









In today’s tutorial we will assist you to overcome the errors that arise while loading, deleting or updating large volumes of data using Teradata Utilities.
[box type=”note” align=”” class=”” width=””]This article is an excerpt from Teradata Cookbook co-authored by Abhinav Khandelwal and Rajsekhar Bhamidipati. This book provides recipes to simplify the daily tasks performed by database administrators (DBA) along with providing efficient data warehousing solutions in Teradata database system.[/box]
Resolving FastLoad error 2652
When data is being loaded via FastLoad, a table lock is placed on the target table. This means that the table is unavailable for any other operation. A lock on a table is only released when FastLoad encounters the END LOADING command, which terminates phase 2, the so-called application phase. FastLoad may get terminated in phase 1 due to any of the following reasons:
- Load script results in failure (error code 8 or 12)
- Load script is aborted by admin or some other session
- FastLoad fails due to bad record or file
- Forgetting to add end loading statement in script
If so, it keeps a lock on the table, which needs to be released manually. In this recipe, we will see the steps to release FastLoad locks.
Getting ready
Identify the table on which FastLoad is been ended prematurely and tables are in locked state. You need to have valid credentials for the Teradata Database.
Execute the dummy FastLoad script from the same user or the user which has write access to the lock table.
A user requires the following privileges/rights in order to execute the FastLoad:
- SELECT and INSERT (CREATE and DROP or DELETE) access to the target or loading table
- CREATE and DROP TABLE on error tables
- SELECT, INSERT, UPDATE, and DELETE are required privileges for the user
PUBLIC on the restart log table (SYSADMIN.FASTLOG). There will be a row in the FASTLOG table for each FastLoad job that has not completed in the system.
How to do it…
- Open a notepad and create the following script:
.LOGON 127.0.0.1/dbc, dbc; /* Vaild system name and credentials to
your system */
.DATABASE Database_Name; /* database under which locked table is */
erorfiles errortable_name, uv_tablename /* same error table name as
in script */
begin loading locked_table; /* table which is getting 2652 error */
.END LOADING; /* to end pahse 2 and release the lock */
.LOGOFF;- Save it as dummy_fl.txt.
- Open the windows Command Prompt and execute this using the FastLoad command, as shown in the following screenshot:

- This dummy script with no insert statement should release the lock on the target Table.
- Execute Select on the locked table to see if the lock is released on the table.
How it works…
As FastLoad is designed to work only on empty tables, it becomes necessary that the loading of the table finishes in one go. If the load script is errored out prematurely in phase
2, without encountering the END loading command, it leaves a lock on loading the table. Fastload locks can’t be released via the HUT utility, as there are no technical lock on the table.
To execute FastLoad, the following are some requirements:
- Log table: FastLoad puts its progress information in the fastlog table.
- EMPTY TABLE: FastLoad needs the table to be empty before inserting rows into that table.
- TWO ERROR TABLES: FastLoad requires two error tables to be created; you just need to name them, and no ddl is required. The first error table records any translation or constraint violation error, whereas the second error table captures errors related to the duplication of values for Unique Primary Indexes (UPI). After the completion of FastLoad, you can analyze these error tables as to why the records got rejected.
There’s more…
If this does not fix the issue, you need to drop the target table and error tables associated with it. Before proceeding with dropping tables, check with the administrator to abort any FastLoad sessions associated with this table.
Resolving MLOAD error 2571
MLOAD works in five phases, unlike FastLoad, which only works in two phases. MLOAD can fail in either phase three or four. Figure shows 5 stages of MLOAD.
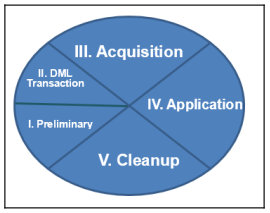
- Preliminary: Basic setup. Syntax checking, establishing session with the Teradata Database, creation of error tables (two error tables per target table), and the creation of work tables and log tables are done in this phase.
- DML Transaction phase: Request is parse through PE and a step plan is generated. Steps and DML are then sent to AMP and stored in appropriate work tables for each target table. Input data sent will be stored in these work tables, which will be applied to the target table later on.
- Acquisition phase: Unsorted data is sent to AMP in blocks of 64K. Rows are hashed by PI and sent to appropriate AMPs. Utility places locks on target tables in preparation for the application phase to apply rows in target tables.
- Application phase: Changes are applied to target tables and NUSI subtables. Lock on table is held in this phase.
- Cleanup phase: If the error code of all the steps is 0, MLOAD successfully completes and releases all the locks on the specified table. This being the case, all empty error tables, worktables, and the log table are dropped.
Getting ready
Identify the table which is getting affected by error 2571. Make sure no host utility is running on this table and the load job is in a failed state for this table.
How to do it…
- Check on viewpoint for any active utility job for this table.
- If you find any active job, let it complete.
- If there is a reason that you need to release the lock, first abort all the sessions of the host utility from viewpoint. Ask your administrator to do it.
- Execute the following command:
RELEASE MLOAD <databasename.tablename>;
>- If you get a Not able to release MLOAD Lock error, execute the following Command:
/* Release lock in application phase */
RELEASE MLOAD <databasename.tablename> in apply;- Once the locks are released you need to drop all the associated error tables, the log table, and work tables with it.
- Re-execute MLOAD after correcting the error.
How it works…
The Mload utility places a lock in table headers to alert other utilities that a MultiLoad is in session for this table. They include:
- Acquisition lock:
- DML allows all
- DDL allows DROP only
- Application lock:
- DML allows SELECT with ACCESS only
- DDL allows DROP only
There’s more…
If the release lock statement still gives an error and does not release the lock on the table, you need to use SELECT with the ACCESS lock to copy the content of the locked table to a new one and drop the locked tables.
If you start receiving the error 7446 Mload table %ID cannot be released because NUSI exists, you need to drop all the NUSI on the table and use ALTER Table to nonfallback to accomplish the task.
Resolving failure 7547
This error is associated with the UPDATE statement, which could be SQL based or could be in MLOAD.
Various times, while updating the set of rows in a table, the update fails on Failure 7547 Target row updated by multiple source rows.
This error will happen when you update the target with multiple rows from the source. This means there are duplicated values present in the source tables.
Getting ready
Let’s create sample volatile tables and insert values into them. After that, we will execute the UPDATE command, which will fail to result in 7547:
- Create a TARGET TABLE with the following DDL and insert values into it:
** TARGET TABLE**
create volatile table accounts
(
CUST_ID,
CUST_NAME,
Sal
)with data
primary index(cust_id)
insert values (1,'will',2000);
insert values (2,'bekky',2800);
insert values (3,'himesh',4000);- Create a SOURCE TABLE with the following DDL and insert values into it:
** SOURCE TABLE**
create volatile table Hr_payhike
(
CUST_ID,
CUST_NAME,
Sal_hike
) with data
primary index(cust_id)
insert values (1,'will',2030);
insert values (1,'bekky',3800);
insert values (3,'himesh',7000);- Execute the MLOAD script. Following the snippet from the MLOAD script, only update part (which will fail):
/* Snippet from MLOAD update */
UPDATE ACC
FROM ACCOUNTS ACC , Hr_payhike SUPD
SET Sal= TUPD.Sal_hike
WHERE
Acc.CUST_ID = SUPD.CUST_ID;
Failure: Target row updated by multiple source rows
How to do it…
- Check for duplicate values in the source table using the following:
/*Check for duplicate values in source table*/
SELECT cust_id,count(*)
from Hr_payhike
group by 1 order by 2 desc- The output will be generated with CUST_ID =1 and has two values which are causing errors. The reason for this is that while updating the TARGET table, the optimizer won’t be able to understand from which row it should update the TARGET row. Who’s salary will be updated Will or Bekky?
- To resolve the error, execute the following update query:
/* Update part of MLOAD */
UPDATE ACC
FROM ACCOUNTS ACC ,
( SELECT
CUST_ID,
CUST_NAME,
SAL_HIKE
FROM
Hr_payhike
QUALIFY ROW_NUMBER() OVER (PARTITION BY CUST_ID ORDER BY
CUST_NAME,SAL_HIKE DESC)=1) SUPD
SET Sal= SUPD.Sal_hike
WHERE
Acc.CUST_ID = SUPD.CUST_ID;- Now, the update will run without error.
How it works…
Failure will happen when you update the target with multiple rows from the source. If you defined a primary index column for your target, and if those columns are in an update query condition, this error will occur.
To further resolve this, you can delete the duplicate from the source table itself and execute the original update without any modification. But if the source data can’t be changed, then you need to change the update statement.
To summarize, we have successfully learned how to overcome or prevent errors while using utilities for loading data into database. You could also check out the Teradata Cookbook for more than 100 recipes on enterprise data warehousing solutions.

Read Next:
2018 is the year of graph databases. Here’s why.
6 reasons to choose MySQL 8 for designing database solutions
Amazon Neptune, AWS’ cloud graph database, is now generally available