









Object detection and tracking is an active research topic in the field of computer vision that makes efforts to detect, recognize, and track objects through a series of frames. It has been found that object detection and tracking in the video sequence is a challenging task and a very time-consuming process. Object detection is the first step in building a larger computer vision system. Object tracking is defined as the task of detecting objects in every frame of the video and establishing the correspondence between the detected objects from one frame to the other.
[box type=”shadow” align=”” class=”” width=””]This article is an excerpt from a book written by Bhaumik Vaidya titled Hands-On GPU-Accelerated Computer Vision with OpenCV and CUDA. This book provides a detailed overview of integrating OpenCV with CUDA for practical applications. You will learn GPU programming with CUDA, explore OpenCV acceleration with GPUs and CUDA, and learn how to deploy OpenCV applications on NVIDIA Jetson TX1. To follow along with the article, you can find the code in the book’s GitHub repository. Check out the video to see the code in action.[/box]
In this article, we will see how to develop complex computer vision applications with OpenCV and CUDA. We will use the example of object detection and tracking to demonstrate the concepts. We will start with an explanation of detecting an object based on color, then describe the methods to detect an object with a particular shape.
Object detection and tracking based on color
An object has many global features like color and shape, which describe the object as a whole. These features can be utilized for the detection of an object and tracking it in a sequence of frames. In this section, we will use color as a feature to detect an object with a particular color. This method is useful when an object to be detected is of a specific color and this color is different from the color of the background. If the object and background have the same color, then this method for detection will fail. We will try to detect any object with a blue color from a webcam stream using OpenCV and CUDA.
Blue object detection and tracking
The first question that should come to your mind is which color space should be used for segmenting blue color. A Red Green Blue (RGB) color space does not separate color information from intensity information. The color spaces that separate color information from the intensity, like Hue Saturation Value (HSV) and YCrCb (where Y′ is the luma component and CB and CR are the blue-difference and red-difference chroma components), are ideal for this kind of task. Every color has a specific range in the hue channel that can be utilized for detection of that color.
Find the code for this section on GitHub.
The boilerplate code for starting the webcam, capturing frames, and uploading on-device memory for a GPU operation is as follows:
 To detect the blue color, we need to find a range for blue color in the HSV color space. If a range is accurate then the detection will be accurate. The range of blue color for three channels, hue, saturation, and value, is as follows:
To detect the blue color, we need to find a range for blue color in the HSV color space. If a range is accurate then the detection will be accurate. The range of blue color for three channels, hue, saturation, and value, is as follows:

This range will be used to threshold an image in a particular channel to create a mask for the blue color. If this mask is again ANDed with the original frame, then only a blue object will be there in the resultant image. The code for this is as follows:
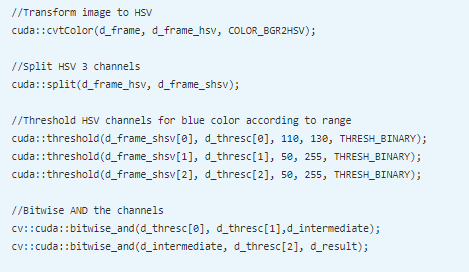
The frame from the webcam is converted to an HSV color space. The blue color has a different range in three channels, so each channel has to be thresholded individually. The channels are split using the split method and thresholded using the threshold function. The minimum and maximum ranges for each channel are used as lower and upper thresholds. The channel value inside this range will be converted to white and others are converted to black. These three thresholded channels are logically ANDed to get a final mask for a blue color. This mask can be used to detect and track an object with a blue color from a video.
The output of two frames, one without the blue object and the other with the blue object, is as follows:

As can be seen from the result, when a frame does not contain any blue object, the mask is almost black; whereas in the frame below, when the blue object comes into frame, that part turns white. This method will only work when the background does not contain the color of an object.
Object detection and tracking based on a shape
The shape of an object can also be utilized as a global feature to detect an object with a distinct shape. This shape can be a straight line, polygons, circles, or any other irregular shapes. Object boundaries, edges, and contours can be utilized to detect an object with a particular shape. In this section, we will use the Canny edge detection algorithm and Hough transform to detect two regular shapes, which are a line and a circle.
Canny edge detection
In this section, we will implement the Canny edge detection algorithm using OpenCV and CUDA. This algorithm combines Gaussian filtering, gradient finding, non-maximum suppression, and hysteresis thresholding. High pass filters are very sensitive to noise. In Canny edge detection, Gaussian smoothing is done before detecting edges, which makes it less sensitive to noises. It also has a non-maximum suppression stage after detecting edges to remove unnecessary edges from the result.
Find the code for this section on GitHub.
Canny edge detection is a computationally intensive task, which is hard to use in real-time applications. The CUDA version of the algorithm can be used to accelerate it. The code for implementing a Canny edge detection algorithm is described below:
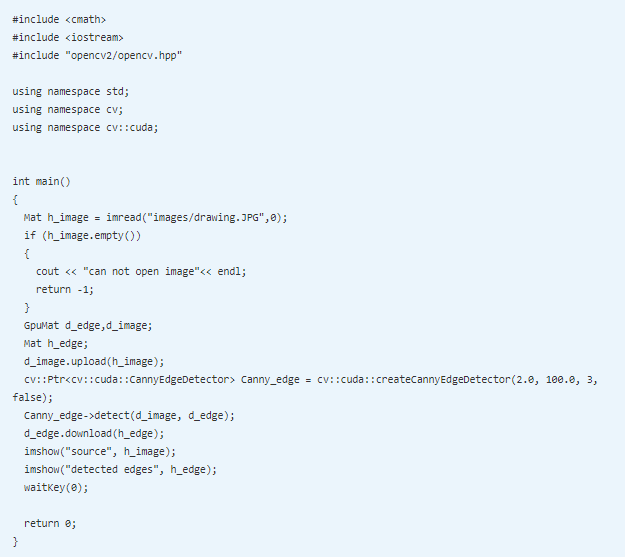
OpenCV and CUDA provide the createCannyEdgeDetector class for Canny edge detection. The object of this class is created, and many arguments can be passed while creating it. The first and second arguments are the low and high thresholds for hysteresis thresholding. If the intensity gradient at a point is greater then the maximum threshold, then it is categorized as an edge point. If the gradient is less than the low threshold, then the point is not an edge point. If the gradient is in between thresholds, then whether the point is an edge or not is decided based on connectivity. The third argument is the aperture size for the edge detector. The final argument is the Boolean argument, which indicates whether to use L2_norm or L1_norm for gradient magnitude calculation. L2_norm is computationally expensive but it is more accurate. The true value indicates the use of L2_norm.
The output of the code is shown below:

Straight-line detection using Hough transform
The detection of straight lines is important in many computer vision applications, like lane detection. It can also be used to detect lines that are part of other regular shapes. Hough transform is a popular feature extraction technique used in computer vision to detect straight lines.
Find the code for this section on GitHub.
We will not go into detail about how Hough transform detects lines, but we will see how it can be implemented in OpenCV and CUDA. The code for implementing Hough transform for line detection is as follows:
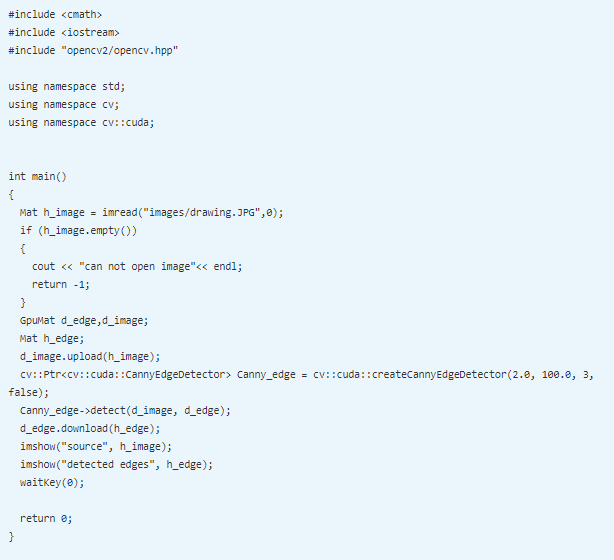

OpenCV provides the createHoughSegmentDetector class for implementing Hough transform. It needs an edge map of an image as input. So edges are detected from an image using a Canny edge detector. The output of the Canny edge detector is uploaded to the device memory for GPU computation and the edges can also be computed on GPU.
The object of createHoughSegmentDetector is created. It requires many arguments. The first argument indicates the resolution of parameter r used in Hough transform, which is taken as 1 pixel normally. The second argument is the resolution of parameter theta in radians, which is taken as 1 radian or pi/180. The third argument is the minimum number of points that are needed to form a line, which is taken as 50 pixels. The final argument is the maximum gap between two points to be considered as the same line, which is taken as 5 pixels.
The detect method of the created object is used to detect straight lines. It needs two arguments. The first argument is the image on which the edges are to be detected, and the second argument is the array in which detected line points will be stored. The array contains the starting and ending (x,y) points of the detected lines. This array is iterated using the for loop to draw individual lines on an image using the line function from OpenCV. The final image is displayed using the imshow function.
Hough transform is a mathematically intensive step. Just to show an advantage of CUDA, we will implement the same algorithm for CPU and compare the performance of it with a CUDA implementation. The CPU code for Hough transform is as follows:

The HoughLinesP function is used for detecting lines on a CPU using probabilistic Hough transform. The first two arguments are the source image and the array to store output line points. The third and fourth arguments are a resolution for r and theta. The fifth argument is the threshold that indicates the minimum number of intersection points for a line. The sixth argument indicates the minimum number of points needed to form a line. The last argument indicates the maximum gap between points to be considered on the same line.
The array returned by the function is iterated using the for loop for displaying detected lines on the original image. The output for both the GPU and CPU function is as follows:

The comparison between the performance of the GPU and CPU code for the Hough transform is shown in the following screenshot:

It takes around 4 ms for a single image to process on the CPU and 1.5 ms on the GPU, which is equivalent to 248 FPS on the CPU, and 632 FPS on the GPU, which is almost 2.5 times an improvement on the GPU.
Circle detection
Hough transform can also be used for circle detection. It can be used in many applications, like ball detection and tracking and coin detection, and so on, where objects are circular. OpenCV and CUDA provide a class to implement this.
Find the code for this section on GitHub.
The code for coin detection using Hough transform is as follows:
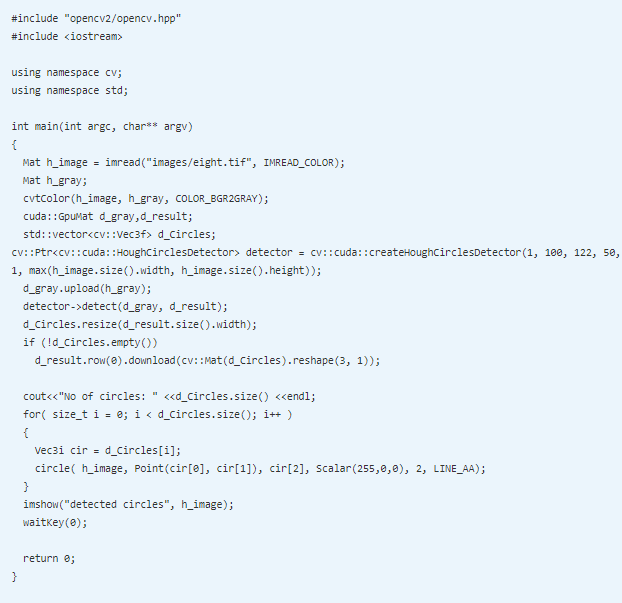
There is a createHoughCirclesDetector class for detecting the circular object. The object of that class is created. Many arguments can be provided while creating an object of this class. The first argument is dp that signifies an inverse ratio of the accumulator resolution to the image resolution, which is mostly taken as 1. The second argument is the minimum distance between the centers of the detected circle. The third argument is a Canny threshold and the fourth argument is the accumulator threshold. The fifth and sixth arguments are the minimum and maximum radiuses of the circles to be detected.
The minimum distance between the centers of the circle is taken as 100 pixels. You can play around with this value. If this is decreased, then many circles are detected falsely on the original image, while if it is increased then some true circles may be missed. The last two arguments, which are the minimum and maximum radiuses, can be taken as 0 if you don’t know the exact dimension. In the preceding code, it is taken as 1 and maximum dimension of an image to detect all circles in an image. The output of the program is as follows:

The Hough transform is very sensitive to Gaussian and salt-pepper noise. So, sometimes it is better to preprocess the image with Gaussian and median filters before applying Hough transform. It will give more accurate results.
To summarize, we have used the Hough line and circle transforms to detect objects with regular shapes. Contours and convexity can also be used for shape detection. The functions for this are available in OpenCV, but they are not available with CUDA implementation. You will have to develop your own versions of these functions.
Color-based object detection is easier to implement, but it requires that the object should have a distinct color from the background. For shape-based object detection, the Canny edge detection technique has been described to detect edges, and the Hough transform has been described for straight line and circle detection. It has many applications, such as land detection, ball tracking, and so on. The color and shape are global features, which are easier to compute and require less memory. They are more susceptible to noise.
If you found this post useful, do check out the book, Hands-On GPU-Accelerated Computer Vision with OpenCV and CUDA. This book helps you discover how CUDA allows OpenCV to handle complex and rapidly growing image data processing in computer and machine vision by accessing the power of GPU.
Read Next
Using machine learning for phishing domain detection [Tutorial]
Implementing face detection using the Haar Cascades and AdaBoost algorithm
OpenCV 4.0 releases with experimental Vulcan, G-API module and QR-code detector among others









