 Canada
Canada
 Russia
Russia
 Spain
Spain
 Brazil
Brazil
 Australia
Australia
 Singapore
Singapore
 Canary Islands
Canary Islands
 Hungary
Hungary
 Ukraine
Ukraine
 Luxembourg
Luxembourg
 Estonia
Estonia
 Lithuania
Lithuania
 South Korea
South Korea
 Turkey
Turkey
 Switzerland
Switzerland
 Colombia
Colombia
 Taiwan
Taiwan
 Chile
Chile
 Norway
Norway
 Ecuador
Ecuador
 Indonesia
Indonesia
 New Zealand
New Zealand
 Cyprus
Cyprus
 Denmark
Denmark
 Finland
Finland
 Poland
Poland
 Malta
Malta
 Czechia
Czechia
 Austria
Austria
 Sweden
Sweden
 Italy
Italy
 Egypt
Egypt
 Belgium
Belgium
 Portugal
Portugal
 Slovenia
Slovenia
 Ireland
Ireland
 Romania
Romania
 Greece
Greece
 Argentina
Argentina
 Netherlands
Netherlands
 Bulgaria
Bulgaria
 Latvia
Latvia
 South Africa
South Africa
 Malaysia
Malaysia
 Japan
Japan
 Slovakia
Slovakia
 Philippines
Philippines
 Mexico
Mexico
 Thailand
Thailand