Last year in August Google released the Transformer, a novel neural network architecture based on a self-attention mechanism particularly well suited for language understanding. Before the Transformer, most neural network based approaches to machine translation relied on recurrent neural networks (RNNs) which operated sequentially using recurrence.
In contrast to RNN-based approaches, the Transformer used no recurrence, instead it processed all words or symbols in the sequence and let each word attend the other word over multiple processing steps using a self-attention mechanism to incorporate context from words farther away. This approach led Transformer to train the recurrent models much faster and yield better translation results than RNNs.
“However, on smaller and more structured language understanding tasks, or even simple algorithmic tasks such as copying a string (e.g. to transform an input of “abc” to “abcabc”), the Transformer does not perform very well.”, says Stephan Gouws and Mostafa Dehghani from the Google Brain team.
Hence this year the team has come up with Universal Transformers, an extension to standard Transformer which is computationally universal using a novel and efficient flavor of parallel-in-time recurrence. The Universal Transformer is built to yield stronger results across a wider range of tasks.
How does the Universal Transformer function
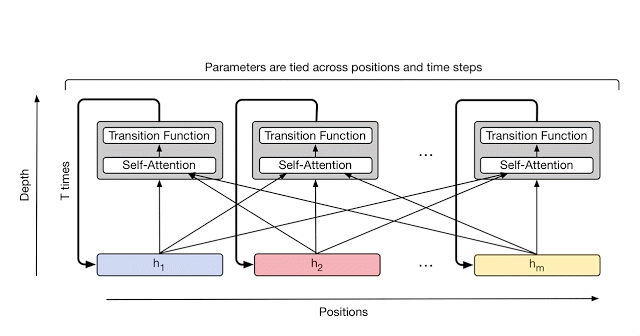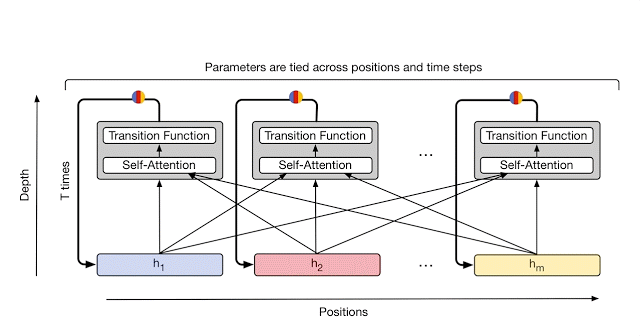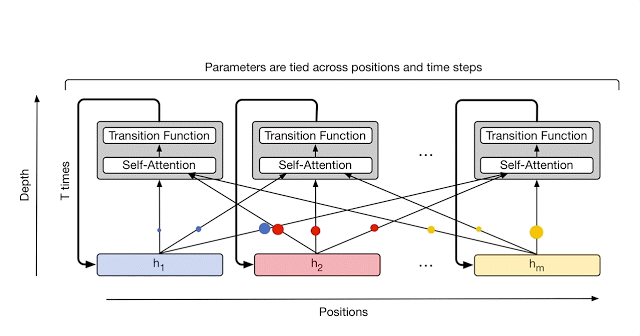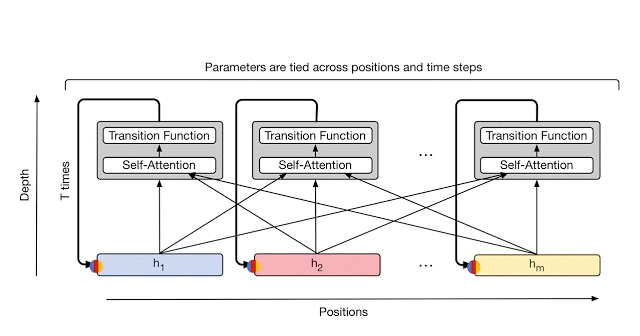
The Universal Transformer is built on the parallel structure of the Transformer to retain its fast training speed. It has replaced the Transformer’s fixed stack of different transformation functions with several applications of a single, parallel-in-time recurrent transformation function. Crucially, where an RNN can process a sequence symbol-by-symbol (left to right), the Universal Transformer will process all symbols at the same time (like the Transformer), but then refine its interpretation of every symbol in parallel over a variable number of recurrent processing steps using self-attention. This parallel-in-time recurrence mechanism is both faster than the serial recurrence used in RNNs, making the Universal Transformer more powerful than the standard feedforward Transformer.
Source: Google AI Blog
Unlock access to the largest independent learning library in Tech for FREE!
Get unlimited access to 7500+ expert-authored eBooks and video courses covering every tech area you can think of.
Renews at $19.99/month. Cancel anytime
At each step, information is communicated from each symbol (e.g. word in the sentence) to all other symbols using self-attention, just like in the original Transformer. However, now the number of times transformation will be applied to each symbol (i.e. the number of recurrent steps) can either be manually set ahead of time (e.g. to some fixed number or to the input length), or it can be decided dynamically by the Universal Transformer itself. To achieve the latter, the team has added an adaptive computation mechanism to each position which will allocate more processing steps to symbols that are ambiguous or require more computations.
Furthermore, on a diverse set of challenging language understanding tasks the Universal Transformer generalizes significantly better and achieves a new state of the art on the bAbI linguistic reasoning task and the challenging LAMBADA language modeling task. But perhaps the larger feat is that the Universal Transformer also improves translation quality by 0.9 BLEU1 over a base Transformer with the same number of parameters, trained in the same way on the same training data.
“Putting things in perspective, this almost adds another 50% relative improvement on top of the previous 2.0 BLEU improvement that the original Transformer showed over earlier models when it was released last year”, says the Google Brain team.
The code to train and evaluate Universal Transformers can be found in the open-source Tensor2Tensor repository page.
Read in detail about the Universal Transformers on the Google AI blog.
Create an RNN based Python machine translation system [Tutorial]
FAE (Fast Adaptation Engine): iOlite’s tool to write Smart Contracts using machine translation
Setting up the Basics for a Drupal Multilingual site: Languages and UI Translation

 United States
United States
 Great Britain
Great Britain
 India
India
 Germany
Germany
 France
France
 Canada
Canada
 Russia
Russia
 Spain
Spain
 Brazil
Brazil
 Australia
Australia
 Singapore
Singapore
 Canary Islands
Canary Islands
 Hungary
Hungary
 Ukraine
Ukraine
 Luxembourg
Luxembourg
 Estonia
Estonia
 Lithuania
Lithuania
 South Korea
South Korea
 Turkey
Turkey
 Switzerland
Switzerland
 Colombia
Colombia
 Taiwan
Taiwan
 Chile
Chile
 Norway
Norway
 Ecuador
Ecuador
 Indonesia
Indonesia
 New Zealand
New Zealand
 Cyprus
Cyprus
 Denmark
Denmark
 Finland
Finland
 Poland
Poland
 Malta
Malta
 Czechia
Czechia
 Austria
Austria
 Sweden
Sweden
 Italy
Italy
 Egypt
Egypt
 Belgium
Belgium
 Portugal
Portugal
 Slovenia
Slovenia
 Ireland
Ireland
 Romania
Romania
 Greece
Greece
 Argentina
Argentina
 Netherlands
Netherlands
 Bulgaria
Bulgaria
 Latvia
Latvia
 South Africa
South Africa
 Malaysia
Malaysia
 Japan
Japan
 Slovakia
Slovakia
 Philippines
Philippines
 Mexico
Mexico
 Thailand
Thailand














