









Last month Google announced Cloud Text-to-Speech, their speech synthesis API that features DeepMind and WaveNet models. Now, they have announced their largest overhaul of Cloud Speech-to-Text (formerly known as Cloud Speech API) since it was introduced in 2016.
Google’s Speech-to-Text API has been enhanced for business use cases, including phone-call and video transcription. With this new Cloud Speech-to-Text update one can get access to the latest research from Google’s machine learning expert team, all via a simple REST API. It also supports Standard service level agreement (SLA) with 99.9% availability.
Here’s a sneak peek into the latest updates to Google’s Cloud Speech-to-Text API:
New video and phone call transcription models: Google has added models created for specific use cases such as phone call transcriptions and transcriptions of audio from video.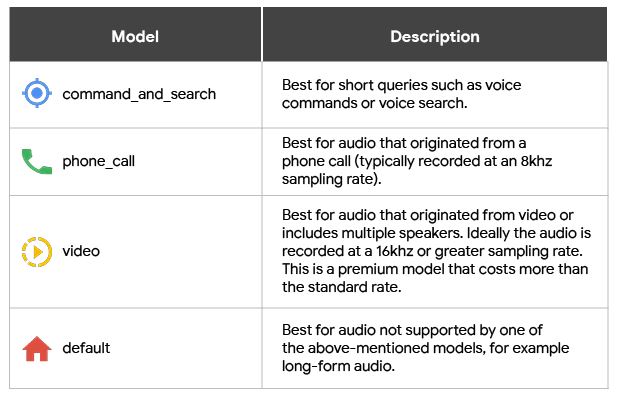 Video and phone call transcription models
Video and phone call transcription models
Readable text with automatic punctuation: Google created a new LSTM neural network to improve automating punctuation in long-form speech transcription. This Cloud Speech-to-Text model, currently in beta, can automatically suggest commas, question marks, and periods for your text.
Use case description with recognition metadata: The information taken from transcribed audio or video with tags such as ‘voice commands to a Google home assistant’ or ‘soccer sport tv shows’, is aggregated across Cloud Speech-to-Text users to prioritize upcoming activities.
To know more about this update in detail visit Google’s blog post.